图像检索文献总结(一)
图像检索新人 总结目前图像检索现状 方便自己与他人查看 资料收集自网络 如有侵权 请联系删除
端到端的特征学习方法
NetVLAD: CNN architecture for weakly supervised place recognition (CVPR 2016)
这篇文章是来自于INRIA 的Relja Arandjelović等人的工作。该文章关注实例搜索的一个具体应用——位置识别。在位置识别问题中,给定一张查询图片,通过查询一个大规模的位置标记数据集,然后使用那些相似的图片的位置去估计查询图片的位置。作者首先使用Google Street View Time Machine建立了大规模的位置标记数据集,随后提出了一种卷积神经网络架构,NetVLAD——将VLAD方法嵌入到CNN网络中,并实现“end-to-end”的学习。该方法如下图所示:
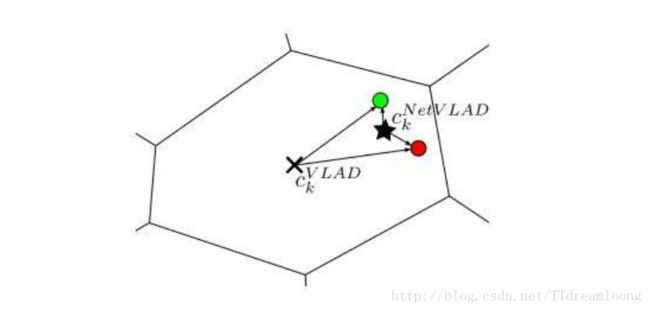
原始的VLAD方法中的hard-assignment操作是不可微的(将每个局部特征指派给离它最近的中心点),因此不可以直接嵌入到CNN网络里,并参与误差反向传播。这篇文章的解决方法就是使用softmax函数将此hard-assignment操作转化为soft-assignment操作——使用1x1卷积和softmax函数得到该局部特征属于每个中心点的概率/权重,然后将其指派给具有最大的概率/权重的中心点。因此NetVLAD包含了三个可以被学习参数,,其中是上面1x1卷积的参数,用于预测soft-assignment,表示为每个簇的中心点。并在上图的VLAD core层中完成相应的累积残差操作。作者通过下图给我们说明NetVLAD相比于原始的VLAD的优势:(更大的灵活性——学习更好的簇中心点)
这篇文章的另一个改进工作就是Weakly supervised triplet ranking loss。该方法为了解决训练数据可能包含噪声的问题,将triplet ranking loss中正负样本分别替换为潜在的正样本集(至少包含一张正样本,但不确定哪张)和明确的负样本集。并且在训练时,约束查询图片和正样本集中最可能是正样本的图片之间的特征距离比查询图片与所有负样本集内的图片之间的特征距离要小。
Deep Relative Distance Learning: Tell the Difference Between Similar Vehicles (CVPR 2016)
接下来的这篇文章关注的是车辆识别/搜索问题,来自于北京大学Hongye Liu等人的工作。如下图所示,这个问题同样可以被看成实例搜索任务。
 和很多有监督的深度实例搜索方法一样,这篇文章旨在将原始的图片映射到一个欧式特征空间中,并使得在该空间里,相同车辆的图片更加聚集,而非同类的车辆图片则更加远离。为了实现该效果,常用的方法是通过优化triplet ranking loss,去训练CNN网络。但是,作者发现原始的triplet ranking loss存在一些问题,如下图所示:
和很多有监督的深度实例搜索方法一样,这篇文章旨在将原始的图片映射到一个欧式特征空间中,并使得在该空间里,相同车辆的图片更加聚集,而非同类的车辆图片则更加远离。为了实现该效果,常用的方法是通过优化triplet ranking loss,去训练CNN网络。但是,作者发现原始的triplet ranking loss存在一些问题,如下图所示:
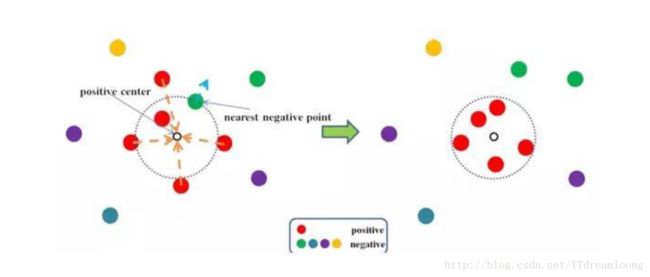
 对于同样的样本,左边的三元组会被损失函数调整,而右边的三元组则会被忽视。两者之间的区别在于anchor的选择不一样,这导致了训练时的不稳定。为了克服该问题,作者用coupled clusters loss(CCL)去替代triplet ranking loss。该损失函数的特点就是将三元组变成了一个正样本集和一个负样本集,并使得正样本内的样本相互聚集,而负样本集内的样本与那些正样本更加疏远,从而避免了随机选择anchor样本所带来的负面影响。该损失函数的具体效果如下图所示:
对于同样的样本,左边的三元组会被损失函数调整,而右边的三元组则会被忽视。两者之间的区别在于anchor的选择不一样,这导致了训练时的不稳定。为了克服该问题,作者用coupled clusters loss(CCL)去替代triplet ranking loss。该损失函数的特点就是将三元组变成了一个正样本集和一个负样本集,并使得正样本内的样本相互聚集,而负样本集内的样本与那些正样本更加疏远,从而避免了随机选择anchor样本所带来的负面影响。该损失函数的具体效果如下图所示:
最后这篇文章针对车辆问题的特殊性,并结合上面所设计的coupled clusters loss,设计了一种混合的网络架构,并构建了相关的车辆数据库去提供所需的训练样本。
DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations (CVPR 2016)
最后的这篇文章同样是发表在CVPR 2016上,介绍了衣服识别和搜索,同样是与实例搜索相关的任务,来自于香港中文大学Ziwei Liu等人的工作。首先,本篇文章介绍了一个名为DeepFashion的衣服数据库。该数据库包含超过800K张的衣服图片,50个细粒度类别和1000个属性,并还额外提供衣服的关键点和跨姿态/跨领域的衣服对关系(cross-pose/cross-domain pair correspondences),一些具体例子如下图所示:
 然后为了说明该数据库的效果,作者提出了一种新颖的深度学习网络,FashionNet——通过联合预测衣服的关键点和属性,学习得到更具区分性的特征。该网络的总体框架如下所示:
然后为了说明该数据库的效果,作者提出了一种新颖的深度学习网络,FashionNet——通过联合预测衣服的关键点和属性,学习得到更具区分性的特征。该网络的总体框架如下所示:
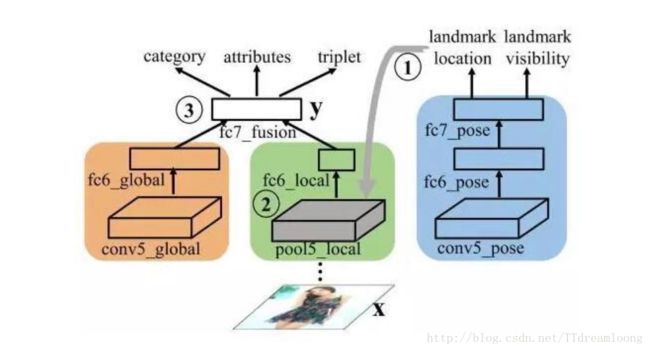
FashionNet的前向计算过程总共分为三个阶段:第一个阶段,将一张衣服图片输入到网络中的蓝色分支,去预测衣服的关键点是否可见和位置。第二个阶段,根据在上一步预测的关键点位置,关键点池化层(landmark pooling layer)得到衣服的局部特征。第三个阶段,将“fc6 global”层的全局特征和“fc6 local”的局部特征拼接在一起组成“fc7_fusion”,作为最终的图像特征。FashionNet引入了四种损失函数,并采用一种迭代训练的方式去优化。这些损失分别为:回归损失对应于关键点定位,softmax损失对应于关键点是否可见和衣服类别,交叉熵损失函数对应属性预测和三元组损失函数对应于衣服之间的相似度学习。作者分别从衣服分类,属性预测和衣服搜索这三个方面,将FashionNet与其他方法相比较,都取得了明显更好的效果。
总结:当有足够多的有标注数据时,深度学习可以同时学习图像特征和度量函数。其背后的思想就是根据给定的度量函数,学习特征使得特征在该度量空间下具有最好的判别性。因此端到端的特征学习方法的主要研究方向就是如何构建更好的特征表示形式和损失函数形式。
基于CNN特征的特征编码方法
本文在上面部分介绍的深度实例搜索算法,主要关注数据驱动的端到端特征学习方法及相对应的图像搜索数据集。接下来,本文关注于另一个问题:当没有这些相关的搜索数据集时,如何提取有效的图像特征。为了克服领域数据的不足,一种可行的策略就是在CNN预训练模型(训练在其他任务数据集上的CNN模型,比如ImageNet图像分类数据集)的基础上,提取其中某一层的特征图谱(feature map),对其进行编码得到适用于实例搜索任务的图像特征。本部分将根据近些年相关的论文,介绍一些主要的方法(特别的,本部分中所有的CNN模型都是基于ImageNet分类数据集的预训练模型)。
Multi-Scale Orderless Pooling of Deep Convolutional Activation Features (ECCV 2014)
这篇文章发表在ECCV 2014上,是来自于北卡罗来纳大学教堂山分校Yunchao Gong和伊利诺伊大学香槟分校Liwei Wang等人的工作。 由于全局的CNN特征缺少几何不变性,限制了对可变场景的分类和匹配。作者将该问题归因于全局的CNN特征包含了太多的空间信息,因此提出了multi-scale orderless pooling (MOP-CNN)——将CNN特征与无序的VLAD编码方法相结合。
MOP-CNN的主要步骤为,首先将CNN网络看作为“局部特征”提取器,然后在多个尺度上提取图像的“局部特征”,并采用VLAD将这些每个尺度的“局部特征”编码为该尺度上的图像特征,最后将所有尺度的图像特征连接在一起构成最终的图像特征。提取特征的框架如下所示:
 作者分别在分类和实例搜索两个任务上进行测试,如下图所示,证明了MOP-CNN相比于一般的CNN全局特征有更好的分类和搜索效果。
作者分别在分类和实例搜索两个任务上进行测试,如下图所示,证明了MOP-CNN相比于一般的CNN全局特征有更好的分类和搜索效果。

Exploiting Local Features from Deep Networks for Image Retrieval (CVPR 2015 workshop)
这篇文章发表在CVPR 2015 workshop上,是来自于马里兰大学帕克学院Joe Yue-Hei Ng等人的工作。近期的很多研究工作表明,相比于全相连层的输出,卷积层的特征图谱(feature map)更适用于实例搜索。本篇文章介绍了如何将卷积层的特征图谱转化为“局部特征”,并使用VLAD将其编码为图像特征。另外,作者还进行了一系列的相关试验去观察不同卷积层的特征图谱对实例搜索准确率的影响。

Aggregating Deep Convolutional Features for Image Retrieval(ICCV 2015)
接下来这篇文章发表在ICCV 2015上,是来自于莫斯科物理与技术学院Artem Babenko和斯科尔科沃科技学院Victor Lempitsky的工作。从上面两篇文章可以看出,很多深度实例搜索方法都采用了无序的编码方法。但包括VLAD,Fisher Vector在内的这些编码方法的计算量通常比较大。为了克服该问题,这篇文章设计了一种更加简单,并且更加有效的编码方法——Sum pooing。Sum pooling的具体定义如下所示:

其中就是在卷积层在空间位置上的局部特征(这里提取局部特征的方法,与上篇文章一致)。在使用sum pooling后,对全局特征进一步地执行PCA和L2归一化得到最终的特征。作者分别与Fisher Vector,Triangulation embedding和max pooling这些方法进行比较,论证了sum pooling方法不仅计算简单,并且效果更好。
来自 深度学习大讲堂 https://zhuanlan.zhihu.com/p/22265265
Where to Focus: Query Adaptive Matching for Instance Retrieval Using Convolutional Feature Maps (arXiv 1606.6811)
本论文在《Particular object retrieval with integral max-pooling of CNN activations》 的基础上重新提出一种Reranking的方法。
在叙述开始之前,先理解一下卷积Feature Map

上图是对不同卷积层的一个可视化,我们可以看到,early convolutional layer捕捉的是一个主要的视觉模型,而late convolutional layer更多的则是对目标轮廓的表示。
这篇论文那里面的Reranking过程整理:
一 方法介绍
1生产base regions,方法有两种:
1.1 Feature Map Pooling(FMP)
对于卷积网络某一层,若有D个卷积核,可以生产D张Feature Map(FM) 图。对于每一个FM,我们选取响应值非零的位置作为一个Base Regions(BR),这样BR的数量就相当于FM的数量。然后对BR中的响应值作sum-pooling,这样每一个FM都会得到一个值fd。但是对于一个给定的Image,很多FM有很大的重叠,所以其对应的pooling特征,也就是fd基本相同,我们对这些Fd值进行一个聚类,聚类中心设置为K。(这里可以理解把D个BR聚类成K个BR)。


sum-pooling图示意(把响应值相加)
1.2 Overlapped Spatial Pyramid Pooling (OSPP)

OSPP法与提出R-MAC论文里的Regions提取方法相同,对应不同尺度,我们提取 l × (l + m − 1) 个Regions,其宽度= 2 min(W; H)/(l + 1),再均匀采样出m个区域(BR区域)
2 Reranking过程
论文提出Query Adaptive Matching(QAM)的一个方法进行Reranking,其实就是对BR进行归并成一个Merge Region,而这个选取过程转化成一个最优化问题。利用下面这个过程,对于某张图片而言,选出与query最相似的一个合并区域(merge regions)
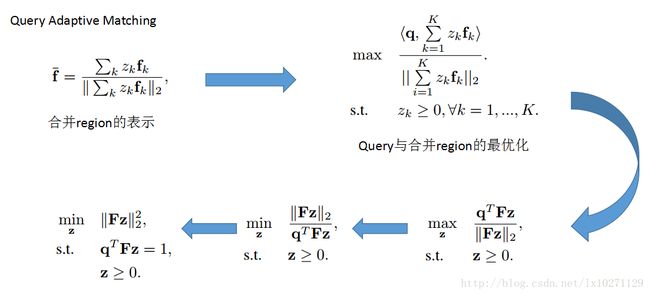
通过以上的的优化过程(其实最后就是一个普通的二次规划问题)我们选取出某张图片一个Merge Region。计算出query和Merge region的相似度得分做为Reranking的Score,最终进行排名。
这里说一下我对上面Base region 的生成过程 结合QAM的理解:
对于FMP方法:每一个Feature Map我们会得到一个Base Region,所以,通过FMP的方法,我们最后得到的Base region的数量等于该层卷积核的数量。而最终base-region的表示,论文确用了一个sum-pooling的方式,这样每一个Base Region最终只会得出一个值,而在最优化过程中,Merge Region最终表示也会成为一个值,也就无法与query的向量做内积。这也是我一直对这篇论文疑惑的地方,如果哪个学长(先于闻道为长之)看明白了这个问题,还请不吝赐教。(也可能是论文的一个错误)
对于OSPP法:由于在不同FM上做不同尺度的Base Region选取,所以对应不同的Base Region有不同的向量表达形式。我们可以很轻松的应用QAM对Base Region进行选取。
Deep Image Retrieval: Learning global representations for image search. In ECCV, 2016.
论文地址:https://arxiv.org/abs/1604.01325
extended version:end to end learning of deep visual representations for image retrieval, in arxiv, 16.10.
=====
看图说话:
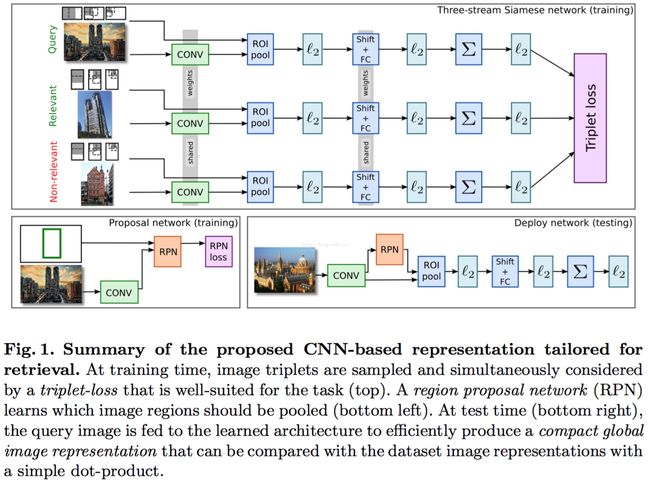
从图上可以看出该论文的整体框架:
1 基于pre-trained model on Imagenet(如VGG16)
2 从Landmarks dataset[17],中挖掘出一个full或者clean的数据集(包括类别标签 Full Datset和bounding box Clean Dataset)
3 用数据集Full Daset来进行finetune,其loss是一般的分类的loss;用Clean Dataset来进行finetune,其loss为triplet loss
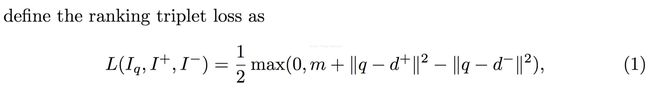
4 用训练好的模型对公开数据集进行feature extraction,similarity measure采用欧式距离(dot product)
论文中也采用了query expansion的方式来boost performance。
=====
下面重点讲下上面的1和3.
(对于数据集这个的获取,其实笔者没有怎么看懂,只明白需要提供一个clean的数据集就好)
1 pre-trained model以及该论文的framework。
这里可以采用AlexNet,VGGNet,Resnet等,取决与你想要的效果(performance和speed)
对于VGGNet(如VGG16),摘掉全连接层,取而代之的是RPN + RoI Pooling +shift + fc + L2等。
为什么要用RPN,这里为了取代rigid grid的做法(仅在test的时候取代,而finetune时,proposals就是rigid grid,具体看论文中的引用论文)。
也可以看extended version的论文,将RPN彻底取代rigid grid,形成end2end的framework。
至于shift + fc的作用就是取代一般pipeline中的PCA Whitten。
这里的L2和后续的求和(所有regions的feature对应求和得到最后global compact的image representation)和L2,仿效一般pipepline的做法。
(具体可以参考
Particular Object Retrieval with Integral Max-Pooling of CNN Activations. In ICLR, 2016.)
因为以上的操作都是可导的,这样就可以将它们嵌入到一个模型中,进行forward和backward地训练模型,而再也不是一个pipeline的做法。
2 MAC feature的简单介绍:(pooling可以用sum也可以用max,或者其他的)

R-MAC:一般的MAC是针对whole image的feaute map,而R-MAC的做法就是参考RoI Pooling的做法,将bounding box 投影到feature map上,然后仅在投影在feature map上的区域进行pooling。
3 RPN
这个没有什么好说的,请参考faster rcnn。
具体是将RPN这个sub-network放到上面framework上,数据采用Clean Dataset。
4 训练
先用rigid grid的方式产生region,用于训练siamese的triplet loss或者简单的classification,对应的数据集为Clean Dataset和Full Dataset。
然后用Clean Dataset来训练RPN
最后测试的时候,用RPN产生的proposals替代rigid grid。
(不过论文中提到用Full Dataset训练的classification的模型来初始化triplet loss的模型,效果更佳)
至于具体的网络参数,请参考论文。
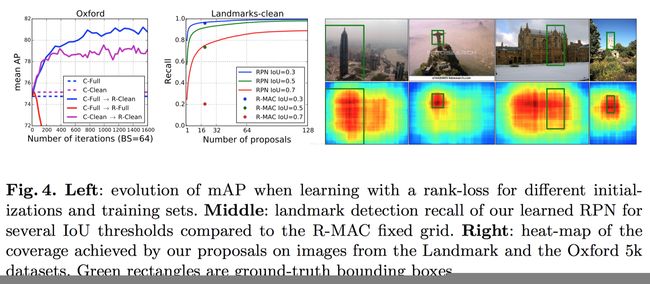
5 数据的产生
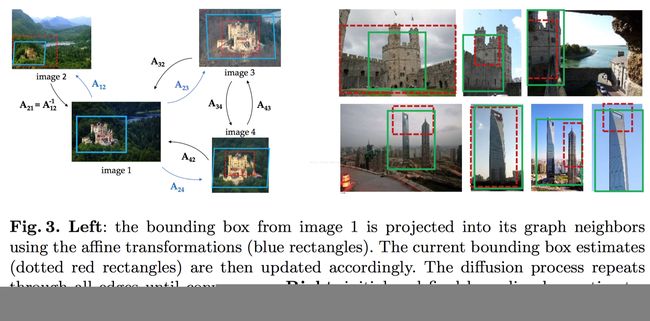
【CVPR 2016】faster r-cnn features for instance search 笔记
论文源码以及视频:http://imatge-upc.github.io/retrieval-2016-deepvision/
我自己制作的ppt地址:http://download.csdn.net/detail/dengbingfeng/9524748
这篇paper的解读默认大家对faster-rcnn有基本的了解....
基本流程:
利用现有的faster-rcnn物体检测只前向传播一次来提取整个图像的卷积特征和区域卷积特征,共享计算。
检索物体在检索图像中用提供的坐标框表示其位置,使用faster-rcnn提取整个数据集图像的conv5_3层特征,并于待检索图像的conv5_3层特征比较余弦相似度,这样便完成对整个数据集图像的第一次rank,即和待检索图片越相似越排名越靠前。
在第一次rank后的基础上,针对排名top N的图片,利用faster-rcnn框处物体检测框,取出所有物体检测框的pool5层特征和待检索物体的pool5层特征比较余弦相似度,依然越相似的排名越靠前,完成rerank,即第二次排序。
操作完后将top 10的结果显示出来。

细节:
1.Image-wise pooling of activations (IPA)
就是用最后一层卷积层的激活值来构建对整幅图片的描述。
2.Region-wise pooling of activations (RPA)
RPN产生的proposals的卷积特征求和池化特征先用L2归一化,whitening后再L2归一化一次,而最大池化特征只进行一次L2归一化。
3.微调faster-rcnn
两种:只调整全连接层和除前两层卷积层外都所有层都微调
4.Class-Agnostic Spatial Reranking (CA-SR)
未知类别空间排序
5.Class-Specific Spatial Reranking (CS-SR)
特定类别排序,使用相同检索物体微调后的网络,可以直接使用RPN proposal的得分来作为与待检索物体的相似度得分,
得分用来对图片列表进行排序。
6.数据集
在Oxford和Pairs数据集里,输出12种类别可能(11种建筑+背景)。
在INS 13中有30种不同的检索实例,输出31种类别可能。
只调整全连接层在检索物体较难的时候效果不好。
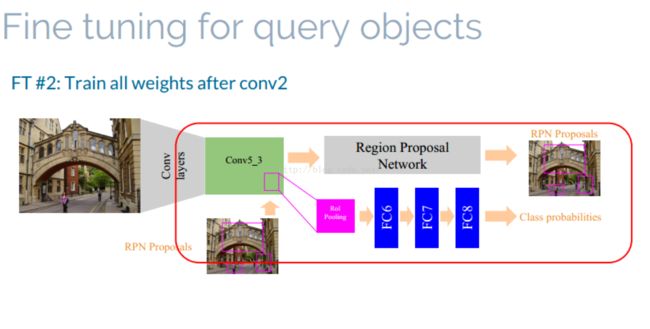
整个网络结构

整个网络从总体上看是faster-rcnn的网络结构,上面一部分是faster-rcnn 的RPN net部分,RPN net的输出rpn proposals,网络的下面部分
是ROI pooling 加上三个全连接层,输出是class probabilities.
Image-wise pooling of activations(IPA): 这一步骤实际上抽出image的representation,具体的方法是从卷积层的最后一层
conv5_3(针对VGG16 Net,并且经过了reLu层之后),然后做pooling,具体pooling 的方法作者是借鉴另外一篇paper:《particular object retrieval
with integeral max-pooling of CNN activations》。举个例子来说:如果最后conv5_3得出的feature map的维度是K*W*H,其中K为卷积核的数目,W*H
为每一个卷积核卷积之后的feature map,这样对于每一个W*H的feature Map 采用max-pooling 或者sum-pooling 就能得到一个值。这样,整个K*W*H
采用pooling之后得到的feature即为K*1的向量。
Region-wise pooling of activations(RPA): 这一步骤得到的是region的representation,有了上面的IPA,这一步的RPA也很容易理解,
就是找出region proposals 的ROI pooling,在ROI pooling层上面做max-pooling。
fine-tuning faster rcnn
fine tuning 采用两种方式:
strategy1: fine tuning ROI pooling之后的三层网络。

strategy2:fine tuning network after conv_2
fine-tuining 所使用图像为query 图像以及将其做horizontal flip之后的图像(个人感觉图像好少)。
3.Image Retrieval
一共分为三个步骤:
1.过滤:提取出查询图像以及数据库图像的IPA,然后通过计算余弦距离将数据库图像进行排序。(整个过程都是使用的图像的IPA与区域无关)。
2.空间重排:
空间重排采用了两种方法:
Class-Agnostic Spatial Reranking (CA-SR):假设类别不可知,计算每一个query bounding box的RPA与采用第一部过滤前N幅图像每一个proposal的
余弦距离,最高的作为query与图像的余弦距离。
Class-Specific Spatial Reranking(CS-SR):使用和query相同的instances 来fine-tuin过后的整个网络,然后使用FC-8之后的class-probality 的类别得分
将其作为query与proposal 的得分。

3.查询扩展:最简单的查询扩展的方法。