Hadoop实战学习(3)-读取数据库内容
要读取数据库中的数据,首先需要实现一个实体类,这个实体类部分映射数据库中要查询的表的字段。且该实体类需要实
现Writable与DBWritable两个接口,DBWritable的实现类负责查询与写入,Writable的实现类负责序列化输出(到Mapper)与写入。
可以将两个接口的实现都写入到一个类。
开发环境:mysql-5.7,Hadoop-2.7.3集群,Idea(Linux版),ubuntu。
开发测试都是在Linux环境下执行的。
SQL语句及数据准备:
CREATE DATABASE BigData DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
use BigData;
CREATE TABLE author (
id int primary key auto_increment not null ,
name varchar(20) null,
sex char(1) null,
remark varchar(255) null
) DEFAULT CHARSET=utf8;
insert into author(name,sex,remark) values ('李三','0','Hello 李三');
insert into author(name,sex,remark) values ('李芳','1','Hello 李芳');
insert into author(name,sex,remark) values ('张燕','1','Hello 张燕');
insert into author(name,sex,remark) values ('王5','0','Hello 王5');
insert into author(name,sex,remark) values ('李四','0','How are you 李四');
insert into author(name,sex,remark) values ('李7','0','Hello 李7');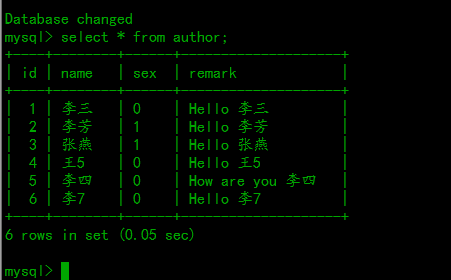
代码:
Writable及DBWritable接口实现类。
package com.readdb;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.mapreduce.lib.db.DBWritable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* 该类在Mapper前执行
*/
public class MyDBWriteable implements DBWritable,Writable {
private String name,sex,remark;
private int id;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getRemark() {
return remark;
}
public void setRemark(String remark) {
this.remark = remark;
}
/**
* 序列化输出对象字段,将查询结果作为mapper的输入
* 即将查询结果写入到Mapper的输入数据
* @param dataOutput
* @throws IOException
*/
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeInt(id);
dataOutput.writeUTF(sex);
dataOutput.writeUTF(name);
dataOutput.writeUTF(remark);
}
/**
* 读取向数据库写入输入字段,读取数据时可以不实现该方法
* @param dataInput
* @throws IOException
*/
public void readFields(DataInput dataInput) throws IOException {
//id=dataInput.readInt();
//sex=dataInput.readUTF();
//name=dataInput.readUTF();
//remark=dataInput.readUTF();
}
/**
* 向数据库写入数据,只读数据的话该方法可以不写
* @param statement
* @throws SQLException
*/
public void write(PreparedStatement statement) throws SQLException {
//写入顺序要与列顺序一致
//statement.setInt(1,id);
//statement.setString(2,name);
//statement.setString(3,sex);
//statement.setString(4,remark);
}
/**
* 读取查询结果集
* @param resultSet
* @throws SQLException
*/
public void readFields(ResultSet resultSet) throws SQLException {
id=resultSet.getInt(1);
name=resultSet.getString(2);
sex=resultSet.getString(3);
remark=resultSet.getString(4);
}
}
Mapper:
package com.readdb;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import java.util.StringTokenizer;
public class WCMapper extends Mapper {
@Override
protected void map(LongWritable key, MyDBWriteable value, Context context) throws IOException, InterruptedException {
StringTokenizer stringTokenizer=new StringTokenizer(value.getRemark());
while (stringTokenizer.hasMoreTokens()){
context.write(new Text(stringTokenizer.nextToken()),new IntWritable(1));
}
}
}
Reducer:
package com.readdb;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WCReducer extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
int count=0;
for (IntWritable intWritable:values){
count+=intWritable.get();
}
context.write(key,new IntWritable(count));
}
}
作业执行:
package com.readdb;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.db.DBConfiguration;
import org.apache.hadoop.mapreduce.lib.db.DBInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
public class HDFSDemo {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration configuration=new Configuration();
//配置作业
Job job=Job.getInstance(configuration,"readdb");
String[] otherArgs = new GenericOptionsParser(configuration, args).getRemainingArgs();
if (otherArgs.length != 1) {
System.err.println("Usage: wordcount ");
System.exit(2);
}else {
FileSystem.get(configuration).delete(new Path(otherArgs[0]));
}
//配置数据库信息
String driverClass="com.mysql.jdbc.Driver";
String url="jdbc:mysql://127.0.0.1:3306/BigData?useUnicode=true&characterEncoding=utf8&useSSL=false";
String userName="root";
String password="123456";
String querySelect="select * from author";
String queryCount="select count(*) from author";
//配置数据库
DBConfiguration.configureDB(job.getConfiguration(),driverClass,url,userName,password);
//配置Mapper数据输入
DBInputFormat.setInput(job,MyDBWriteable.class,querySelect,queryCount);
//设置搜索类
job.setJarByClass(HDFSDemo.class);
//设置输入格式,TextInputFormat是默认输入格式,不能设置成FileInputFormat.Class,该惨数在当前情况下可以不设置
job.setInputFormatClass(DBInputFormat.class);
//设置Mapper类
job.setMapperClass(WCMapper.class);
//设置Reducer类
job.setReducerClass(WCReducer.class);
//设置Reducer个数
//job.setNumReduceTasks(1);
//设置maper端单词输出格式
job.setMapOutputKeyClass(Text.class);
//设置mapper端单词输出个数格式
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer端单词输出格式
job.setOutputKeyClass(Text.class);
//设置Reducer单词输出个数格式
job.setOutputValueClass(IntWritable.class);
//设置job的输入路径,多次add可以设置多个输入路径
//FileInputFormat.addInputPath(job,new Path(otherArgs[0]));
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(otherArgs[0]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
然后点击Idea菜单栏的Run->Edit Configurations配置参数。
这里只需要配置输出目录。
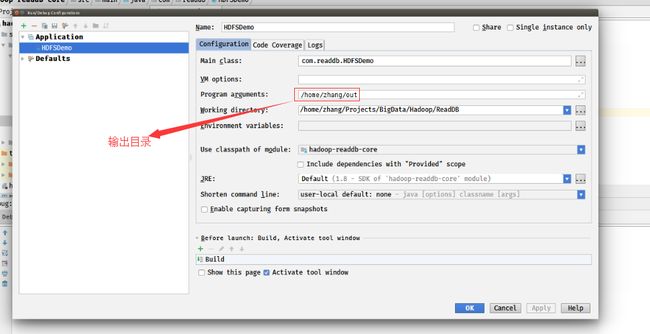
然后编译运行。如果编译通过了,会在用户主目录下产生一个out目录。
![]()
然后执行命令:cat ~/out/* 查看输出结果。

可以看到,hadoop作业输出结果与mysql数据表中的数据完全符合。然后将代码打成jar包,在集群上运行。
打包之前,记得修改代码中的ip地址,我这里配置的是本机地址。改成内网ip后打包。

可以看到已经打成jar包了。然后将jar包移动到用户主目录下。

如果Idea所在的主机就是NameNode,当然也可以直接在IDea中执行jar包。
如果不是,还需要将jar包复制到NameNode上面。
允许jar包之前,还需要拷贝mysql的驱动(mysql-connector-java-5.1.38.jar)到各个节点的${HADOOP_HOME}/share/hadoop/common/lib目录下。也可以拷贝到${HADOOP_HOME}/share/hadoop/hdfs/lib目录下。
然后执行:hadoop jar readdb-core-1.0-SNAPSHOT.jar com.readdb.HDFSDemo /user/zhang/hadoop/out
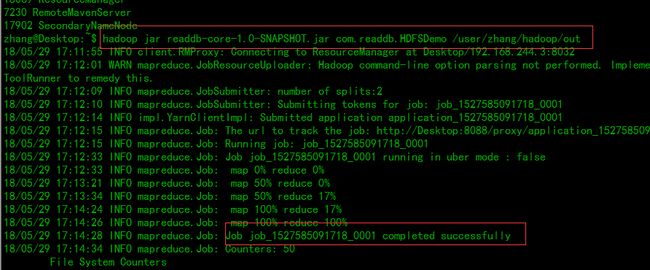
然后查看输出结果:
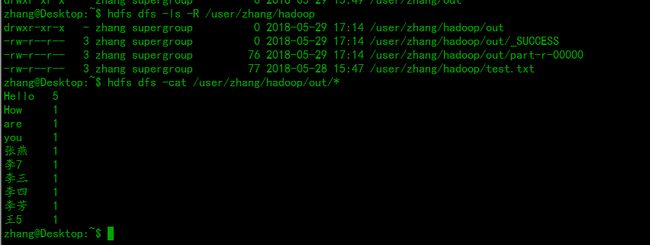
可以看到输出结果和mysql表中的 数据一致。
常见问题解决:
1.提示驱动类找不到是因为没有加载mysql驱动jar包。
2.提示数据库找不到是因为ip地址配置错误,在执行jar包的时候,ip地址不能使用127.0.0.1;
3.无法连接到数据库,数据库访问被拒绝可以点此查看ubuntu无法访问mysql数据库
4.如果重复出现以下情况:

配置historyserver,执行:mr-jobhistory-daemon.sh start historyserver即可解决。
点此下载源代码
源代码下载完成后,先执行SQL语句,然后以导入maven工程的方式导入root目录下的pom.xml,只需要导入这一关pom.xml即可。