从查准率、查全率到ROC、AUC (含Python实现)
目录
前言:先看一个经典的例子:
1 查准率与查全率
2 F1_score
3 ROC及代码实现
4 AUC 及代码实现
4.1 AUC简介
4.2 AUC的几何意义和概率意义
4.3 AUC判断分类器(预测模型)优劣的标准:
4.4 AUC的计算方法:
前言:
先看一个经典的例子:
目的:设计一个分类器类分类患者的肿瘤是不是良性的
数据集:我们有10000个样本,其中9995个是良性的,只有5个人是恶性的。
如果我们只关注预测的错误率的,我们可以设计模型无论什么样本输入,全部输出良性。此时的准确率是99.95%,是不是很满意呢?但这种模型根本没有用。所以说对于数据的类别存在偏析的情况,不能只看错误率。
因此出现了查准率、查全率、ROC、AUC...
1 查准率与查全率


1. 正确肯定(True Positive,TP):预测为1,实际为1
2. 正确否定(True Negative,TN):预测为0,实际为0
3. 错误肯定(False Positive,FP):预测为1,实际为0
4. 错误否定(False Negative,FN):预测为0,实际为真1
举个例子:有8个数据,求混淆矩阵

混淆矩阵如下:
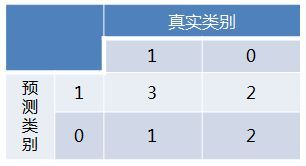
查准率Precision(也叫准确率)表示 你预测为正的样本中(TP+FP)有多少是真正的正样本(TP)(因为还有一些你错误的预测为正样本(FP)

查全率(Recall),又叫召回率,缩写表示用R。查全率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确。
例如,我们建的全预测为良性的模型,恶性肿瘤的样本一个都没有被预测出来,因此查全率为零
 。
。
查准率和查全率是一对矛盾的度量。一般来说,查准率高时,查全率往往偏低;而查全率高时,查准率往往偏低。很难获得查准率和查全率都很高的算法。为什么会有这样的情况呢?
举个栗子:
有一车西瓜,其中有好瓜和坏瓜。如果你想获得查准率很高,那你完全可以挑那些最有把握的好瓜,分数会很高甚至获得100%。但同时另外那些好瓜被挑出来的就少了,因此查全率也就降低了。你挑出的好瓜数量就是一个阈值,你降低阀值,你不止挑最有把握的,模棱两可的也挑了,因此Recall提高,Precision降低。反之,提高阀值,Precision提高,Recall降低。
2 F1_score
传统的f1_score 是precision和recall的调和平均数

更加一般的表示,含有正实数β:


3 ROC及代码实现
ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。
- TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。真正率
- FPR:在所有实际为阴性的样本中,被错误地判断为阳性之比率。假正率
ROC 曲线用于绘制采用不同分类阈值时的 TPR 与 FPR。降低分类阈值会导致将更多样本归为正类别,从而增加假正例和真正例的个数。下图显示了一个典型的 ROC 曲线。

不同分类阈值下的 TP 率与 FP 率。
从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。

在A、B、C三者当中,最好的结果是A方法。
B方法的结果位于随机猜测线(对角线)上,在例子中我们可以看到B的准确度(ACC,定义见前面表格)是50%。
C虽然预测准确度最差,甚至劣于随机分类,也就是低于0.5(低于对角线)。然而,当将C以 (0.5, 0.5) 为中点作一个镜像后,C'的结果甚至要比A还要好。这个作镜像的方法,简单说,不管C(或任何ROC点低于对角线的情况)预测了什么,就做相反的结论。
例如,如果你有一个预测股票涨或跌的分类器,错误率是95%的话,请告诉我。
关于ROC曲线的Python代码,点这里
4 AUC 及代码实现
4.1 AUC简介
AUC是一个模型评价指标,只能用于二分类模型的评价
为了计算 ROC 曲线上的点,我们可以使用不同的分类阈值多次评估逻辑回归模型,但这样做效率非常低。幸运的是,有一种基于排序的高效算法可以为我们提供此类信息,这种算法称为曲线下面积 AUC(Area under the Curve of ROC )。
曲线下面积测量的是从 (0,0) 到 (1,1) 之间整个 ROC 曲线以下的整个二维面积

AUC值越大的分类器,正确率越高。
4.2 AUC的几何意义和概率意义
AUC的 几何意义ROC曲线下的面积。
概率学上的意义:随机选取一个正例和一个负例,分类器给正例的打分大于分类器给负例的打分的概率。
想深度了解AUC的数学原理,可以参考这里
4.3 AUC判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。

4.4 AUC的计算方法:
1.梯形法:计算各个小矩形的面积之和
2. 概率法:简单来说其实就是随机抽出一对样本(一个正样本,一个负样本),然后用训练得到的分类器来对这两个样本进行预测,预测得到正样本的概率大于负样本概率的概率。

想了解AUC的纯Python代码实现,请看我