决胜Hadoop&Spark大数据时代:Hadoop&Yarn&Spark企业级最佳实践
王家林:Spark、Docker、Android技术中国区布道师。
电话:18610086859
QQ:1740415547
微信号:18610086859
Hadoop、Yarn、Spark是企业构建生产环境下大数据中心的关键技术,也是大数据处理的核心技术,是每个云计算大数据工程师必修课。
大数据时代的精髓技术在于Hadoop、Yarn、Spark,是大数据时代公司和个人必须掌握和使用的核心内容。
Hadoop、Yarn、Spark是Yahoo!、阿里淘宝等公司公认的大数据时代的三大核心技术,是大数据处理的灵魂,是云计算大数据时代的技术命脉之所在,以Hadoop、Yarn、Spark为基石构建起来云计算大数据中心广泛运行于Yahoo!、阿里淘宝、腾讯、百度、Sohu、华为、优酷土豆、亚马逊等公司的生产环境中。
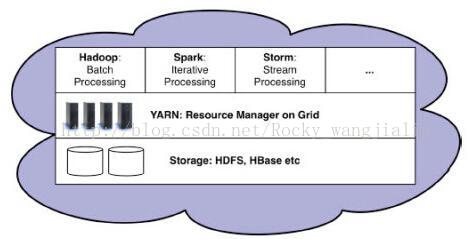
Hadoop、Yarn、Spark三者相辅相成
n Hadoop中的HDFS是大数据时代公认的首选数据存储方式;
n Yarn是目前公认的最佳的分布式集群资源管理框架;
n Spark是目前公认的大数据统一计算平台;
工业和信息化部电信研究院于2014年5月发布的“大数据白皮书”中指出:
“2012 年美国联邦政府就在全球率先推出“大数据行动计划(Big data initiative)”,重点在基础技术研究和公共部门应用上加大投入。在该计划支持下,加州大学伯克利分校开发了完整的大数据开源软件平台“伯克利数据分析软件栈(Berkeley Data Analytics Stack),其中的内存计算软件Spark的性能比Hadoop 提高近百倍,对产业界大数据技术走向产生巨大影响”
----来源:工业和信息化部电信研究院
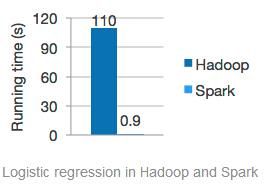
Spark是继Hadoop之后,成为替代Hadoop的下一代云计算大数据核心技术。目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、Interactive Ad-Hoc Query等方面都有自己的技术,并且是Apache顶级Project,可以预计的是2014年下半年到2015年在社区和商业应用上会有爆发式的增长。

国外一些大型互联网公司已经部署了Spark。甚至连Hadoop的早期主要贡献者Yahoo现在也在多个项目中部署使用Spark;国内的淘宝、优酷土豆、网易、Baidu、腾讯、皮皮网等已经使用Spark技术用于自己的商业生产系统中,国内外的应用开始越来越广泛。Spark正在逐渐走向成熟,并在这个领域扮演更加重要的角色。
刚刚结束的2014 Spark Summit上的信息,Spark已经获得世界20家顶级公司的支持,这些公司中包括Intel、IBM等,同时更重要的是包括了最大的四个Hadoop发行商(Cloudera, Pivotal, MapR, Hortonworks)都提供了对非常强有力的支持Spark的支持,尤其是是Hadoop的头号发行商Cloudera在2014年7月份宣布“Impala’s it for interactive SQL on Hadoop; everything else will move to Spark”,具体链接信息 http://t.cn/Rvdsukb ,而其实在这次Spark Summit之前,整个云计算大数据就已经发声巨变:
1,2014年5月24日Pivotal宣布了会把整个Spark stack包装在Pivotal HD Hadoop发行版里面。这意味这最大的四个Hadoop发行商(Cloudera, Pivotal, MapR, Hortonworks)都提供了对Spark的支持。http://t.cn/RvLF7aM 星火燎原的开始;
2,Mahout前一阶段表示从现在起他们将不再接受任何形式的以MapReduce形式实现的算法,另外一方面,Mahout宣布新的算法基于Spark;
3,Cloudera的机器学习框架Oryx的执行引擎也将由Hadoop的MapReduce替换成Spark;
4,Google已经开始将负载从MapReduce转移到Pregel和Dremel上;
5,FaceBook则将原来使用Hadoop的负载转移到Presto上;
现在很多原来使用深度使用Hadoop的公司都在纷纷转向Spark,国内的淘宝是典型的案例,国外的典型是Yahoo!,我们以使用世界上使用Hadoop最典型的公司Yahoo!为例,大家可以从Yahoo!的数据处理的架构图看出Yahoo!内部正在使用Spark:
不得不提的是Spark的“One stack to rule them all”的特性,Spark的特点之一就是用一个技术堆栈解决云计算大数据中流处理、图技术、机器学习、交互式查询、误差查询等所有的问题,此时我们只需要一个技术团队通过Spark就可以搞定一切问题,而如果基于Hadoop就需要分别构建实时流处理团队、数据统计分析团队、数据挖掘团队等,而且这些团队之间无论是代码还是经验都不可相互借鉴,会形成巨大的成本,而使用Spark就不存在这个问题;
伴随Spark技术的普及推广,对专业人才的需求日益增加。Spark专业人才在未来也是炙手可热,作为Spark人员,需要掌握的技能模型如下:

Hadoop领域4个开创先河
1,全程覆盖Hadoop的所有核心内容
2,全程注重动手实作,循序渐进中掌握Hadoop企业级实战技术
4,具备掌握Hadoop完整项目的分析、开发、部署的全过程的能力
Spark领域开创6个世界第一:
1, 这是世界上第一个全程覆盖以Spark为核心的大数据的所有内容的课程:包含Scala、Spark、Spark与Hadoop的结合、企业生产环境下的商业案例、框架源码剖析等;
2, 这是世界上第一个Spark大数据零基础课程:学习此课程不需要任何基础,所有的内容在课程中都会细致的剖析,学员不需要额外学习任何内容,从零基础到直到进入企业工作;
3, 这是世界上第一个全程注重动手实作的大数据课程:通过不断的案例实践的循序渐进中掌握Spark企业级实战技术;
4, 这是世界上第一个彻底而系统的讲解Spark 1.0的课程:根据Spark的最新稳定版本,包括Spark集群的构建,Spark架构设计、Spark内核剖析、Shark、Spark SQL、Spark Streaming、图计算GraphX、机器学习、Spark on Yarn、JobServer等;
5, 这是世界上第一个使用Spark商业案例教学的课程:展示企业线上生产系统中应用 Spark的成功案例,以及与现有企业BI平台整合的方案 ;
6, 这是世界上第一个讲解Spark与Hadoop完美结合的课程:目前而言,在世界的生产环境中往往是Spark和Hadoop并存,如何驾驭这种并存架构,在课程中给出了完美的解答,尤其是通过企业案例讲解,以达到最优化使用大数据系统潜能的目的;
王家林老师(邮箱[email protected] 电话18610086859 QQ:1740415547)
中国目前唯一的移动互联网和云计算大数据集大成者;
云计算大数据Spark亚太研究院院长和首席专家;
Spark亚太研究院院长和首席专家,Spark源码级专家,对Spark潜心研究(2012年1月起)2年多后,在完成了对Spark的14不同版本的源码的彻底研究的同时不断在实际环境中使用Spark的各种特性的基础之上,编写了世界上第一本系统性的Spark书籍并开设了世界上第一个系统性的Spark课程并开设了世界上第一个Spark高端课程(涵盖Spark内核剖析、源码解读、性能优化和商业案例剖析)。Spark源码研究狂热爱好者,醉心于Spark的新型大数据处理模式改造和应用。
Hadoop源码级专家,曾负责某知名公司的类Hadoop框架开发工作,专注于Hadoop一站式解决方案的提供,同时也是云计算分布式大数据处理的最早实践者之一,Hadoop的狂热爱好者,不断的在实践中用Hadoop解决不同领域的大数据的高效处理和存储,现在正负责Hadoop在搜索引擎中的研发等,著有《云计算分布式大数据Hadoop实战高手之路---从零开始》《云计算分布式大数据Hadoop实战高手之路---高手崛起》《云计算分布式大数据Hadoop。实战高手之路---高手之巅》等;
Android架构师、高级工程师、咨询顾问、培训专家;
通晓Android、HTML5、Hadoop,迷恋英语播音和健美;
致力于Android、HTML5、Hadoop的软、硬、云整合的一站式解决方案;
国内最早(2007年)从事于Android系统移植、软硬整合、框架修改、应用程序软件开发以及Android系统测试和应用软件测试的技术专家和技术创业人员之一。
HTML5技术领域的最早实践者(2009年)之一,成功为多个机构实现多款自定义HTML5浏览器,参与某知名的HTML5浏览器研发;
超过10本的IT畅销书作者;
致力于HTML5和Android的软、硬、云整合,智慧家庭,智能城市,精通Android安全,精通企业级Android应用开发实战,对Android的HAL与AF框架的原理、IoC、设计模式有深刻独特的理解,精通C/C++组件通过JNI调用移植成为Android应用框架的核心组件,擅长修改应用框架。精通JPA、Struts、Spring、MySQL, 熟练LAMP技术。2010年10月份至今为多家企业提供Android技术咨询服务及企业内部培训。 一直关注HTML5的发展动态和技术实现,擅长HTML5的Web开发、HTML5的游戏开发、HTML5和本地的软硬整合高级技术、HTML5与云计算。 成功对包括三星、摩托罗拉、华为等世界500强企业实施Android底层移植、框架修改、应用开发等培训。 成功对平安保险、英特尔等实施HTML5培训; 撰写了《大话企业级Android应用开发实战》、《基于Android平台的商业软件---手机守护神开发全程实战》、《Android 4.0网络编程详解》、《细说Android NDK编程》、《Android软、硬、云整合实战》、《Android开发三剑客——UML、模式与测试》等多部Android著作和《云计算分布式大数据Hadoop实战高手之路---从零开始》《云计算分布式大数据Hadoop实战高手之路---高手崛起》《云计算分布式大数据Hadoop。实战高手之路---高手之巅》等。 项目案例包括Android移植工作、Android上特定硬件的垂直整合、编写Java虚拟机、Android框架修改、Android手机卫士、Android娱乐多媒体软件(针对酷六、优酷、土豆等类型的网站)、大型B2C电子商务网站、大型SNS网站等。
| Total Hadoop Professional |
|
| 培训对象 |
1,对云计算、分布式数据存储于处理、大数据等感兴趣的朋友 2,传统的数据库,例如Oracle、MaySQL、DB2等的管理人员 3,Java、C等任意一门编程语言的开发者; 4,网站服务器端的开发人员 5,在校大学生、中专生或者刚毕业的学生 6,云计算大数据从业者; 7,熟悉Hadoop生态系统,想了解和学习Hadoop与Spark整合在企业应用实战案例的朋友; 8,系统架构师、系统分析师、高级程序员、资深开发人员; 9,牵涉到大数据处理的数据中心运行、规划、设计负责人; 10,政府机关,金融保险、移动和互联网等大数据来源单位的负责人; 11,高校、科研院所涉及到大数据与分布式数据处理的项目负责人; 12,数据仓库管理人员、建模人员,分析和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员; |
| 参加课程基础要求 |
对云计算有强烈的兴趣,能够看懂基本的Java语法。 |
| 培训后的目标能力 |
直接上手Hadoop工作,具备直接胜任Hadoop开发工程师的能力;轻松驾驭以Spark为核心的云计算大数据实战技术,从容解决95%以上的云计算大数据业务需求; |
| 培训技能目标 |
• 彻底理解Hadoop 代表的云计算实现技术的能力 • 具备开发自己网盘的能力 • 具备修改HDFS具体源码实现的能力 • • 掌握Spark的企业级开发的所有核心内容,包括Spark集群的构建,Spark架构设计、Spark内核剖析、Shark、Spark SQL、Spark Streaming、图计算GraphX、机器学习等; • 掌握Spark和Hadoop协同工作,能够通过Spark和Hadoop轻松应对大数据的业务需求; • 掌握企业线上生产系统中应用Spark /Hadoop成功案例,以及与现有企业BI平台整合的方案; |
| 培训职业目标 |
• Hadoop工程师,能够开发的Hadoop分布式应用 • Hadoop完整项目的分析、开发、部署的全过程的能力 • Spark高级工程师 • 大数据项目总负责人 • 云计算大数据CTO |
培训内容
| 时间 |
内容 |
备注 |
| 第一天 |
第1个主题:Hadoop三问(彻底理解Hadoop) 1、 Hadoop为什么是云计算分布式大数据的事实开源标准软件框架? 2、Hadoop的具体是如何工作? 3、Hadoop的生态架构和每个模块具体的功能是什么?
第2个主题:Hadoop集群与管理(具备构建并驾驭Hadoop集群能力) 1、 Hadoop集群的搭建 2、 Hadoop集群的监控 3、 Hadoop集群的管理 4、 集群下运行MapReduce程序
第3主题:彻底掌握HDFS(具备开发自己网盘的能力) 1、HDFS体系架构剖析 2、NameNode、DataNode、SecondaryNameNode架构 3、保证NodeName高可靠性最佳实践 4、DataNode中Block划分的原理和具体存储方式 5、修改Namenode、DataNode数据存储位置 6、使用CLI操作HDFS 7、使用Java操作HDFS
第4主题:彻底掌握HDFS(具备修改HDFS具体源码实现的能力) 1、RPC架构剖析 2、源码剖析Hadoop构建于RPC之上 3、源码剖析HDFS的RPC实现 4、源码剖析客户端与与NameNode的RPC通信
|
|
| 时间 |
内容 |
备注 |
|
第二天 |
第1个主题:彻底掌握MapReduce(从代码的角度剖析MapReduce执行的具体过程并具备开发MapReduce代码的能力) 1、MapReduce执行的经典步骤 2、wordcount运行过程解析 3、Mapper和Reducer剖析 4、自定义Writable 5、新旧API的区别以及如何使用就API 6、把MapReduce程序打包成Jar包并在命令行运行
第2个主题:彻底掌握MapReduce(具备掌握Hadoop如何把HDFS文件转化为Key-Value让供Map调用的能力) 1、 Hadoop是如何把HDFS文件转化为键值对的? 2、 源码剖析Hadoop读取HDFS文件并转化为键值对的过程实现 3、 源码剖析转化为键值对后供Map调用的过程实现
第3个主题:彻底掌握MapReduce(具备掌握MapReduce内部运行和实现细节并改造MapReduce的能力) 1、 Hadoop内置计数器及如何自定义计数器 2、 Combiner具体的作用和使用以及其使用的限制条件 3、 Partitioner的使用最佳实践 4、 Hadoop内置的排序算法剖析 5、 自定义排序算法 6、 Hadoop内置的分组算法 7、 自定义分组算法 8、 MapReduce常见场景和算法实现
第4个主题:某知名电商公司Hadoop实施全程揭秘(具备掌握商业级别Hadoop的分析、开发、部署的全过程的能力) 通过电商公司现场案例展示商业级别一个完整项目的分析、开发、部署的全过程 |
|
| 时间 |
内容 |
备注 |
|
第三天
|
第1个主题:YARN(具备理解和使用YARN的能力) 1、YARN的设计思想 2、YARN的核心组件 3、YARN的共组过程 4、YARN应用程序编写
第2个主题:ResourceManager深度剖析(具备深刻理解ResourceManager的能力) 1、ResourceManager的架构 2、ClientRMService 与AdminService 3、NodeManager 4、 Container 5、 Yarn的 HA机制
第3个主题:NodeManager深度剖析(具备掌握NodeManager及Container的能力) 1、 NodeManager架构 2、 Container Management 3、 Container lifecycle 4、 资源管理与隔离
第4堂课:Spark的架构设计(具备掌握Spark架构的能力)
1.1 Spark生态系统剖析 1.2 Spark的架构设计剖析 1.3 RDD计算流程解析 1.4 Spark的出色容错机制 |
|
| 时间 |
内容 |
备注 |
|
第四天
|
第1堂课:深入Spark内核 1 Spark集群 2 任务调度 3 DAGScheduler 4 TaskScheduler 5 Task内部揭秘
第2堂课:Spark SQL 1 Parquet支持 2 DSL 3 SQL on RDD
第3堂课:Spark的机器学习 1 LinearRegression 2 K-Means 3 Collaborative Filtering
第4堂课:Spark的图计算GraphX 1 Table Operators 2 Graph Operators 3 GraphX
|
|