生成对抗网络GAN系列(五)--- pix2pix---Image-to-Image Translation with Conditional Adversarial Networks---附代码

Image-to-Image Translation with Conditional Adversarial Networks-(pix2pix)
Phillip Isola Jun-Yan Zhu Tinghui Zhou Alexei A. Efros
Berkeley AI Research (BAIR) Laboratory, UC Berkeley
---文末附代码
1.概述
很多图像处理、计算机图形徐、计算机视觉方面的任务的本质都是一样的,就是把一个输入图像给翻译成另一个输出图像。概括的说,都是predict pixels from pixels
即是 依据像素点(输入信息)对像素点做出预测
故本篇文章提出的网络称为:pix2pix
2.核心思想
本篇论文的核心思想并不复杂,是借鉴了conditional-GAN的思想。了解cGAN的朋友都清楚,cGAN在输入G网络的时候不光会输入噪音,还会输入一个条件(condition),G网络生成的fake images 会受到具体的condition的影响。
那么现在,如果把一副图像作为condition,则生成的fake images 就与这个condition images有对应关系。
这样一来,就实现了一个Image-to-Image Translation 的过程
3.具体的实现方法

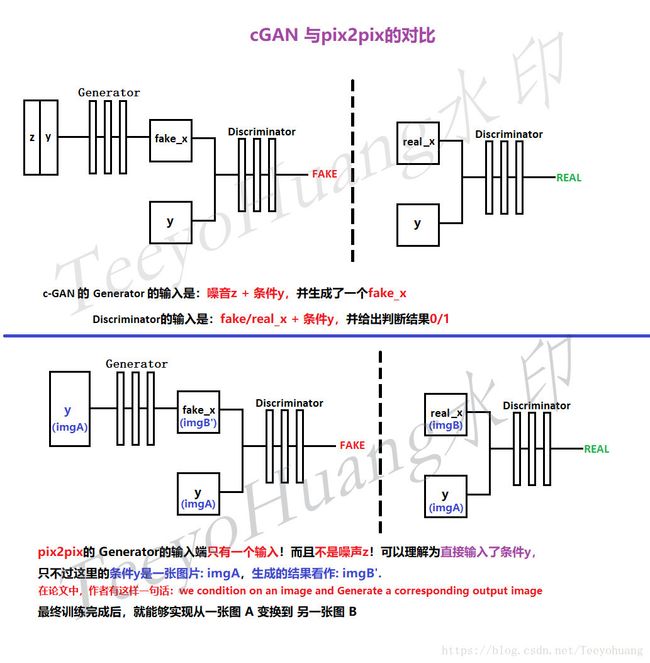
本图就是pix2pix的一个原理图。
注意重点,虽然是借鉴了conditional-GAN的思想,但是又与cGAN有区别
我这里把它和cGAN做个对比:
本网络的损失函数设置为:
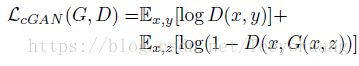
这里的损失函数中,G的输入仍然写的是(x,z),说实话,其实并不用噪音z,
它官方给的代码里,输入都没有噪音z,也就是说,写个G(x)就可以了。
然后和我上面的讲解图中的区别就是,x和y的命名交换了一下,他这里是把条件命名为x,真实数据为y,参考上面那个鞋子图…而我的对比讲解图中,是为了和cGAN做对比,所以条件命名为y,真实数据命名为x。不影响正确性。
以上是传统的条件GAN的loss,本文中还另外加入了一个L1-loss:
![]()
即生成的fake images 与 真实的real images之间的L1距离,(imgB' 和imgB)保证了输入和输出图像的相似度,
最后总的loss函数为:
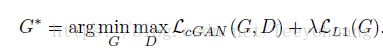
4.网络结构
①Generator
G网络采取的是U-net的结构,大致如下:
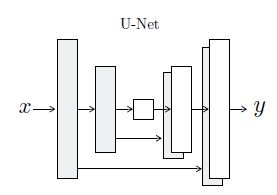
简单的说,是一个end-to-end的网络,且是一个对称的结构,这种结构已经很常见了,在图像分割领域中的SegNet也是这种。
另外还把前面layer的一些map直接连接到后面同样分辨率的layer上去(add skip connections between each layer I and layer n - i),称之为 skip connection。
其实这个思路一点也不新鲜,早在FCN中就已经有类似的思路,FCN中称为skip layer, 在residual network 的每一个basic block 把结果加上residual x也是类似的思想。
具体的layer的设置,还请参考代码,这里不详细说明。
②Discriminator
D网络也玩了点花样,即称为Pacth-D. 就是说,最后D网络生成的可以是一个patch(或者说一个矩阵),早期的GAN中,D网络一般就只输出一个数字,0or1,这里输出一个矩阵,矩阵中的元素为0or1,矩阵大小可调节(Patch的大小可以调节),后面的实验结果做了分析。
5.实验细节:
①G 和 D 交替训练
②优化D的时候,每次都把损失函数的值先除以2
③Adam优化算法:lr=0.0002,beta1=0.5, beta2=0.999
6.实验结果
①损失函数的对比(论文中4.2提及)

论述了L1+cGAN的结果是最优的。
但是这里我多提一下,因为我本身是做semantic segmentation的,本实验中如果做semantic segmentation这个任务的话(论文中4.6提及):

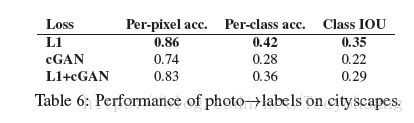
会发现只用L1时,结果更好,所以需要根据具体的任务而言。
②网络结构和损失数的影响(论文中4.3提及)

可见,G采用U-net,损失函数采用L1+cGAN的时候,效果是最佳的
③颜色(论文中4.2 中Colorfulness提及)
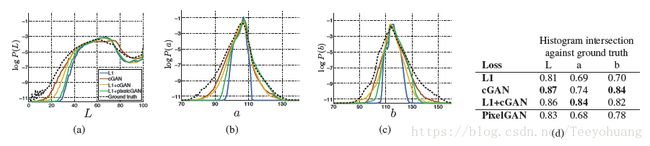
这里采用的是Lab色彩空间做的实验,不是我们常见的(RBG色彩空间),学过图像处理的朋友都知道Lab色彩空间更符合人类视觉体验,总之对比结果见最右侧的表,表明L1损失函数鼓励图像均值化、灰度化,而cGAN损失函数鼓励更多的色彩
④Patch的对比:(论文中4.4提及)

传统的D网络的输出要么就是0要么就是1,即判断真或假
而这个D网络最后输出一个矩阵,矩阵中的元素是0或者1,每一个0或1的感受野FOV对应着输入图像的一块patch,
这样就不只是对整体做一个True or False的判断,而是对一个一个的小patch做真或假的判断
1x1也就是以像素点为单位判别,很模糊,但是颜色却比较丰富,
16x16会显得清晰一些,但是有一些白点
70x70效果更好一些
286x286就是以图像为单位进行判别了
其余的一些我就不赘述了,本篇论文大概就是这样了
这个patch的大小究竟怎么算,其实就是从最后那一层起往后回推感受野(FOV)的大小,所以可以根据代码里面具体的kernel—size和stride 以及layer的层数来回推,这里就不展开讲了。
至于怎么调整这个FOV的大小,可以参考我复现的代码中的model.py文件
7.代码复现:
下面的是我自己复现的简化版代码:
https://github.com/TeeyoHuang/pix2pix-pytorch,
下面的是论文作者写的pytorch版本的代码,说实话代码量有点大,因为是把pix2pix和cycleGAN写在一起的:
https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix,