Hive学习(二)-数据导入及导出
首先,要知道HIve中表的列(field)是以何种方式分隔的。
Hive表中默认的记录何字段分割符
| 分隔符 | 描述 |
| \n | 对于文本文件来说,每行都是一条记录,因此换行符可以进行分隔 |
| ^A(Ctrl+A) | 用于分隔字段(列),在create table语句中可以使用八进制编码\001表示 |
| ^B | 用于分隔ARRAY或者struct中的元素,或用于MAP中键-值对之间的分隔。在create table语句中可以使用八进制编码\002表示 |
| ^C | 用于MAC中键何值之间的分隔。在create table语句中可以使用八进制编码\003表示 |
对于常见的文本文件,比如.CSV和.TSV格式的文件,它们分别是以逗号(,)和制表符(\t)进行列分割的。
现在创建一张表:
hive>
create table jc_tunnel (
TUNNEL_ID string comment '隧道ID',
BEGIN_ROAD string comment '起始公里标',
CREATE_BY string comment '创建人',
CREATE_DATETIME string comment '创建时间',
DIRECTION_ID string comment '行别表ID',
END_ROAD string comment '截止公里标',
MEMO string comment '备注信息',
SITE_ID string comment '区间战场',
TUNNEL_NAME string comment '隧道名称',
TUNNEL_NO string comment '隧道编号',
UPDATE_BY string comment '更新人',
UPDATE_DATETIME string comment '更新时间',
ORDER_NUM string comment '排序号'
)
comment '隧道表'
row format delimited
fields terminated by ',';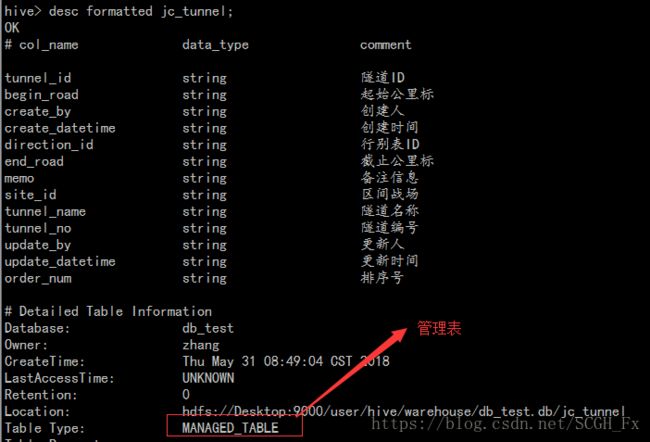
该表以逗号进行列分隔。
一.数据导入
1.从文件导入
现在上传数据到MAC1SN中。数据在文件jc_tunnel.csv中,该文件在本地文件系统的用户主目录(~)下面。
执行命令:load data local inpath 'jc_tunnel.csv' into table jc_tunnel;
这里加了local关键字,表示是从本地文件系统中选择文件上传;如果不加local,表示是从分布式文件系统中选择文件上传

可以看到数据已经上传成功了。
然后查看一下文件上传的地方:

这个时候,jc_tunnel.csv是作为表jc_tunnel的数据存在的,因此位于表目录的下面,当然也可以查看该数据。
执行命令:hive> dfs -cat /user/hive/warehouse/db_test.db/jc_tunnel/jc_tunnel.csv;

与原始文件的内容一致:

再从表中查询:

2.查询导入
先创建一张新表(jc_tunnel_new),结构和jc_tunnel一样。
hive> create table jc_tunnel_new like jc_tunnel;
现在将从jc_tunnel查询到的数据导入到jc_tunnel_new:
hive> insert into jc_tunnel_new select * from jc_tunnel limit 0,3;

查看导入结果:

3.查询创建表并加载数据
hive> create table jc_tunnel_new_s as select * from jc_tunnel limit 0,4;

4.分区表导入
先将之前创建的jc_tunnel,jc_tunnel,jc_tunnel_s表删除。
创建一张分区表
create table jc_tunnel (
TUNNEL_ID string comment '隧道ID',
BEGIN_ROAD string comment '起始公里标',
CREATE_BY string comment '创建人',
CREATE_DATETIME string comment '创建时间',
DIRECTION_ID string comment '行别表ID',
END_ROAD string comment '截止公里标',
MEMO string comment '备注信息',
SITE_ID string comment '区间战场',
TUNNEL_NAME string comment '隧道名称',
TUNNEL_NO string comment '隧道编号',
UPDATE_BY string comment '更新人',
UPDATE_DATETIME string comment '更新时间',
ORDER_NUM string comment '排序号'
)
comment '隧道表'
partitioned by (area string comment '地区')
row format delimited
fields terminated by ',';注意:创建分区表时,partitioned一定要写在row等关键字的最前面。comment要写在partitioned前面。Hive的表分区实际上就是一个目录,且分区字段不能与表的字段重复。
导入数据:hive> load data local inpath '/home/zhang/jc_tunnel.csv' into table jc_tunnel partition ( area = 'GZ' );

导入数据时,分区名称不能有中文字符。
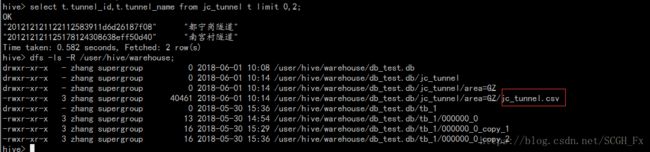
可以看到,刚刚上传的文件是存在分区目录下的。
二.数据导出
将查询的结果导出到目标文件中:
方法1:
zhang@Desktop:~$ hive -S -e 'select t.tunnel_id,t.tunnel_name from db_test.jc_tunnel t limit 0,2' > query.txt

其中的-e命令表示命令执行结束后hive CLI立即退出;-S命令可以开启静默模式,这样在输出结果中去掉“OK”,“Time taken”等行以及其他一些无关紧要的东西。
方法2:
hive> insert overwrite local directory '/home/zhang/query' select t.tunnel_id,t.tunnel_name from db_test.jc_tunnel t limit 0,2;//将查询结果导入数据到本地的query文件夹中
导入完成后,查看目录。
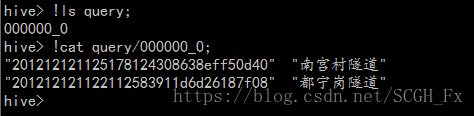
如果导入时不加入local关键字,则是导入到hdfs中。可以使用"dfs -cat 导入目录"查看导入结果。
方法3:
使用命令:
hive>export table jc_tunnel to '/user/zhang/export';
该命令是将表导出到分布式文件系统中,且导出的是表的结构与数据。

