Python瀑布流爬虫-爬取360网站图片+爬取百度图片
Python瀑布流爬虫
本章所讲内容:
1、爬虫认识
2、Python与爬虫
3、关于爬取图片的设想
4、瀑布流爬虫的分析
实战:快速爬取360网站图片
实战:快速爬取百度图片瀑布流爬虫实现,批量下载图片!

1、爬虫认识
爬虫(spider:网络蜘蛛):是一个用脚本代替浏览器请求服务器获取服务器资源的程序。
数据收集(数据分析、人工智能)
模拟操作(测试、数据采集)
接口操作(自动化)
瀑布流
我们数据比较多的时候,为了更好用户体验和节省服务器资源,我们进行渐进式的加载。
数据量很大
瀑布流的图片通常是用js加载
瀑布流一定用的ajax技术
注意:Ajax技术通常返回的是一个json文本格式
2、Python与爬虫
爬虫分析
结构分析
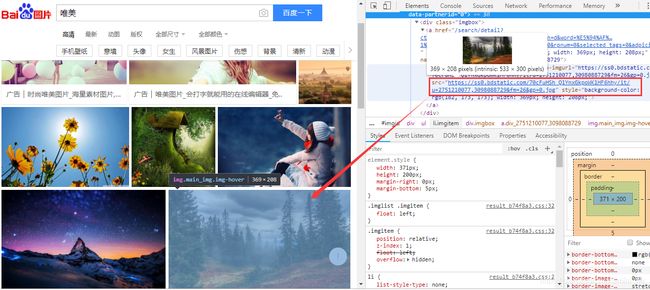
- 当前的图片来源于js的渲染
- 使用的ajax技术
- 使用ajax通常返回json数据
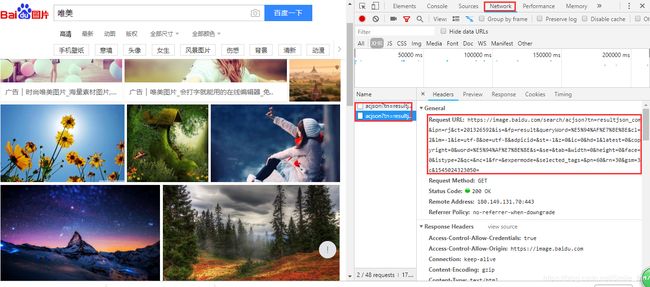
抓包分析
我们开始尝试编写代码
Pycharm 编译器 2018.2.3版本
Python3.7.2 requests#pip install requests
实战:爬取360图片,将图片保存在本地!
import requests,time
from urllib import request
url = 'http://image.so.com/zj?ch=beauty&sn=30&listtype=new&temp=1'
headers= {
'Referer': 'http://image.so.com/z?ch=beauty',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
}
str_data = '''ch: beauty
sn: 120
listtype: new
temp: 1
'''
send_data = {}
for data in str_data.splitlines():
line_data = data.split(': ')
if len(line_data) == 2:
key,value = line_data
if key and value:
send_data[key] = value
response = requests.get(url,headers=headers,params=send_data)
json_data = response.json()['list']
for index,src in enumerate(json_data):
image_url = src['qhimg_url']
try:
image_name = './image/'+image_url[-8:]
request.urlretrieve(url=image_url,filename=image_name)
except Exception as e:
print(e)
else:
print('{} is download'.format(image_name))运行效果如下:
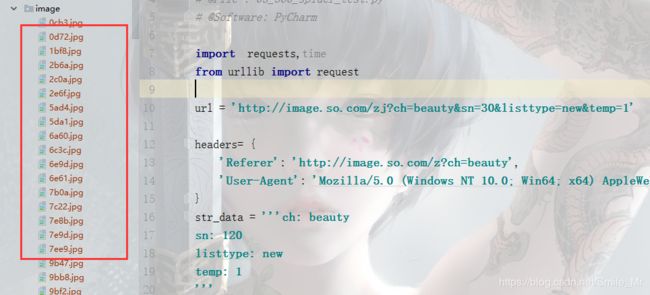
基本的请求代码:
import time
import requests
from urllib import request
url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E5%94%AF%E7%BE%8E&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word=%E5%94%AF%E7%BE%8E&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&selected_tags=&pn=30&rn=30&gsm=1e&1545019467831='
headers = {
'Referer': 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%94%AF%E7%BE%8E',
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36",
}
data_str = '''
tn: resultjson_com
ipn: rj
ct: 201326592
is:
fp: result
queryWord: 唯美
cl: 2
lm: -1
ie: utf-8
oe: utf-8
adpicid:
st:
z:
ic:
hd:
latest:
copyright:
word: 唯美
s:
se:
tab:
width:
height:
face:
istype:
qc:
nc: 1
fr:
expermode:
selected_tags:
pn: 30
rn: 60
gsm: 1e
1545019467831:
'''
send_data = {}
for line in data_str.splitlines():
line_data = line.split(': ')
if len(line_data) == 2:
key,value = line_data
if key and value:
send_data[key] = value
response = requests.get(url= url,headers = headers,params=send_data)
content = response.json()['data']
print(content)
num = 1
for index,src in enumerate(content):
img_url = src.get('middleURL')
if img_url:
name = './image/iamge_%s_%s.png'%('唯美',index)
try:
request.urlretrieve(url = img_url,filename=name)
except Exception as e:
print(e)
else:
print('%s is down'%name)
time.sleep(2)接下来我们进行简单的封装:
from urllib import request
import requests,os,time
def get_image(keywords,num):
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord=%E9%AC%BC%E5%88%80&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=&hd=&latest=©right=&word=%E9%AC%BC%E5%88%80&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn=150&rn=30&gsm=96&1545877953682='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36',
'Host': 'image.baidu.com',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1545877913556_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&hs=2&word=%E9%AC%BC%E5%88%80',
}
data = '''
tn: resultjson_com
ipn: rj
ct: 201326592
is:
fp: result
queryWord: 鬼刀
cl: 2
lm: -1
ie: utf-8
oe: utf-8
adpicid:
st: -1
z:
ic:
hd:
latest:
copyright:
word: 鬼刀
s:
se:
tab:
width:
height:
face: 0
istype: 2
qc:
nc: 1
fr:
expermode:
force:
pn: 30
rn: 30
gsm: 96
1545877953682:
'''
sendData = {}
send_data = data.splitlines()
try:
for i in send_data:
data_list = i.split(': ')
if len(data_list) == 2:
key,value = data_list
if key and value:
sendData[key] = value
except Exception as e:
print(e)
sendData['word'] = sendData['queryWord'] = keywords
sendData['rn'] = str(30*num)
response = requests.get(url=url,headers=headers,params=sendData)
content = response.json()['data']
for index,src in enumerate(content):
# index =str(index).zfill(2)
image_url = src.get('middleURL')
if os.path.exists('image')
pass
else:
os.mkdir('image')
if image_url and os.path.exists('image'):
name = './image/image_%s_%s.png'%(index,keywords)
try:
request.urlretrieve(url=image_url,filename=name)
except Exception as e:
print(e)
else:
print('%s is download'%name)
time.sleep(1)
# print(content)
if __name__ == '__main__':
keywords = input('请输入你要的内容:')
num = int(input('请输入你想要的数量:'))
get_image(keywords,num)运行结果如下: