Skywalking分析
Skywalking原理分析
Java探针原理
启动方式
在服务的启动命令中添加JVM参数:-javaagent:/path/to/skywalking-agent/skywalking-agent.jar”。
如Tomcat中启动探针的方式为:
Linux Tomcat 7, Tomcat 8环境下,修改 tomcat/bin/catalina.sh,在首行加入如下信息.
CATALINA_OPTS=”$CATALINA_OPTS -javaagent:/path/to/skywalking-agent/skywalking-agent.jar”; export CATALINA_OPTS
工作流程
tomcat环境下,探针工作流程如下:
加载tomcat相关插件jar包->加载插件配置文件->加载配置文件中指定的类->hook目标类。
其插件配置文件及详细日志文件见附件skywalking-plugin.def、skywalking-api-tomcat.log。
javaagent参数
-javaagent:xxx.jar
会在main方法之前预先执行premain方法:
public static void premain(String args, Instrumentation inst)
Agent 类必须打成jar包,然后里面的 META-INF/MAINIFEST.MF 必须包含 Premain-Class这个属性
以下是skywalking-agent.jar的MAINIFEST.MF文件详细内容:
Manifest-Version: 1.0
Implementation-Title: apm-agent
Implementation-Version: 5.0.0-beta2
Built-By: wusheng
Specification-Vendor: The Apache Software Foundation
Specification-Title: apm-agent
Implementation-Vendor-Id: org.apache.skywalking
Implementation-Vendor: The Apache Software Foundation
Premain-Class: org.apache.skywalking.apm.agent.SkyWalkingAgent
Created-By: Apache Maven 3.3.9
Build-Jdk: 1.8.0_91
Specification-Version: 5.0
Implementation-URL: http://maven.apache.org
org.apache.skywalking.apm.agent.SKyWalkingAgent源代码查看以下链接:
https://github.com/apache/incubator-skywalking/blob/master/apm-sniffer/apm-agent/src/main/java/org/apache/skywalking/apm/agent/SkyWalkingAgent.java
采集数据
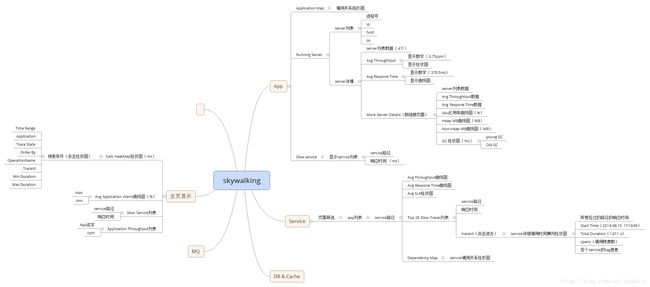
skywalking详细说明
介绍
SkyWalking 创建与2015年,提供分布式追踪功能。他被用于追踪、监控和诊断分布式系统,特别是使用微服务架构,云原生或容积技术。提供以下主要功能:
分布式追踪和上下文传输
应用、实例、服务性能指标分析
根源分析
应用拓扑分析
应用和服务依赖分析
慢服务检测
性能优化
主要特性
多语言探针或类库
Java自动探针,追踪和监控程序时,不需要修改源码。
社区提供的其他多语言探针
.NET Core
Node.js
多种后端存储: ElasticSearch, H2
支持OpenTracing
Java自动探针支持和OpenTracing API协同工作
轻量级、完善功能的后端聚合和分析
现代化Web UI
日志集成
应用、实例和服务的告警
架构
对于APM来说,自动探针和手动探针,只是关于如何实现监控的技术细节。这些和架构设计无关。因此在本文档中,我们将它们仅视为客户端库。
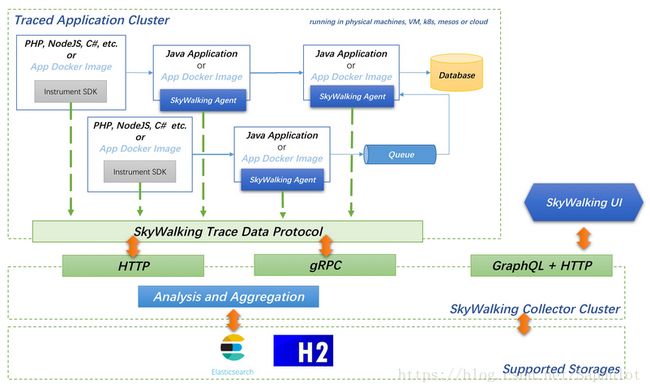
基本原则
SkyWalking架构的基本设计原则包括易于维护、可控和流式处理。
为了实现这些目标,SkyWalking后端采用以下设计。
模块化设计。
多种客户端连接方式。
后端集群服务发现机制。
流模式。
可切换的存储模块。
模块化
SkyWalking后端基于纯模块化设计。用户可以根据自己的需求切换或组装后端功能。
模块
模块定义了一组特性,这些特性可以包括技术库(如:gRPC/Jetty服务器管理)、跟踪分析(如:跟踪段或zipkin span解析器)或聚合特性。 这些完全由模块定义及其模块实现来决定。
每个模块都可以在Java接口中定义它们的服务,每个模块的提供者都必须为这些服务提供实现者。 提供者应该基于自己的实现定义依赖模块。这意味着,即使两个不同的模块实现者,也可以依赖不同的模块。
此外,后端模块化core还检查启动序列,如果没有发现周期依赖或依赖,后端应该被core终止。
后端启动所有模块,这些模块的配置在application.yml中是分离的。在这个yaml文件中:
根级别是模块名称,例如cluster、naming等。
第二级别是模块的实现者的名称,例如zookeeper是cluster等模块。
第三级是实现者的具体属性。例如hostPort和sessionTimeout是zookepper的必需属性。
yaml文件的一部分举例
cluster:
zookeeper:
hostPort: localhost:2181
sessionTimeout: 100000
naming:
jetty:
#OS real network IP(binding required), for agent to find collector cluster
host: localhost
port: 10800
contextPath: /
多种连接方式
首先,后端提供两种类型的连接,也即提供两种协议(HTTP和gRPC):
HTTP中的命名服务,它返回后端群集中的所有可用collector地址。
在gRPC(SkyWalking原生探针的主要部分)和HTTP中使用上行链路服务,它将跟踪和度量数据上传到后端。 每个客户端将只向单个collector发送监视数据(跟踪和度量)。如果与连接的后端在某个时刻断开连接将会尝试连接其它的后端。
比如在SkyWalking Java探针中
collector.servers表示命名服务,将naming/jetty/ip:port映射为HTTP请求地址。
collector.direct_servers 表示直接设置上行服务,并使用gRPC发送监控数据。
客户端库和后端集群之间的流程图
Client lib Collector1 Collector2 Collector3
(Set collector.servers=Collector2) (Collector 1,2,3 constitute the cluster)
|
+———–> naming service —————————->|
|
|<——- receive gRPC IP:Port(s) of Collector 1,2,3—<–|
|
|Select a random gRPC service
|For example collector 3
|
|————————->Uplink gRPC service———————————–>|
Collector 集群发现
当Collector以群集模式运行时,后端必须以某种方式相互发现。默认情况下,SkyWalking使用Zookeeper进行协调,并作为实例发现的注册中心。
通过以上部分(多个连接方式),客户端库将不会使用Zookeeper来查找集群。我们建议客户不要这么做。因为集群发现机制是可切换的,由模块化核心提供。依赖它会破坏可切换能力。 我们希望社区提供更多的实现者来进行集群发现,例如Eureka,Consul,Kubernate等。
流模式
流模式类似轻量级storm/spark的实现,它允许使用API构建流处理图(DAG)以及每个节点的输入/输出数据协定。
新模块可以查找和扩展现有的流程图。
处理中有三种情况
同步过程,传统方法调用。
异步过程,又叫做基于队列缓冲区的批处理。
远程过程,汇总后端的汇总。以这种方式,在节点中定义选择器以决定如何在集群中找到collector。(HashCode,Rolling,ForeverFirst是支持的三种方式)
通过具备的这些功能,collector集群像流式网络一样运行着去聚合、度量标准监控信息,并且不依赖于存储模块的实现来支持并发地编写相同的度量id。
可切换存储实现器
由于流模式负责并发,因此存储模块的实现的职责是提供高速写入和组合查询。
目前,我们支持ElasticSearch作为主要实现模块,H2用于预览版本,以及由Sharding Shpere项目管理的MySQL关系数据库集群。
Web 界面
除了后端设计的原则,UI是SkyWalking的另一个核心组件。它基于React,Antd和Zuul代理实现,提供后端集群发现、查询调度和可视化的功能。
Web UI以多连接方式中的相似的流程机制作为客户端的1.naming、2.uplink。唯一的区别是,在ui/jetty/yaml定义下的主机和端口上(默认值:localhost:12800)用HTTP绑定中的GraphQL查询协议替换上行。
skywalking trace data protocol
Trace Data Protocol是skywalking中描述探针与后端数据通信的数据协议。协议描写了探针上行、下行数据格式,可用于客户自定义探针使用,其中:
服务发现功能只提供HTTP上报格式
其他服务,例如注册,Trace等,提供HTTP/JSON和gRPC两种上报接口。
以下为数据协议的详细内容:
gRPC proto files
*如无法直接打开链接,请右键复制超链接后于浏览器中打开。
协议详细说明查看:
https://github.com/apache/incubator-skywalking/blob/master/docs/cn/Trace-Data-Protocol-CN.md
Skywalking Cross Process Propagation Headers Protocol
Skywalking是一个偏向APM的分布式追踪系统,所以,为了提供服务端处理性能。头信息会比其他的追踪系统要更复杂一些。 你会发现,这个头信息,更像一个商业APM系统,并且,一些商业APM系统的头信息,比我们的要复杂的多。
协议详情查看
https://github.com/apache/incubator-skywalking/blob/master/docs/cn/Skywalking-Cross-Process-Propagation-Headers-Protocol-CN-v1.md
命名空间
SkyWalking是一个用于从分布式系统收集指标的监控工具。在实际环境中,一个非常大的分布式系统包括数百个应用程序,数千个应用程序实例。在这种情况下,更大可能的不止一个组,甚至还有一家公司正在维护和监控分布式系统。他们每个人都负责不同的部分,不能共享某些指标。
在这种情况下,命名空间就应运而生了,它用来隔离追踪和监控数据.
当双方使用不同的名称空间时,跨进程传播链会中断。
在探针配置中配置 agent.namespace
The agent namespace
agent.namespace=default-namespace