HashMap源码分析
前言
本文阐述了以下关于HashMap的知识点
- 整体结构
- put 简化逻辑,数组下标哈希计算
- JDK 1.7 与 JDK 1.8的对比
- HashMap的扩容机制
- HashMap是线程非安全的
- 其它扩展
HashMap的数据结构
HashMap的底层是拉链法,即用数组+链表相结合的数据结构,JDK 1.8后引入了 红黑树
而每一个键值对其实都是一个节点,这种节点是一个 Entry 对象
class Entry<K, V> {
private K k;
private V v;
private Entry next;
public Entry(K k, V v, Entry next) {
this.k = k;
this.v = v;
this.next = next;
}
public K getK() {
return k;
}
}
put 逻辑
往Map中插入一个元素,HashMap是如何拿到下标的呢?
在Java 1.7中,put(key, value) 的源码中有以下两行
int hash = hash(key);
int i = indexFor(hash, table.length);
首先将传进来的 key 进行 hash(key) 得到一个 hash 值,再通过 indexFor 算法算出数组下标 i
get同样需要用到这两行代码来获取 key 的数组下标
接下来我们演示下,编译下列代码
HashMap<String, String> hashMap = new HashMap<String, String>();
hashMap.put("水果","苹果");
hashMap.put("蔬菜","菠菜");
hashMap.put("主食","米饭");
hashMap.put("肉类","鸡肉");
hashMap.put("酒水","红酒");
hashMap.put("餐具","刀叉");
for (String key: hashMap.keySet()) {
int hashCode = key.hashCode();
int index = hashCode % 8;
System.out.println(key + "的hashCode是" + hashCode);
}
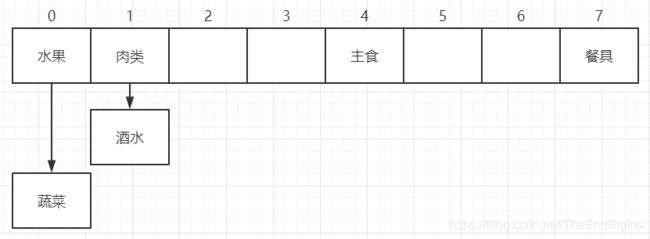
蔬菜 的hashCode是 1090608, index是 0
酒水 的hashCode是 1180962, index是 2
肉类 的hashCode是 1051922, index是 2
水果 的hashCode是 885224, index是 0
餐具 的hashCode是 1235559, index是 7
主食 的hashCode是 659972, index是 4
可以看到蔬菜和水果,酒水和肉类 的 index 是一样的,术语叫做 hash碰撞,这个时候HashMap就会采用 链表 的形式
发生 hash碰撞 的节点,在JDK 1.7中是加入链表的头部,在JDK 1.8中是加入链表的尾部
所以 put 的简化代码应该是这样的
public V put(K key, V value) {
int hash = hash(key);
int i = indexFor(hash, table.length);
addEntry(key, value, i);
}
现在有一种情况就是,如果往上述 hashMap 对象中再插入一个节点会发生什么?
hashMap.put("主食","面条");
这个过程是:
- 传入进来的 key 算出数组下标 i
- 遍历下标 i 的链表,寻找是否有相同的 key
- 无,则插入链表
- 有, 新value 面食 会替代旧value 米饭,并把 旧 value 米饭 返回出来
初始化和下标计算
初始化的时候,有一个默认初始化容器大小值16,默认加载因子0.75
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
static final float DEFAULT_LOAD_FACTORY = 0.75f;
JDK也允许手动传入一个 size 进来,但会根据你传入的size 找到一个刚好大于或等于2的次方 的值作为真正的容器size,意思就是如果你传入的是30,那么容器的真正大小是32,那么JDK为什么要求容器的大小一定要是 2的次方 呢?
原来在源码当中
如果 put 的节点 key 值为 null,实际上也能put成功,只不过会固定放在数组下标为0的位置
而 key 值不为 null 的时候,实际上JDK中还做了很多工作
JDK 1.7 hash() 方法代码
static int hash(int h) {
// ^ :按位异或
// >>>:无符号右移,忽略符号位,空位都以0补齐
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
JDK 1.7 indexFor() 方法代码
static int indexFor(int h, int length) {
return h & (length - 1);
}
JDK为什么要在 hashCode() 后有这么多的右移操作和异或运算呢?h & (length - 1) 又是怎么保证数组下标不越界的呢?
我们来看这个例子,h为一个哈希值,随机取值
h : 1010 0110
15: 0000 1111
& : 0000 0110
由于 length 一定是2的次方,所以 length - 1 的二进制其实都是高位全为0,低位全为1的格式
所以在进行 & 运算的时候,真正决定结果的只有低位,而低位的范围只可能在 length -1 内
并且 h % length == h & (length - 1) 的前提是 length 是 2的次方
这就回答了为什么要求容器的大小一定要是 2的次方,并且 h & (length - 1) 能保证数组下标不越界
而在 hashCode() 后进行多次位操作和异或运算则是防止一些实现较差的hashCode(),也就是减少 hash碰撞
扩容
threshold是衡量数组是否需要扩增的一个标准
threshold = capacity * loadFactor
当 size >= threshold 并且 当前插入的节点位置不为空 的时候,那么就要考虑对数组的扩增了
在之前的hashMap示例图中,capacity 为8,loadFactor 为0.75,也就是说阈值是6
我们现在插入的节点已达到此阈值,满足 size >= threshold 条件
而条件“当前插入的节点位置不为空”(JDK 1.8已去除此条件)的意思是
- 如果此时加入的新节点index为2、3、5、6中的某一个值,则不会扩容
- 如果此时加入的新节点index为0、1、4、7中的某一个值,则会进行扩容
扩容后的size是原先的两倍,重新对所有节点进行rehash迁移
迁移源码
void transfer(Entry[] newTable)
{
Entry[] src = table;
int newCapacity = newTable.length;
//下面这段代码的意思是:
// 从OldTable里摘一个元素出来,然后放到NewTable中
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
在JDK 1.7中这种方式的并发扩容会出现 死锁 的问题
do-while循环中,正常情况是这样的

在并发的情况下,假设有两个线程,分别用红色和浅蓝色代表
- 假设线程一在执行do-while循环第一句的时候被挂起,线程二完成了操作
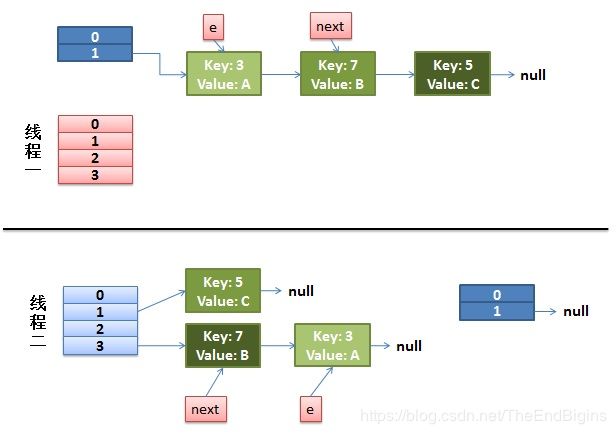
- 线程一被调度回来执行
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
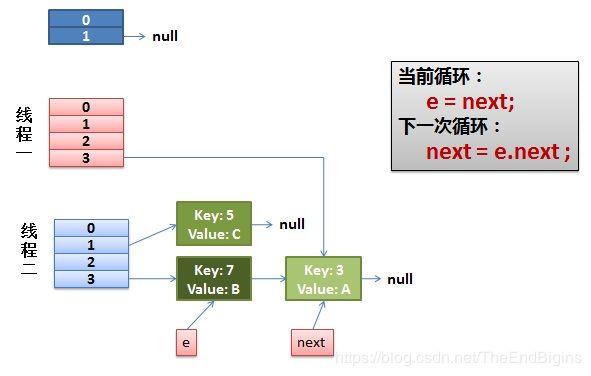
- 线程一接着执行
- 把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移
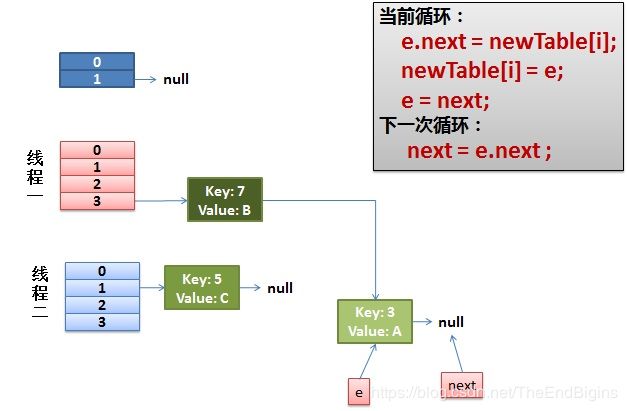
- 把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移
- 环形链接出现
- e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop

图示引用来源https://coolshell.cn/articles/9606.html
JDK 1.8的变化
- 节点 Entry 换了个名字为 Node,源码如下
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
- JDK 1.8 hash() 方法代码,代码简单了很多,但原理是一样的
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 当链表的节点超过8个时则会转化成红黑树,低于6个时则会重新变回链表
static final int TREEIFY_THRESHOLD = 8;
static final float UNTREEIFY_THRESHOLD = 6;
- 扩容机制优化,解决死锁问题
- 如果扩容变化的高位位置对应的hash值是0,那么其实扩容后的位置仍然是原先的位置
- 如果扩容变化的高位位置对应的hash值是1,那些扩容后算出的数组下标肯定跟之前是不同的,并且变化的下标是 原先位置+扩容size
扩展
- ConcurrentModificationException异常
HashMap<String, String> map = new HashMap<String, String>();
map.put("1","1");
map.put("2","2");
for (String key: map.keySet()) {
if (key.equals("1")) {
map.remove(key);
}
}
上述代码在执行的时候会抛出ConcurrentModificationException异常
异常所在的源码是这样的
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
- 分析
- modCount 代表实际修改的次数,expectedModCount 代表只能被修改的次数
- HashMap的源码里每次put操作都会将变量modCount++,而remove操作会导致size–,但是仍然会有modCount++
- 所以上述代码最终导致 modCount = 3, 而 expectedModCount = 2
- 触发 fast-fail 思想,即一旦遇到这个问题就即时的,以最快的速度将这个异常抛出来,终止循环
这个异常也会在多线程编程的时候出现,一个线程在遍历,另一个线程在remove,那么循环的那个线程也会抛出这个异常
- 当HashMap中key为一个实例对象的时候
Person person1 = new Person("小明", "男");
HashMap<Person, String> map = new HashMap<Person, String>();
map.put(person1,"12岁");
System.out.println(map.get(person1));
person1 = new Person("小红", "女");
System.out.println(map.get(person1));
上述代码执行结果
12岁
null
可以看到,当key值中的实例对象改变的时候,HashMap是拿不出原先key值对应的value的,所以这也是我们编码时需要注意的地方,应该将 person1 对象定义成 final,防止被修改
- 最后一个小tips,如果在创建HashMap的时候明显知道容器大小使用默认初始化大小16时必定发生扩容的情况下,最好手动设置容器大小,提高效率