Ubuntu16.04下搭建Hadoop分布式集群
最近在搭建Hadoop集群,总结一下。
参考网址:
Hadoop集群搭建教程(详细)
Hadoop分布式集群搭建hadoop2.6+Ubuntu16.04
首先我在VMware Workstations下弄了三台Ubuntu的虚拟机,但是IP地址问题搞了很久,由于IP地址相同导致不能ping通外网。一开始我是先按照Ubuntu正常安装流程装好了一个,然后我就直接复制粘贴,弄了第二、三台,然后发现在终端输入ifconfig后,这三台显示的IP地址是相同的,然后Inet6 address也是相同的,并且叠加(即第一台只有一个Inet6 address,可以正常上网;第二台有两个Inet6 address,并且是相同的;第三台有三个相同的Inet6 address;第二台和第三台并不能上网)。后面我就利用VMware的虚拟机克隆,克隆出第二,三台,然后根据这个网址,修改了虚拟机的MAC地址,重启后IP地址真的就不一样了。
所以现在就有了三台IP地址不同的Ubuntu,并且这三台上面都是装有JDK1.8的(Ubuntu安装JDK1.8戳这里),接下来就开始搭建集群,分以下几步:
一、配置hosts文件,并关闭虚拟机的防火墙
二、配置ssh免密码连入
三、下载并解压hadoop安装包
四、配置 /etc/hadoop目录下的几个文件及 /etc/profile
五、格式化namenode并启动集群
一、配置hosts文件
对每台虚拟机主机名进行修改,来进行区分一个主节点和两个从节点。
修改主机名命令:

我把三台虚拟机分别命名 主节点:master 从节点1:node1 从节点2:node2,修改完后重启虚拟机才会生效。
(也可以使用gedit /etc/hostname直接在编辑器里修改)
接下来,分别查看三台虚拟机的ip地址,命令如下:
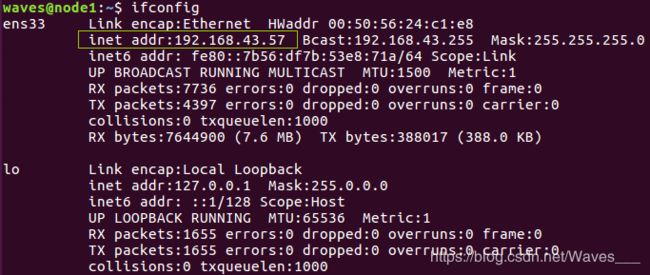
就是在这搞了半天,就为了弄三个不同的IP地址。。inet addr就是这台虚拟机的IP地址。
接下来打开hosts文件 进行修改:
![]()
将三台虚拟机的ip地址和主机名加在里面,其它的不用动它。
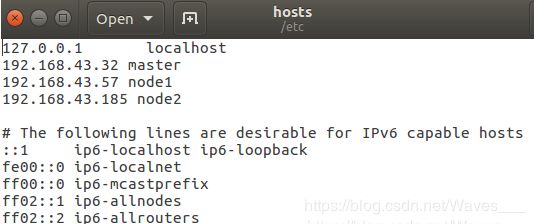
三台虚拟机都要修改hosts文件。简单的说配置hosts后三台虚拟机就可以进行通信了,可以互相ping一下试试,是可以ping通的。如下图:

然后就是关闭虚拟机的防火墙。
一般来说,ubuntu默认都是安装防火墙软件ufw的,使用命令 sudo ufw version,如果出现ufw的版本信息,则说明已有ufw。
使用命令 sudo ufw status查看防火墙开启状态:如果是active则说明开启,如果是inactive则说明关闭。
开启防火墙
sudo ufw enable
关闭防火墙
sudo ufw disable这里我们关闭防火墙 sudo ufw disable。每台虚拟机都要。
二、配置ssh免密码连入
开始配置ssh之前,先确保三台机器都装了ssh。输入以下命令查看安装的ssh。
#查看ssh安装包情况
dpkg -l | grep ssh
#查看是否启动ssh服务
ps -e | grep ssh截图如下:

![]()
如果系统中并没有ssh服务,可以使用以下指令来安装ssh服务(建议有的也再安装一遍)
sudo apt-get install openssh-server 三台虚拟机都安装完毕之后开始配置ssh,步骤如下:
①在master机上输入以下命令,生成master机的一对公钥和私钥:
![]()
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa-P为设置密码,此处需要设置为空,即'',才能有免密效果
②然后,下面的命令将公钥加入到已认证的key中:
![]()
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys进入.ssh目录,可以看到以下文件:
![]()
然后输入ssh localhost 登录本机命令,第一次提示输入密码,输入exit退出,再次输入ssh localhost不用输入密码就可以登录本机成功,则本机ssh免密码登录已经成功。
③将.ssh目录复制到node1和node2两台虚拟机去。(其实只用复制authorized_keys到另外两台虚拟机下的.ssh目录下就行了,但是另外两台还没创建.ssh目录,因此为了方便直接把.ssh目录复制过去)
![]()
![]()
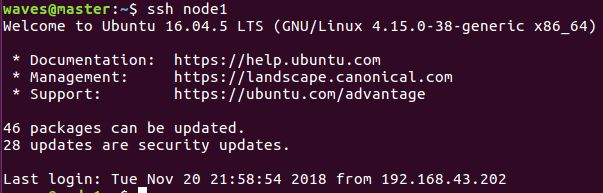
④在master机上验证
输入ssh node1不需要密码登录成功,说明ssh免密码登录配置成功!
三、下载并解压hadoop安装包
下载Hadoop安装,直接上官网进行下载,http://mirrors.hust.edu.cn/apache/hadoop/core/,我下载的是Hadoop2.7.7版本
将hadoop压缩包,解压到 master主机 的一个文件夹里面,我这里解压到了home文件夹(推荐),并修改文件夹名为hadoop2.7。所在的目录就是 hadoop_path = /home/waves/hadoop2.7
四、配置 /etc/hadoop目录下的几个文件及 /etc/profile
主要有这8个文件需要修改(我的 hadoop_path = /home/waves/hadoop2.7):
hadoop_path/etc/hadoop/core-site.xml
hadoop_path/etc/hadoop/hadoop-env.sh
hadoop_path/etc/hadoop/hdfs-site.xml
hadoop_path/etc/hadoop/mapred-site.xml.template
hadoop_path/etc/hadoop/slaves
hadoop_path/etc/hadoop/yarn-env.sh
hadoop_path/etc/hadoop/yarn-site.xml
/etc/profile
不过在修改之前,需要先创建以下文件夹:
- /home/waves/hadoop2.7/hdfs
- /home/waves/hadoop2.7/hdfs/tmp
- /home/waves/hadoop2.7/hdfs/name
- /home/waves/hadoop2.7/hdfs/data
在后面配置文件中的一些路径,要与这些文件夹的路径相对应。
1、core-site.xml修改如下(这有个坑就是这里面的代码缩进要正确,所以如果是要复制下面的代码到虚拟机中,要重新弄好缩进):
hadoop.tmp.dir
/home/waves/hadoop-2.7/hdfs/tmp
A base for other temporary directories.
io.file.buffer.size
131072
fs.defaultFS
hdfs://master:9000
解释下:第一个hadoop.tmp.dir配置Hadoop的一个临时目录,用来存放每次运行的作业jpb的信息。
2、修改hadoop-env.sh ,添加java安装的地址
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use.
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_1913、接下来hdfs-site.xml的修改:
dfs.replication
2
dfs.namenode.name.dir
/home/waves/hadoop-2.7/hdfs/name
true
dfs.datanode.data.dir
/home/waves/hadoop-2.7/hdfs/data
true
dfs.namenode.secondary.http-address
master:50090
dfs.webhdfs.enabled
true
dfs.permissions
false
解释下: dfs.replication 设置文件副本数,这里两个datanode,所以设置副本数为2。
dfs.namenode.name.dir是namenode存储永久性的元数据的目录列表。这个目录会创建在master机上。
dfs.datanode.data.dir是datanode存放数据块的目录列表,这个目录在node1和node2机都会创建。
4、复制mapred-site.xml.template文件,并命名为mapred-site.xml
![]()
修改 mapred-site.xml,如下:
mapreduce.framework.name
yarn
mapred.job.tracker
master:9001
5、接下来修改slaves文件

这里将两台从主机的主机名node1和node2加进去就可以了。
6、修改yarn-env.sh文件
将其中的JAVA_HOME修改为本机JAVA_HOME路径(先把这一行前面的#注释符去掉)

7、修改yarn-site.xml文件
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
8、修改/etc/profile文件 ,如下进入profile:
![]()
添加hadoop路径在末尾:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_191
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export HADOOP_INSTALL=/home/waves/hadoop-2.7
export PATH=${HADOOP_INSTALL}/bin:${HADOOP_INSTALL}/sbin:$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
export HADOOP_CONF_DIR=${HADOOP_INSTALL}/etc/hadoop修改完后重启虚拟机生效,或者输入以下指令立即生效:
![]()
注意此时前面字母的颜色变为白色了。
检查下是否可以看到hadoop版本信息:
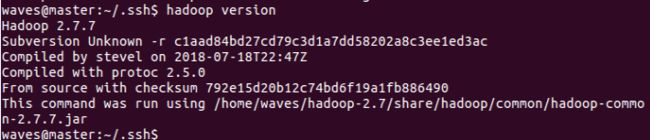
9、在master主机中修改完hadoop2.7文件夹中的配置文件后,将hadoop2.7文件夹复制到node1和node2节点的相同位置。注意,必须是相同的位置!!如下图:
![]()
![]()
这一步非常重要!!!!
五、格式化namenode并启动集群
①输入 hdfs namenode -format
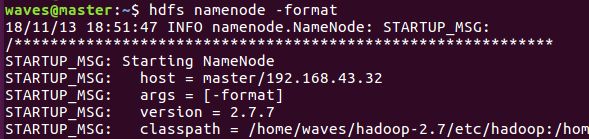
过程需要进行ssh验证,但是之前已经免登录了。
成功的截图如下:
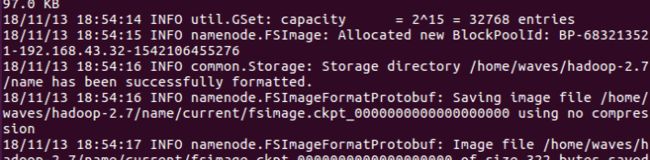
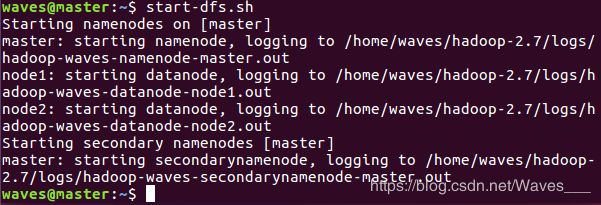
②开启hadoop,先输入start-dfs.sh
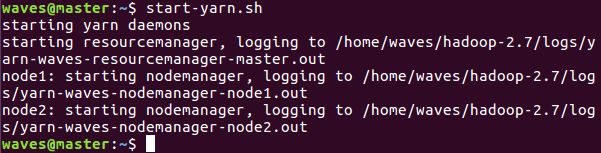
然后输入start-yarn.sh
③输入jps查看进程消息
master下:
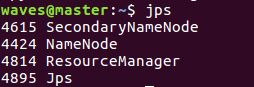
node1和node2:

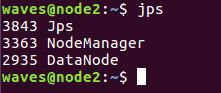
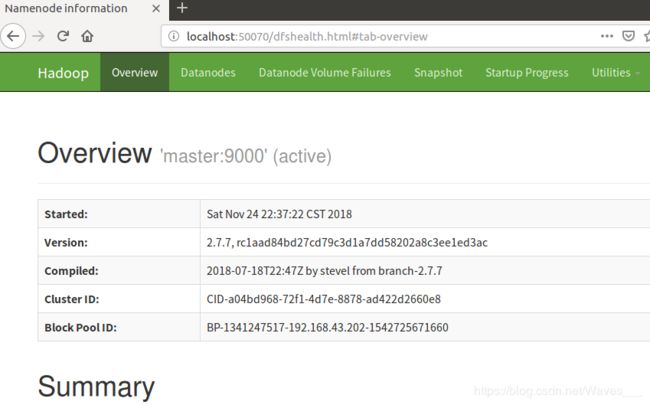
④查看Web UI
在浏览器中输入http://localhost:50070,即可查看相关信息,截图如下:
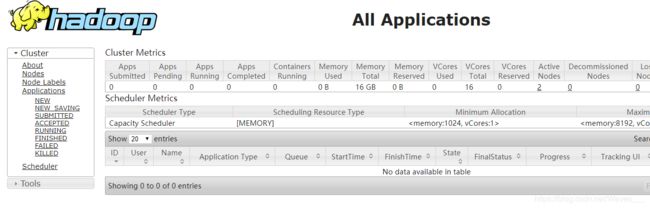
在浏览器中输入http://192.168.43.32:8088,截图如下:
(192.168.43.32为master的IP地址,改为你的master的IP地址)
hadoop集群搭建完成