【阅读笔记】《Weakly- and Semi-Supervised Panoptic Segmentation》(一)——论文部分
本文记录了博主阅读论文《Weakly- and Semi-Supervised Panoptic Segmentation》的笔记,论文有代码,主页。
更新于2019.03.05。
文章目录
- 摘要
- Introduction
- Related Work
- Proposed Approach
- Training with weaker supervision
- Approximate ground truth from bounding box annotations
- Approximate ground-truth from image-level annotations
- Iterative ground truth approximation
- 网络结构
- 实验
- 实验设置
- Pascal VOC实验结果
- CityScapes实验结果
- 结论及未来工作
- 附件A:更多实验结果
- 附件B:实验细节
- B.1 网络结构和训练
- B.2 多类别分类网络
- 附件C:比较Pascal VOC与Microsoft COCO标注质量
- 附件D:计算在只有弱标注存在的情况下标注时间的减缩因数
摘要
- 文章提出了一个可以同时进行实例分割和语义分割的算法,对于重叠区域不会进行重复实例标记。
- 评估了标注质量与估计表现之间的关系。
- 在CityScapes上面,语义分割、实例分割都是第一。
Introduction
以下只整理要点:
- 手动标注耗时:CityScapes数据库指出,标注一幅图片平均需要一个半小时。
- 算法只需要借助bounding boxes和image-level tags训练。前者用这个方法标注只需要7秒,后者平均一个类别1秒。因此,只用这些弱标注可以将标注CityScapes的时间缩短30倍。
- 与其他方法的区别:首先,同时分割语义和实例(其他算法只分割语义,实例不可得);另外,同时分割可数和不可数类别,而现存大部分同时进行语义和实例分割的算法都是只关注可数。
- 分割对每个像素给出其object class和instance identifier,对于可数目标同时还给出object detection。
- 对“thing”(可数)类别用weak bounding box annotations,对“stuff”(不可数)类别用image-level tags。
- 作者称,这是首个弱监督、非重叠实例分割,能够同时标注thing和stuff的网络;也是首个在CityScapes下弱监督的网络;也是首个通过弱监督同时实现实例分割和语义分割的网络。

Related Work
- 弱监督实例分割的研究工作很少,但是弱监督语义分割还是挺多的。
- 本项工作是基于self-training的概念进行实例分割的,即在训练过程中,网络自身会生成必要的真值。
- 本项工作既支持混合标注(fully- and weakly-labelled trainging examples),也支持全弱监督(only weak supervision)。
Proposed Approach
前四节介绍了如何生成近似真值以训练语义和实例分割模型。之后,第五节介绍网络结构。
Training with weaker supervision
在全监督语义分割模型中,通常对图像中的每个像素单独训练一个多项逻辑回归,损失函数是真值分布与估计之间的交叉熵损失:
L = − ∑ i ∈ Ω log p ( l i ∣ I ) L=-\sum_{i\in\Omega}\text{log}p(l_i\vert \bf{I}) L=−i∈Ω∑logp(li∣I)
其中 l i l_i li是在像素 i i i处的真值标注, p ( l i ∣ I ) p(l_i\vert\bf{I}) p(li∣I)是神经网络的输出经过softmax激活函数得到的图像 I \bf{I} I中的像素点 i i i的真标注的概率, Ω \Omega Ω是图像中所有的像素点的集合。
对于本文所关注的弱监督情况,不是所有的 Ω \Omega Ω内的像素都有真值标注。因此,这里用弱监督和图像先验估计出图像中像素点的一个子集 Ω ′ ∈ Ω \Omega'\in\Omega Ω′∈Ω的真值,再用这个估计得到的像素子集的标签训练网络。后面会具体介绍如何估计 Ω ′ \Omega' Ω′和对应的标签。
估计真值的方法是,只标注有信心的像素,将其他的像素标注成 Ω ∖ Ω ′ \Omega\setminus\Omega' Ω∖Ω′作为“忽略”区域,不对其计算损失。这么做的原因来源于,Bansal等人在这篇论文中提出,对图像中抽取4%的样本计算损失与传统方法计算所有像素的损失在全监督训练过程中的效果是一样的。这也就支撑了他们的假设:用于像素级任务的训练数据在一幅图像内是统计相关的(statistically correlated),随机抽取一个小很多的像素集合就够用。
Approximate ground truth from bounding box annotations
像这篇论文一样,用GrabCut(给定bounding box先验后的经典前景分割技术)和MCG(一个segment-proposal算法)从一个bounding-box标注中获取前景mask。为了实现这一过程的高精度,一个像素只有在GrabCut和MCG都同意的前提下,才会被分配给这个bounding box表示的object class。如下图所示。
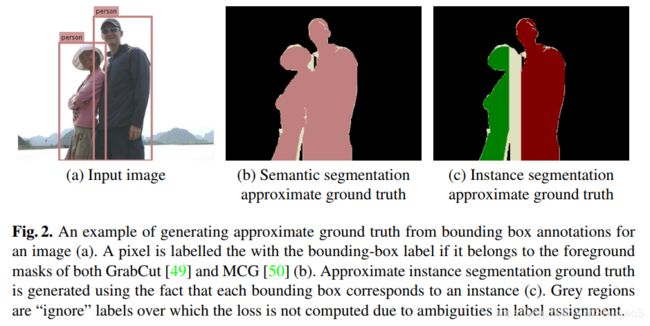
需要注意的是,MCG的最后一步用在PASCAL VOC数据库下像素级别监督训练的随机森林对所有proposed segments排序。本文的算法没有用这一步,而是通过选择与bounding box拥有最高IoU(Intersection over Union)的proposal的方式获取一个前景mask。
因为每个box都对应一个实例,所以每个box的前景都被标注成那个实例。但是,如果两个属于同一类别的bounding box有重叠,那么重叠部分将被忽略(因为没有足够信息判断它该属于哪个实例)。
Approximate ground-truth from image-level annotations
当只有image-level的标签时,论文作者利用了如下结论:用于图像分类的CNN的卷积层仍然含有定位信息(论文)。因此,当只有图像和其tag的时候,论文作者首先训练一个多类别分类器。随后,根据image-level tags提取图像内的所有目标类别的弱定位线索。这些定位热度图(localisation heatmap,如下图所示)就是获取某一特定类别的估计真值的阈值。

博主注:CAM(Classification Activation Mapping,等同于前文说的热度图)直观来说就是显示出图像中的哪一部分对分类结果的影响最大,影响越大热度越高。(论文:Learning Deep Features for Discriminative Localization),下图为示例。
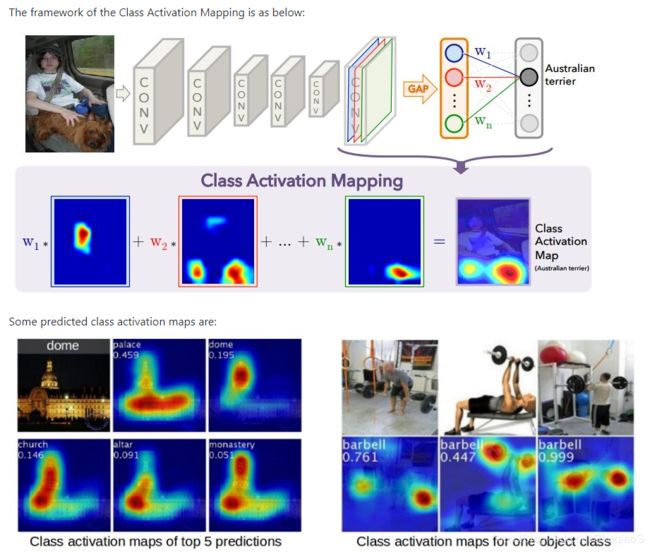
不同类别的定位热度图很有可能重叠。在这种情况下,占空间更小的热度图将被给予优先级。 与这篇论文类似,论文作者发现这种策略能够有效防止细小目标被忽略。
尽管Grad-CAM独立于使用过的weak localisation method,论文作者仍然用了Grad-CAM。其对非CAM结构的网络效果未知,且在ImageNet定位任务中的效果比激发BP(Excitation BP)要好。
由于实例的个数未知,我们没有办法仅通过image tags求相同类别下的不同实例的微分。因此,这种形式的弱监督只适用于无法有多个实例的stuff类别。需要注意的是,像许多工作中应用的显著先验(saliency priors)是没有办法用在这里的,因为对于大多数流行显著性数据库(saliency dataset),只有things被认为是显著的。
Iterative ground truth approximation
上面两节生成的真值可以直接用于网络训练(随机初始化),不过这个真值后面会被网络在训练集上输出的新估计真值所替代。如下图所示。

网络的输出用DenseCRF(Deeplab的参数)做后处理,以提高在边界处的估计表现。另外,任何标注为thing类别但是却在bounding-box之外的像素点会被设置成ignore,因为我们已知thing类别的东西是不会在bounding-box之外的。对于像Pascal VOC这种数据库,这些点会被设成background而非ignore,因为在该数据库中,background是唯一的stuff类别。
网络结构
前文所述的参数更新方法可以应用到多种网络结构,也可以与人工标注相结合变成半监督。这里使用Arnab等人提出的网络结构,因为其能够同时提供语义和实例分割,可以端到端训练,可以给出目标检测。该网络含有一个语义分割的子网络,后面跟了一个实例分割网络。如下图所示,实例分割网络在目标检测的帮助下,将原始的语义分割变成实例分割。
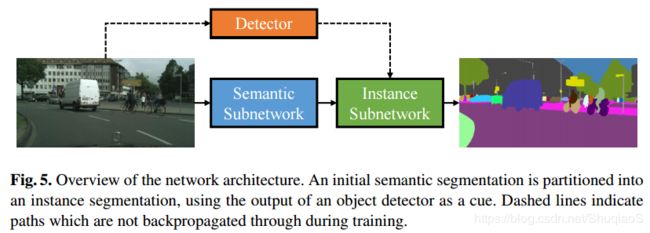
下图是上述使用的网络结构的论文中的图:

这里用 Q \bf{Q} Q表示语义分割网络的输出,这里网络输出结构可以用任何结构替换,其中 Q i ( l ) Q_i(l) Qi(l)是像素 i i i被分配给语义类别 l l l的概率。实例分割网络有两个输入: Q \bf{Q} Q和图像一系列的目标检测。假设检测到 D D D个目标,每个目标的表述形式都是 ( l d , s d , B d ) (l_d,s_d,B_d) (ld,sd,Bd),其中 l d l_d ld是检测到的类别标签, s d ∈ [ 0 , 1 ] s_d\in[0,1] sd∈[0,1]是score, B d B_d Bd是第 d d d个检测的counding box中的像素点集。这个模型假定每个目标检测代表一个可能的实例,并给最初的语义分割中的像素点用条件随机场(Conditional Random Field, CRF)分配一个实例标签。具体操作是,给图像中所有的 N N N个像素,每一个都定义一个多项式变量 X i X_i Xi,即 X = [ X 1 , X 2 , … , X N ] T \mathbf{X}=[X_1, X_2, \dots, X_N]^T X=[X1,X2,…,XN]T。该变量从集合 { 1 , … , D } \{1,\dots,D\} {1,…,D}中取标签( D D D是detections的个数)。这种设定保证了一个像素只能有一个标签。任务 x \bf{x} x对于所有实例变量 X \bf{X} X的能量可以定义为:
E ( X = x ) = − ∑ i N ln ( w 1 ψ B o x ( x i ) + w 2 ψ G l o b a l ( x i ) + ϵ ) + ∑ i < j N ψ P a r i w i s e ( x i , x j ) E(\mathbf{X=x})=-\sum_i^N\text{ln}(w_1\psi_{Box}(x_i)+w_2\psi_{Global}(x_i)+\epsilon)+\sum_{i<j}^N\psi_{Pariwise}(x_i,x_j) E(X=x)=−i∑Nln(w1ψBox(xi)+w2ψGlobal(xi)+ϵ)+i<j∑NψPariwise(xi,xj)
第一个box项鼓励当一个像素处于检测器某个实例的bounding box中时被标注成该实例:
ψ B o x ( X i = k ) = { s k Q i ( l k ) if i ∈ B k 0 otherwise \psi_{Box}(X_i=k)=\begin{cases} s_kQ_i(l_k) & \text{if}\ i\in B_k \\ 0 & \text{otherwise} \end{cases} ψBox(Xi=k)={skQi(lk)0if i∈Bkotherwise
值得注意的是,这一项对于false positive的情况是鲁棒的,因为当像素 i i i处的语义分割 Q i ( l k ) Q_i(l_k) Qi(lk)与检测标注 l k l_k lk不统一的时候其速度是很慢的。
全局项:
ψ G l o b a l ( X i = k ) = Q k ( l k ) \psi_{Global}(X_i=k)=Q_k(l_k) ψGlobal(Xi=k)=Qk(lk)
与bounding box独立,因此可以可以克服错误定位的bounding box没有覆盖整个实例的情况。
最后的pairwise项是普通的densely-connected Gaussian和双边滤波器(bilateral filter),保证了外观和空间上的一致性。
本文还考虑了stuff类别(目标检测器没有对此类别进行过训练),方法就是引入了dummy detections,即对数据库中所有图像的所有stuff类别都幅值score为1。CRF的最大后验(Maximum-a-Posteriori, MAP)估计是最终的标签,这一步是由可微的循环网络构成的平均场推理(mean-field inference)得到的。
论文作者首先用前文所述的approximate ground truth和标准交叉熵损失训练语义分割子网络,随后加上实例分割的网络,再端到端finetune整个网络。考虑到对于实例分割,不同排序下的实例标注应该是等同的,因此在计算交叉熵损失之前,先会把真值按照prediction重新排序。
实验
实验设置
数据库和弱监督
实验评估数据库:Pascal VOC和Cityscapes。
实验中的弱监督和全监督用的是相同的训练图像,区别是前者用的是前文提到的approximate ground truth。
Pascal VOC有20个标注类别,其他所有类别都被定义为background类。按照常用做法,这里还是用了SBD数据库(Stanford Background Dataset)共得到了10582张训练图像。在本文的某些实验中,还用到了Microsoft COCO数据库,用来与训练语义分割网络。由于评估服务器不支持实例分割,因此作者用了一个1499张图片的验证集评估。
Cityscapes有8个thing类别(论文中用bounding box标注)和11个stuff类别(用image-level tags标注)。语义分割模型用19998张粗标和2975张细标图片训练,实例分割模型用2975张细标图片训练(因为它们包含实例真值标注)。
前文提到的从image-level tags中获取弱监督定位线索的具体方法在附件中具体说明了。
Grad-CAM方法的原作者用的阈值是15%以实现在ImageNet下的弱定位,这里论文作者用的阈值是50%以在这个更混乱的数据库下实现更高的精度。
网络训练
本文用于分割的底层网络是PSP-Net的重新应用。这里论文作者称,为了比较的公平性,他们用相同的超参数(附件中说明)以全监督的方式训练了该网络,而不是直接用了作者提供的公布的全监督网络模型。目标检测部分训练的是Faster-RCNN。所有网络都用了ResNet-101作为主干。
评估度量
作者使用了通常用于评估实例分割的 A P r AP^r APr度量,该度量认为如果一个估计的实例与真值的IoU大于某个阈值时,该实例的估计就是对的。作者还使用了 A P v o l r AP^r_{vol} APvolr度量,该度量是在一定IoU阈值范围内的平均 A P r AP^r APr。按照惯例,这里对VOC用0.1到0.9(间隔0.1),对CityScapes用0.5到0.95(间隔0.05)。考虑到 A P r AP^r APr的局限,这里还应用了Panoptic Quality(PQ):
P Q = ∑ ( p , g ) ∈ T P I o U ( p . g ) ∣ T P ∣ ⎵ Segmentation Quality (SQ) × ∣ T P ∣ ∣ T P ∣ + 1 2 ∣ F P ∣ + 1 2 ∣ F N ∣ ⎵ Detection Quality (DQ) \mathbf{PQ}=\underbrace{\frac{\sum_{(p,g)\in TP}\mathbf{IoU}(p.g)}{\vert TP\vert}}_\text{Segmentation Quality (SQ)}\times\underbrace{\frac{\vert TP \vert}{\vert TP\vert + \frac{1}{2}\vert FP\vert + \frac{1}{2}\vert FN\vert}}_\text{Detection Quality (DQ)} PQ=Segmentation Quality (SQ) ∣TP∣∑(p,g)∈TPIoU(p.g)×Detection Quality (DQ) ∣TP∣+21∣FP∣+21∣FN∣∣TP∣
其中 p p p和 g g g是估计和真值分割, T P TP TP、 F P FP FP和 F N FN FN分别代表true positives、false positives和false negatives的集合。(关于全景度量的具体内容可以看博主之前写过的博客。)
Pascal VOC实验结果
下面两个表格分别是语义分割和实例分割的表现。
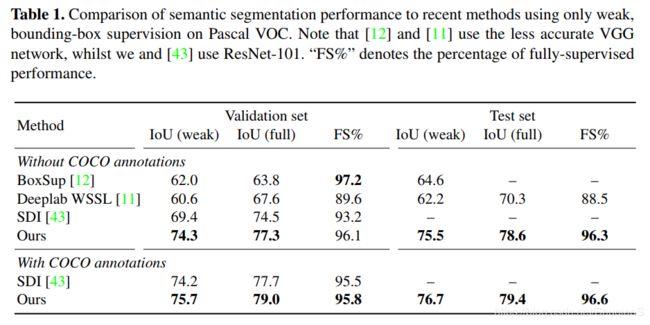
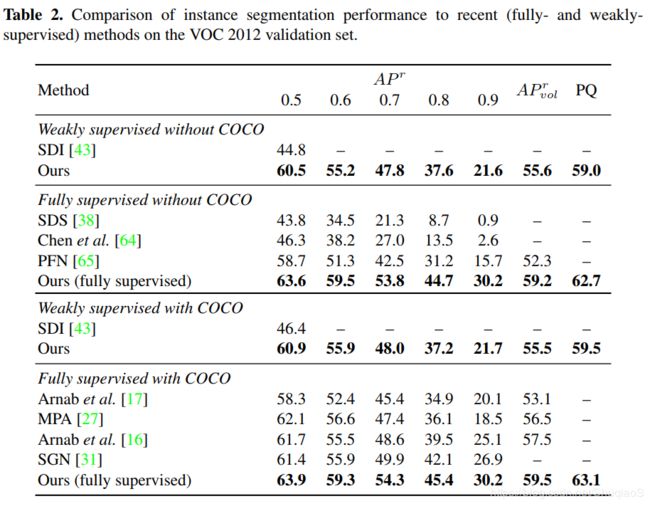
结构上与[16]不同的是,本文中所提出的网络结构是基于PSPNet用了ResNet-101,而[16]用的是这个网络和VGG。更多结果看附件。
实例分割网络的端到端训练
这个实例分割网络可以单独精确训练,也可以与语义分割网络一起进行完整网络的端到端训练。[16]已经证明了在全监督端到端训练下的精度更高。
迭代训练
如前文所述,可以通过迭代的方式更新approximate ground truth,但是对于Pascal数据库(上面两个表格),一次的结果已经很好了,因此没有再迭代。但是后文中会说到,对于CityScapes数据库,迭代就至关重要了。
半监督
下表考察的是弱监督与全监督的结合。
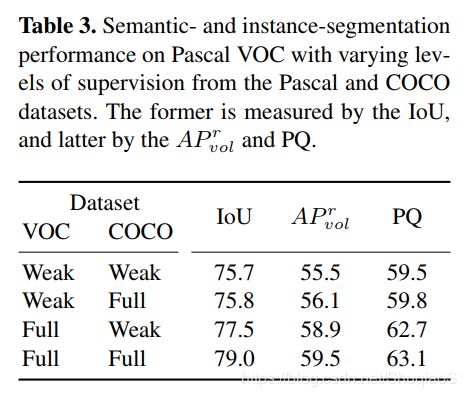
经过对实验和数据库的分析,作者得出了这样的结论:标注少数更准确的样本(Pascal VOC)比标注大量低品质样本(COCO)更有助于提高算法精度
CityScapes实验结果
下面两个网络是据论文作者所知在CityScapes上第一份弱监督训练的结果(语义和实例都是)

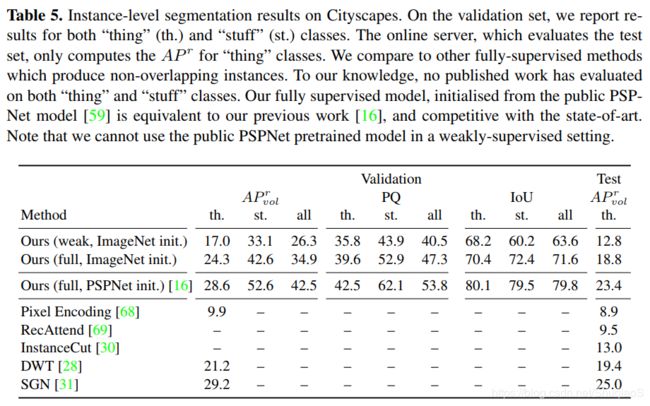
下图为弱监督模型结果示例(更多结果看附件):

迭代训练
下图证明了在Cityscapes数据集下,对于approximate ground truth的迭代训练明显对语义分割和实例分割都有好处。

在用网络的输出重新生成approximate ground truth之前,对网络进行了150000次的迭代训练。

结论:侧面也论证了PQ作为这一类分割任务的度量更好,因为其不受score的影响(不同的score其实对于最终的分割结果也没什么影响)。
结论及未来工作
- 网络效果不错。
- 最好是标注高精度的图片,否则其效果就跟弱监督没什么区别(数据库);最好是标注高精度的图片,否则其效果就跟弱监督没什么区别(数据库)。
- 未来的工作:不用目标检测器作为辅助,直接用image-level tags和图像内的目标个数监督训练。
附件A:更多实验结果





附件B:实验细节
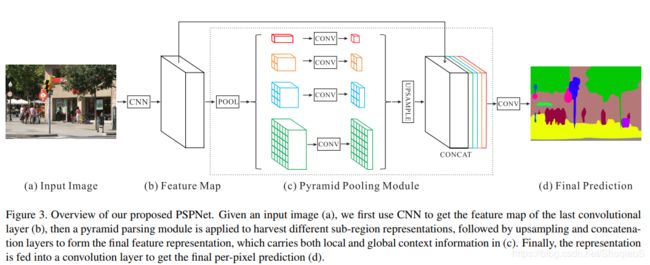
B.1 网络结构和训练
语义分割网络底层是PSPNet,主干(backbone)是ResNet-101,网络输出分辨率是原始分辨率的1/8。
(下面两张图是博主从PSPNet论文中拿过来的)

超参数:batch size是单幅521x521的图像截图,momentum是0.9,weight decay是 5 × 1 0 − 4 5\times10^{-4} 5×10−4。
首先训练的是语义分割网络,之后加上了实例分割网络进行整体的finetune。为了训练语义分割网络,首先以初始学习率 1 × 1 0 − 4 1\times10^{-4} 1×10−4全监督训练了一个模型,学习率在训练损失收敛后减小到 1 × 1 0 − 5 1\times10^{-5} 1×10−5。同样的学习率也应用到了Pascal VOC弱监督模型上,但是没有进行任何迭代。总共迭代了400k次。在CityScapes上弱监督训练时,初始学习率是 1 × 1 0 − 4 1\times 10^{-4} 1×10−4,随后随着每次迭代阶段减半,每个阶段迭代150k次。所有的模型都用的ImageNet-pretrained的权重和batch normalisation statistics。
在实例训练阶段,将VOC和CityScapes数据集下的弱监督和全监督的学习率都固定为 1 × 1 0 − 5 1\times 10^{-5} 1×10−5。观察到总共迭代400k次模型的损失就收敛了。
在训练目标检测器Faster-RCNN时,用的都是公开代码中默认的超参数。
B.2 多类别分类网络
实现如前文所述的弱定位线索(weak localisation cues),首先在CityScapes数据库上训练了一个网络实现多类别分类(multi-label classification)。
这里同样用了PSPNet结构用于分类任务:最后一层卷积层(conv5_4)后面加了一个global average pooling层以整合所有的空间信息,后面加了一个有19个输出(CityScapes数据库的类别个数)的全连接层(fully-connected layer)。这个网络随后用对于每个类别的交叉熵损失训练,对于单个图像,损失函数为:
L = 1 N ∑ i = 1 N − y i log ( sigmoid ( z i ) ) − ( 1 − y i ) log ( 1 − sigmoid ( z i ) ) L=\frac{1}{N}\sum_{i=1}^N-y_i\text{log}(\text{sigmoid}(z_i))-(1-y_i)\text{log}(1-\text{sigmoid}(z_i)) L=N1i=1∑N−yilog(sigmoid(zi))−(1−yi)log(1−sigmoid(zi))
其中 y \mathbf{y} y是image-level label vector,如果第 i i i个类别出现在了图像中,那么 y i = 1 y_i=1 yi=1,否则为0。 z i z_i zi是网络最后的全连接层对于第 i i i个类别的输出。
把整个2048x1024的CityScapes图像放到内存中进行多分类任务是不可能的,如果用前文所述的PSPNet结构(stride of 8),即使batch size为1,也需要48.8GB的内存来训练网络。就算是标准的ResNet-101(stride of 32,空间小16倍)也需要21.7GB。因此,这里从原始的2048x1024的图像中取了15个固定尺寸(500x400)的图块,再用这些图块进行训练。由于这里用了15个固定尺寸的图像,因此在未来现实生活中的标注师们可能会被要求标注像素为500x400的15个图像而不是一幅2048x1024的图像。(这句话博主没懂什么意思。)
这个多类别分类网络的训练用的是batch size为1,固定学习率 1 × 1 0 − 4 1\times 10^{-4} 1×10−4,直到训练损失收敛。论文作者发现在50k次迭代后网络收敛。此时,对于验证集上的mean Average Precision(mAP)是7838。Pascal VOC也用mAP这个指标以衡量多类别分类。
附件C:比较Pascal VOC与Microsoft COCO标注质量
前文提到过Pascal VOC中图像的标注质量比Microsoft COCO中的要高。下图说明了这个观察。


附件D:计算在只有弱标注存在的情况下标注时间的减缩因数

加入星球了解更多分割知识: