Java集合(List,Set,Map)
一、List
ArrayList********
1 语法特点
- 1、内部基于数组实现的一个集合类。查询比较快,添加和删除相对比较慢
- 2、猜ArrayList中会有哪些功能(方法): 添加、删除、查询、插入、修改。。。
- 3、不是同步的(存在线程安全问题),如何解决:敬请期待… 用Vector
2 基本使用
参考api一个一个写
1 三个构造函数
2 增删改查
3 数组和List相互转化
4.3 遍历方式
1、使用普通的for循环
ArrayList bag = new ArrayList();
bag.add(“电脑”);
bag.add(200);
bag.add(“鼠标”);
bag.add(“小人书”);
bag.add(“教材”);
bag.add(“牛奶”);
for(int i=0;i2、增强for循环(foreach)
语法:
for(源中的数据类型 变量名 : 源){
}
注意:源可以是数组或者集合(Iterable的实例)
3、使用迭代器进行遍历
Iterator 就是一个迭代器(也是一个接口)
其中的方法如下:
boolean hasNext() 判断是否有下一个元素,如果返回true表示有下一个;
Object next() 调用一次获得一个元素(每调用一次指针会向后移动一个);
void remove() 会从迭代器指向的结合容器中删除一个元素
代码:
ArrayList bag = new ArrayList();
bag.add(“电脑”);
bag.add(200);
bag.add(“鼠标”);
bag.add(“小人书”);
bag.add(“教材”);
bag.add(“牛奶”);
//使用迭代器遍历集合ArrayList bag
// 获得一个迭代器
Iterator it = bag.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
一个一个next
多次迭代
遍迭代遍删除-两个错误演示
结果:只遍历了一次,为什么?
原因:上面两个while使用的是同一个迭代器,第一个while循环完毕就把指针移动到末尾了,所以第二个while不会执行了
4、双向迭代器
Iterator 单向的迭代器接口,从左到右依次获得数据,判断是否有下一个;获得下一个
|-- ListIterator 双向的迭代器接口,它的主要方法如下:
Iterator中有的它也有;
boolean hasPrevious() 判断是否有上一个;
Object previous() 获得上一个元素;
代码清单:
ArrayList bag = new ArrayList();
bag.add("电脑");
bag.add(200);
bag.add("鼠标");
bag.add("小人书");
bag.add("教材");
bag.add("牛奶");
// 获得双向的迭代器
ListIterator iterator = bag.listIterator();
while(iterator.hasNext()){
System.out.println(iterator.next());
}
System.out.println("------------------------------------------");
while(iterator.hasPrevious()){
System.out.println(iterator.previous());
}
5.LinkedList
5.1 语法特点
1、 内部是基于双向链表结构实现的。添加和删除比较快,查询相对ArrayList比较慢
2、 内部相对于ArrayList而言多了一些操作头和尾的方法
3、 可以充当队列,堆栈
4、 不是线程安全的(同步的)
总结:LinkedList底层是基于双向链表容器类,添加和删除比较快。查找和修改较慢。
5.2 基本使用
应用示例
crud
package cn.itsource._04_crud;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class EmployeeService {
//集合-运行过程中有且只有一个
private static List employees = new ArrayList<>();
//添加员工
public void add(Employee employee) {
//判断是否已经存在 id相同就存在
if(getById(employee.getId())!=null){
System.out.println("!已经存在");
return;
}
employees.add(employee);
}
//获取所有员工
public List list() {
return employees;
}
//获取特定员工-id
public Employee getById(Long id) {
Iterator iterator = employees.iterator();
while(iterator.hasNext()){
Employee employee = (Employee) iterator.next();
//不能==,是否是同一个对象比较内存地址
//== 数字类型就是比较值
if (id.equals(employee.getId())) {
return employee;
}
}
return null;
}
//删除特定员工
public void deleteById(Long id) {
Iterator iterator = employees.iterator();
while (iterator.hasNext()) {
Employee employee = (Employee) iterator.next();
if (id.equals(employee.getId())) {
//删除
iterator.remove();
return;
}
}
}
//修改特定员工
public void update(Employee employee) {//employee里面id表示修改哪个员工
for (int i = 0; i < employees.size(); i++) {
Employee employeeTmp = (Employee) employees.get(i);
if (employee.getId().equals(employeeTmp.getId())) {
employees.set(i, employee);
return;
}
}
}
}
二**、HashSet**
语法特点:不重复,无序(不保证和添加顺序一致)
1、不能够添加重复元素
2、初体验
可以添加案例:测试不重复和有序。
3.2 是否重复判断规则
3.2.1 引入
通过一步步测试发现:我们不同HashSet内部到底是如何判断重复的?
3.2.2判断重复的方式
① 通过添加进去的元素的hashCode+eqauls 两者进行比较
② 如果两个对象的hashCode相等 并且 两个对象调用equals结果是true 才认为两个元素重复
③ 示意图
3.2.3验证上面的规则
1 打印上面示例中的元素的hashCode和equals的结果
2 尝试自定义类,覆写hashCode 和 equals 这两个方法中的代码随便写
3.2.4 解读Integer规则
查看hashcode和equals方法源码
3.2.5实际开发情况分析(重点)
1、从上面的示例来看,结果两个都添加进去了,原因:hashCode不等,equals为false
2、从业务上来看(需要向源码时代学生管理系统中添加两个学生信息),觉得这两天数据是同一个人
3、应该怎么做: 在Student中覆写hashCode 和equals方法
4、怎么覆写?
覆写的时候应该参考实际业务中的比较规则,例如姓名,年龄等(还得看Student类中有哪些字段,并且这些字段是业务人员判断的标准)
自动生成:
4.TreeSet
4.1 语法特点
无序:不保证(不记录)我们的添加顺序;但是可以保证添加里面元素是有序的。
public static void main(String[] args) {
Set set = new HashSet();
set.add(“catepillar”);
set.add(“momor”);
set.add(“bush”);
set.add(“cateprillar”);
System.out.println(set);
}
不重复:不能够添加重复元素(多个心眼)如何判断重复的呢?
4.2 简单体验
体验1
结果: 虽然打印结果的顺序和添加顺序可能不一致,但是感觉结果是有某种规则排序的
说明String类也实现了Comparable接口,String对象可以调用compareTo方法
体验2
结果:居然不能够放不同的类型,但是编译没有错
体验3: 添加自定义的类的对象 Student对象
结果:
疑问1:上面的代码添加的都是同种类型的数据,为什么还报错;
疑问2:为什么提示要把Student转成Comparable
正常情况 ----》 TreeSet 或者 Comparable的文档
4.3 TreeSet的结构(存储原理)分析
4.4 自然排序与定制排序(比较器)
4.4.1 自然排序 Comparable
从TreeSet的API文档中点击 “自然排序” —》 Comparable接口中
文档中的描述:
此接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的 compareTo 方法被称为它的自然比较方法
理解:
如果一个类实现了Comparable接口,可以认为这个类的对象具有自然排序的能力(本质就是这个对象可以调用比较的方法compareTo),这种比较和排序的规则就是自然排序
4.4.2 定制排序(比较器)Comparator
1、根据上面的分析,如果我们的对象没有实现Comparable接口,感觉就无法添加到TreeSet中去;(这些对象就没有自然排序的能力);
2、上面的示例设计有点问题:Student类中覆写的compareTo方法按照年龄从小到大排列的,万一有的人也是用我们的Student,希望年龄从大到小进行排列,怎么办?
不管Student里面使用何种规则都不能满足所有的人
3、解决办法: 可以给TreeSet单独的提供一个比较器(理解为比较的一个工具)
4、Comparator 是一个比较器的接口(标准),必须得有进行比较的方法 :compare(Object o1,Object o2);
自定义一个类实现Comparator接口,其中写比较规则 —》 比较器的模板
我们现在需要的是一个具体的比较器对象
4.5 判断重复的标准
1、如果采用的是自然排序调用对象的compareTo方法,如果返回0 表示相等;
2、如果使用的定制排序(比较器),调用比较器的方法compare 返回0 表示相等;
ss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L1JpY2FyZG9fTV9aaG91,size_16,color_FFFFFF,t_70)

三、Map
接口 Map:将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
简单理解成是映射; 什么是映射?类似于
1.1 Map引入
示例:添加数据,把各位的qq号码和密码统一保存到一个集合容器中,使用哪种方式存储比较好。
分析: 选择ArrayList,还是LinkedList 哪个好呢?
下面有6个数据,放到ArrayList里面容器比较容易,但是取出来,是不是不方便;
感觉这六个数据都是配套使用的. 他们是一个整体,像这样的结构选择什么样存储,使用
Map,注意Map不是地图的意思;
key-唯一不重复
比如 qq账号, 密码
624029037 123456
624029038 123456
624029039 123456
ArrayList :
1.2 Map介绍
- Map :将键映射到值的对象。一个映射不能包含重复的键;每个键最多只能映射到一个值。
- 现在需要创建一个Map对象,装里面的数据,但是发现Map是接口,应该怎么创建对象?
- 使用实现类 HashMap 创建对象;
HashMap简单使用:
从定义上看 Map是不能有重复的键,练习使用一下:
1.3 put方法
put(K key, V value) 在此映射中关联指定值与指定键。
put方法特点:
-
如果key不存在,直接添加进去
-
如果key相同,value值使用最新的值替换key对应的老值.
put方法会返回 对应key对应的老值 -
Map方法和存储结构
2.1 Map方法介绍
现在我们对于Map的初步使用,是能够放一对一对的键值对;刚才使用到put方法,看一下
其他的方法:
boolean containsKey(Object key) 如果此映射包含对于指定键的映射关系,则返回 true。
boolean containsValue(Object value) 如果此映射将一个或多个键映射到指定值,则返回 true。
get(Object key) 返回指定键所映射的值。(通过键得到值)
只有通过键拿值,但是为什么没有通过值得到键呢?
因为键是唯一的,通过键可以找到唯一值,而值不是唯一,通过值,可能找到多个键,
如果需要这样的方法,应该返回数组或者集合。
get方法练习使用:
putAll(Map m) 将指定映射的所有映射关系复制到此映射中,这些映射关系将替换此映射目前针对指定映射中所有键的所有映射关系。(相当于Collection下面的addAll,把另外一个Map放到当前Map的容器里面)
remove(Object key) 从此映射中移除指定键的映射关系(通过key ,找到value,然后把一对键和值都删掉)。
2.2 Map特点
现在只是使用了一下HashMap,介绍了HashMap的方法,并没有说明HashMap的特点,它有什么特点呢?
Map特点:
一个Map对象中不能有重复的键。
Map怎么判断重复?
通过put方法,put一次的时候,就是放两个参数,一个key,一个value,put方法相等于添加方法,在put的时候,判断当前放的这对(key-value)是否和里面已经存在的对(key-value) 是否已经重复, 只是在put的时候,放了两个参数,一个key和value,它判断重复,使用哪个参数?
使用key作为判断重复的标准.只拿key 和已经存在的一对一对key进行比较;就少拿了一个value而已;这个原理和HashSet,TreeSet一样。设计Map的时候,并没有说具体按照什么进行判断重复,而是通过实现类进行判断;
示例:
看下面代码是否能编译通过?
Map map = new HashMap();
map.put(new A(),123);
TreeMap m = new TreeMap();
m.put(new A(),45);
报错信息:
那把字符串作为key放进去编译能通过不?
m.put(“sdfa”,45);
Map接口
|—HashMap 判断重复的标准和HashSet一致,通过键的hashcode和equals;
|—TreeMap 判断重复的标准和TreeSet一致,1通过自然排序(Comparable接口),2定制排序(Compartor比较器)
这就是HashMap,TreeMap的特点;
2.3 Map存储方式
现在分析一下:Map在存储的时候的使用什么存储方式?
在Map使用的时候,添加一对值使用put方法,那在Map里面是怎么存储的?
它和我们在设计链表结构linkedList非常相像。基于链表结构封装成容器类,那我们是怎样存储的?
把值封装成一个对象,并且里面有其他字段。
Map的存储原理也是类似:利用封装的,如果要封装,首先有个类型,这个类型是Entry,
Entry类型作用:Entry用来封装用户添加的一对数据.Entry类型有两个字段,添加的时候,使用Entry把两个值封装成一个对象,然后放到Map容器里面。对于Map而言,看到的只有Entry对象。
由于Entry的存在,只是对于Map来讲才有意义. 因此它使用封装,把Entry类型设计到Map里面。相当于内部类。
Map 里面的方法:
entrySet() 返回Set,(返回当前Map中所有的entry对象,使用Set存储起来。)
keySet() 返回Map当中所有的key,存储到一个Set集合当中。
values() 返回所有的values,存储到一个Collection。
get(Object key) 返回Collection,通过key查找对应的值。
这里get方法为什么返回Collection?
因为values 有重复,如果返回Set,就不能含有重复的元素.
3. Map两种遍历方式
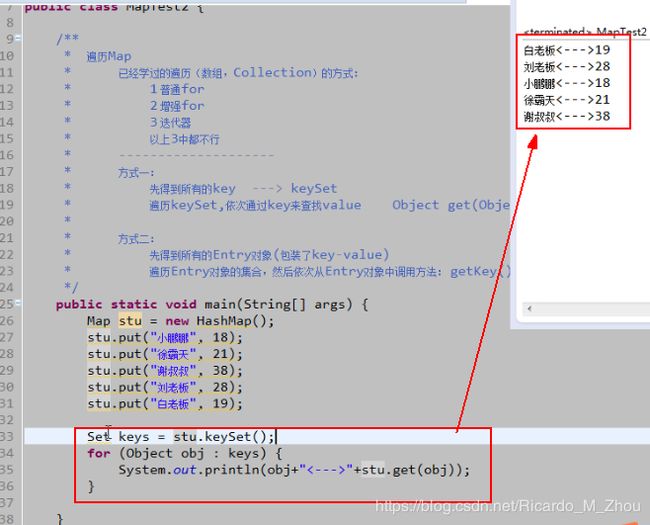
3.1 遍历Map 之 keyset方式
KeySet方式:
①先得到所有key, 通过keySet方法取到;
②然后遍历keySet,依次通过key来查找value。
通过Object get(Object key)方法;
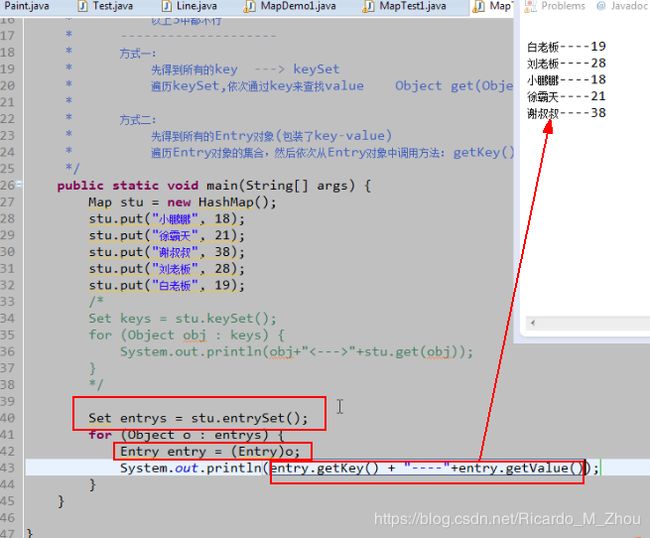
3.2 遍历Map 之 Entry对象方式
Entry对象方式:
①先得到所有的Entry对象,Entry对象就包装了key,values;
②遍历Entry对象的集合,然后依次从Entry对象中调用方法:getKey(),getValue()
4. Map 应用
Map使用示例:
有如下字符串,String str = “ aaaabbbyyyccc’;
①统计出str中每一个字符的个数
比如 a - 4
b - 3
②找出并打印,次数最多的字符和次数
分析①:
使用Map进行存储 ,
字符 - key
次数 - value
遍历字符串(依次取得每一个字符)。一边取一边放在Map中,在存放前应该先判
断当前的Map容器中是否存在当前得到的这个字符。
如果没有,那么说明是第一次 应put(ele,1);
如果有,以当前的字符作为key从Map中取出对应的value,在+1 ----》新的value值 put(ele,新value);
如下代码:
②找出并打印,次数最多的字符和次数{b = 3,c=3,a=4,y=3}
相当于找出一个Map中value值最大的那一组.
找到最大的value值;根据先得到的所有value,然后自己遍历比较
找最大值方式一:
找最大值方式二:
调用Collection中的toArray方法,把Collection 转换成数组,然后调用Arrays中的工具方法sort求出;(val.toArray()方法和Arrays.sort(数组对象)方法)
找最大值方式三:
直接调用Collection里面的max方法
最大值得到之后,根据最大值找到key,通过value找到key,只有遍历Map一个一个进行比较;
[6.avi]
- Collections工具类
通过刚才的示例,使用到了Collections, 那Collections里面都有什么内容?
addAll(Collection c, T… elements)将所有指定元素添加到指定 collection 中。
copy(List dest, List src) 将所有元素从一个列表复制到另一个列表
shuffle(List list) 使用默认随机源对指定列表进行置换
fill(List list, T obj) 使用指定元素替换指定列表中的所有元素。
max(Collection coll) 根据元素的自然顺序,返回给定 collection 的最大元素。
max(Collection coll, Comparator comp) 根据指定比较器产生的顺序,返回给定 collection 的最大元素。
min(Collection coll) 根据元素的自然顺序 返回给定 collection 的最小元素。
min(Collection coll, Comparator comp) 根据指定比较器产生的顺序,返回给定 collection 的最小元素。
sort(List list) 根据元素的自然顺序 对指定列表按升序进行排序。
sort(List list, Comparator c)根据指定比较器产生的顺序对指定列表进行排序。
synchronizedList(List list) 返回指定列表支持的同步(线程安全的)列表。