RCNN Fast RCNN到Faster RCNN
https://blog.csdn.net/u011974639/article/details/78053203
这位大神的讲解非常细。
然后发现CS231n 2016中lecture8就有对于从RCNN Fast RCNN到Faster RCNN的详细讲解。
一、R-CNN
下面给出训练R-CNN的过程。
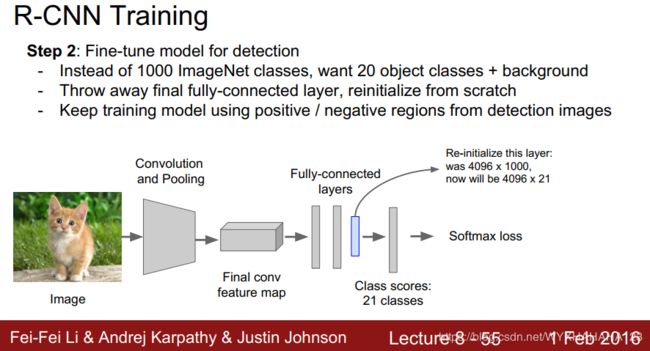
step1&step2:准备用于fine-tune CNN的region proposal和对pretrained CNN进行fine-tune
首先使用selective search算法,对于训练数据集中的每张输入图像应用SS算法,提取出图像中的region proposal(候选框),其中region proposal并不区分框中物体的类别,它只区分前景和背景,selective search算法会根据输入图像的纹理,边缘等外观特征,通过传统的图像处理算法对于每张输入图像输出大约2000个region proposal/candidate 的坐标信息,这些框可以认为是前景候选框,但是它们实际的ground truth 类别可能是背景或者前景类别中的任意一种。然后根据selective search算法输出的坐标信息就可以从训练图像上抠取出对应的image patch图像块。由于需要使用这些图像块训练CNN classifier(其中包含有fully connected layer),故而需要输入到CNN中的图像块具有相同且固定的空间分辨率,在这里使用warped操作(可以理解成cv2.resize)直接将图像块(region proposal对应的原始图像)resize到227*227。然后将这些warped好的图像块存到磁盘中(这里的是否存储是我认为比较方便的操作,不过paper中并没有提到要存储图像块,而是只提到了存储每个图像块所对应的特征想向量),作为fine-tune CNN的训练图像。
现在需要训练的CNN模型是很传统的classification convolutional neural network,比如Alexnet,resnet,首先从网上下载在ImageNet数据集上已经训练好的网络模型权值文件,注意ImageNet数据集包含1000个类别,而现在我们使用的物体检测测数据集可能不是这个类别数,记作num_classes,则需要将分类网络的softmax层(也就是最后一层/倒数第二层全连接层)的输出神经元个数从1000+1变成num_classes+1,注意,在开始进行fine-tune之前,只有最后一层全连接层的参数是随机初始化的,前面的所有CNN卷积层和全连接层都是使用的在ImageNet分类任务上训练好的模型参数。
既然要使用从原始图像数据集上抠取下来的图像块作为训练分类网络的训练数据,则需要给每个图像块打上类别标签,设定IOU阈值为0.5,在原始图像中,计算selective search算法起初出来的当前region proposal与图像中所有ground truth boxes之间的IOU并取出IOU的最大值,如果IOU最大值大于0.5,则当前图像块的标签为该类别,否则为背景。
训练fine-tune classification network的参数设置:
输入图像分辨率 227*227.
batch size:128
(其中在每个iteration中,随机地采样出32个正样本图像块和96个负样本图像块,这个比例也被沿用到了faster RCNN中的RPN以及SSD中的classification loss计算,都是正负样本1:3的采样,这是因为显然正负样本会存在严重的类别不平衡,背景负样本的数量远远多于前景正样本)
learning rate 0.001
optimizer SGD
loss:multiple class cross entropy loss (softmax + cross entropy)

实际上这里的训练与传统的分类任务的训练区别之处主要在于:分类任务输入的是完整的原始图像,而检测任务输入的是一个图像块(或者认为是一个包围框),需要对框中的物体进行前景多个类别或者背景的划分。
step3:从训练好的classification network中提取输入region proposal所对应的特征向量并存储

将刚才存储在磁盘中的一个个图像块(这些图像块的来源:对于一张原始输入图像应用selective search算法提取出大约2000个region proposal,然后将每个region proposal通过warp操作都resize到227*227)送入刚才训练好的CNN分类网络中,并提取pool5的特征(output stride=32,要记住,32是大部分经典分类网络的output stride),将一个个图像换转换成一个个固定长度的特征向量,特征向量维度为4096维,将这些特征向量保存到磁盘中,以作为后面SVM classifier和bounding boxes regressor的训练数据集输入数据。
step4 根据对于每个region proposal提取好的特征向量训练SVM分类器
需要训练num_classes个SVM,也就是说对于每个前景类别,都要训练一个SVM classifier,以判断当前的region proposal feature vector是否属于当前前景类别。
SVM的训练数据集:训练数据即固定维度4096维的特征向量,其对应的标签与fine-tune CNN classifier 的方式略有不同
选取与ground truth boxes IOU大于0.7的region proposal为该前景类别的正样本,IOU小于0.3的为负样本。
这些0.5 0.7 IOU阈值选择都是根据实验调参出来的经验值,可能对于不同的数据集,最优参数会不同。
step5 bounding boxes regression训练(线性回归,最小二乘)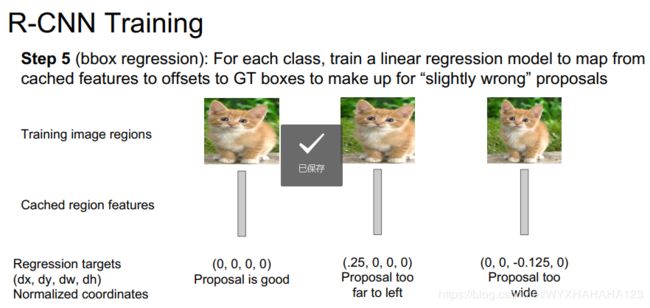
注意:对于每个前景类别,都要分别训练一个bbox regressor,也就是说,classification SVM和linear regressor都具有class specific 性。
训练bbox regressor的训练数据集:
输入数据:固定长度的特征向量 batch_size*2000*4096
标签生成:由于所希望回归器所预测出来的是region proposal(即在输入图像上根据selective search算法生成的)相对于ground truth boxes的偏移量而并不是绝对坐标数值,从其对于位置坐标ground truth boxes的编码原理可以看出,希望回归其所预测出来的数值是:将region proposal经过怎样的平移变换和尺度缩放变换,才能得到ground truth boxes,故而需要原本的region proposal就很接近ground truth boxes,因此在训练回归器时,需要增大正样本的IOU阈值。也就是说,训练某个前景类别的位置回归器,必须要求region proposal本身就与ground truth boxes非常接近,然后再对当前region proposal的回归ground truth 值进行编码。故而参与到linear regressor训练过程中的每个region proposal都有唯一一个ground truth boxes的位置坐标与之对应。具体编码方式如下:



需要注意的是,这里的编码方式与fast RCNN,faster RCNN包括后面的one stage method都有很大相似,但是后面的RPN或者是一个阶段的检测器,其对于ground truth boxes编码时所根据的基准并不是region proposal,而是anchor boxes,anchor boxes与region proposal的区别还是非常大的,生成anchor boxes所需要的输入信息仅仅包括当前特征图空间分辨率以及所需要生成的anchor面积和宽高比,并没有借助任何先验的额外信息,也并没有很强的概率倾向说当前的anchor boxes锚框是前景框还是背景框,而region proposal必须是借助了一定的图像先验信息(selective search算法)或者是网络参数所预测出(包含有网络参数信息)的被认为有很大概率是前景包围框的候选框。
RCNN测试阶段

RCNN优缺点分析
准确率比传统的物体检测方法高出接近20%,缺点是检测速度慢,时间复杂度很高,同时存储每个region proposal的特征向量的存储空间复杂度也很高。
R-CNN是要将原始输入图像每个region proposal都送入CNN网络中进行特征提取,故而称为基于区域的卷积神经网络(region based CNN)

二、SPPNet(spatial pyramid pooling network空间金字塔池化)
1.spatial pyramid pooling layer用于image classification
SPPnet是对于R-CNN模型的改进。这篇文章来自于kaiming。对于传统的卷积神经网络分类器(如Alexnet),它们还并没有引入global average pooling layer,而是直接将卷积-pooling-卷积-pooling-……结构的输出特征图flatten成一维特征向量,然后再接全连接层,最后加上softmax层计算损失函数,故而带有全连接层时必须要求输入图像的空间分辨率固定(比如必须设置成224*224,然后分类网络一般的output stride = 7 ,然后进行7*7的平均池化,得到特征向量,最后送入全连接层),当然后续的卷积神经网络分类器(如resnet),则并不需要将输入图像的分辨率设置成为固定值,这是因为在convolution stage和fully connected layer之间引入了global average pooling全局平均池化(其实之前的7*7平均池化也可以看作是在那样输入分辨率下的全剧平均池化),将conv5输出特征图进行全局平均池化,得到维度为conv5特征图输出通道数的特征向量,再送入后面的全连接层。
resnet的model.py中前向传播的代码
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x=self.conv5(x)
x=self.bn5(x)
x = self.avgpool(x)#self.avgpool = nn.AdaptiveAvgPool2d((1, 1))#N*1*1
print('in forward avgpool', x.shape)#[batch_size,channel_num,1,1]但是在从conv_stage——flatten——fc layer到conv_stage——global average pooling——fc layer之间发展了很多个阶段,其中有一个阶段就是SPPNet,空间金字塔网络并不像后面的残差网络直接进行全局平均池化,而是对于最后一个卷积阶段(最后一个操作可能是卷积,也可能是池化)的输出特征图进行spatial pyramid pooling,即设定网格尺寸,(论文中的实验在分类任务中设置的网格尺寸是6*6),即conv_stage——spp pooling layer——flatten——fc layer,flatten操作后的特征向量维度为(grid_size*grid_size*num_feature_channels),这就是SPPNet用于分类网络的网络结构。在训练分类任务时,还是使用在ImageNet classification task分类任务上的预训练参数,然后fine-tune网络,以softmax作为损失函数。为了提高最终的分类准确率,首先训练好带有空间金字塔结构的分类网络,然后将空间金字塔层输出的特征向量提取出来训练多个类别的SVM分类器。
SPP空间金字塔层应该加在分类网络最后一个卷积层之后,即卷积层和全连接层中间。

在基于卷积神经网络的分类器中,可以将CNN卷积阶段看作对于输入图像的特征提取器(feature extractor),提取到的特征送入softmax分类器或者SVM分类器,但是无论是softmax还是SVM,其所需要的输入特征向量都是固定维度的,对于分类任务而言,可以直接对于卷积网络最后一个卷积层输出的特征图进行global average pooling,以得到维度等于最有一个卷积层卷积核个数的特征向量,这样的全局平均池化对于classification task而言是没有问题的,因为分类任务的输出结果并不会受到object在图像中的位置的影响,比如:图像中有一只狗,则分类器的target value就是狗,无论狗处于图像中的哪个位置,分类器的ground truth值不会发生改变,但是对于物体检测任务而言,它的ground truth就是包围框的位置,故而需要特征中包含丰富的空间位置信息,这一信息刚好会被全局平均池化所损失,故而作者提出空间金字塔池化以代替全局平均池化,保留输入图像的空间位置信息。当然全局平均池化也可以放到分类网络中去,放在最后一个卷积层后面。

第5个阶段的卷积特征图通道数为256记作k,设定使用3层空间金字塔池化,总bins数为M,M=4*4+2*2+1*1=21,则经过SPP pooling layer后输出的特征向量维度为k*M,然后再将这个固定维度的特征向量送入全连接层。
这就是SPPnet的特点之一——可以接受任意尺寸的输入图像。SPPnet的另一个创新点就是对于R-CNN特征提取部分的加速。
2.SPPNet用于object detection
SPPnet对于R-CNN中特征提取部分的加速:
在R-CNN模型中,对于输入图像中的2000个region proposal,需要将每个region proposal都分别送入到卷积神经网络中提取候选框中图像块的卷积特征,这一过程非常消耗时间,而且很多region proposal会有相互重叠的部分,故而会带来很多重复的计算。SPPnet对于RCNN在物体检测的改进主要在于提升了速度,准确率相当(并没有提高多少),将同一张输入图像的2000个region proposal的卷积特征提取进行了共享计算。先将整个图像送入到卷积网络中提取到关于整个输入图像的卷积特征图,然后将在输入图像空间分辨率上的region proposal坐标映射到特征图上(根据特征图相对于原始输入图像的output stride),再从特征图上抠取出相应region proposal的特征块,然后对于特征块进行spp pooling空间金字塔池化,得到固定维度的特征向量(由于使用了空间金字塔池化,将会比直接的全局平均池化保留更多的空间位置信息,更有利于进行物体检测任务),将每个region proposal对应的特征向量送入后续的SVM分类器和bbox regression,从而不需要对于每个region proposal都重复地融入CNN中提取特征,极大提高了训练速度。
SPPnet与RCNN前向传播的流程完全一致,模型的结构区别主要在于以下两点:
(1)RCNN是将每个region proposal都送入到卷积网络中分别提取每个候选框的卷积特征,SPPNet则是将整个图像送入到卷积网络中提取特征,减少了CNN冗余计算
(2)无论是直接从原始图像上抠取region proposal送入卷积网络提取特征,或者是先将整个图像送入CNN提取特征之后再在特征图上进行抠图,现在都能够得到某个region proposal所对应的特征块,RCNN通过全连接层将特征快映射为固定维度的特征向量,而SPPNet则通过空间金字塔池化将region proposal对应的特征块转换为固定维度的特征向量。
在从特征图上抠取region proposal所对应的特征块时,为了计算简便,对于卷积网络的滤波器参数做如下的设计:假设某一层卷积核的kernel size记作k,则padding= k/2 然后向下取整,比如卷积核尺寸为3*3,则padding = 1,如果卷积核尺寸为1*1,则padding = 1,这样做的原因如下:
假设当前层特征图的分辨率为F1,下一层特征图分辨率为F2,则卷积计算公式为:
F2=[(F1-kernel_size)+2*padding]/stride +1
可以发现现在大多输出的分类网络卷积步长都为1,通过max pooling操作进行特征图的下采样,此时如果padding = k /2 ,则F2=F1,即卷积操作不会改变特征图的分辨率,则特征图的output stride完全由pooling操作所决定,通常分类网络的output stride=32,则比如region proposal在输入图像上的坐标值为(x,y,w,h),则对应到特征图上每个坐标值都要除以output stride。从而可以从特征图上抠取出region proposal所对应的特征块。
然后进行空间金字塔池化,送入SVM和regression中进行训练。
三、Fast RCNN(对于SPPNet改进,将SPP层改成ROI pooling)
我别的博客已经说的很详细了,以后有时间再来简单总结下。