开窗函数详解(rank()、dense_rank()、row_number())
首先,我们新建一张表,并且往里面插入一堆测试数据:
Create Table #Student(StudentID int, Subjects Nvarchar(10),Score int)
Insert into #Student
Select 1 ,'Chiness',90 Union all
Select 2 ,'Chiness',91 Union all
Select 3 ,'Chiness',89 Union all
Select 4 ,'Chiness',80 Union all
Select 5 ,'Chiness',95 Union all
Select 1 ,'Math',100 Union all
Select 2 ,'Math',86 Union all
Select 3 ,'Math',99 Union all
Select 4 ,'Math',80 Union all
Select 5 ,'Math',60 Union all
Select 1 ,'English',70 Union all
Select 2 ,'English',88 Union all
Select 3 ,'English',96 Union all
Select 4 ,'English',81 Union all
Select 5 ,'English',79
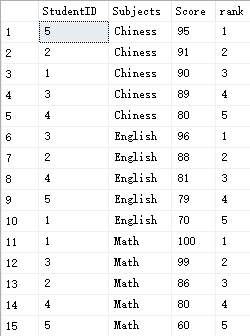
下面要汇总出每门学科的学生排行信息:
Select *,rank()over(partition by subjects order by score desc) as [rank] from #Student
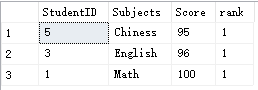
接着,根据这个结果,我想要查找出每门学科第一的学生:
WITH A AS(
Select *,rank()over(partition by subjects order by score desc) as [rank] from #Student
)SELECT * FROM A WHERE [rank]=1
结果如下:
在这里,要纠正一个错误,本来我是这么写的,结果报错了:
Select *,rank()over(partition by subjects order by score desc) as [rank] from #Student
WHERE rank()over(partition by subjects order by score desc)=1
报错信息是:开窗函数只能出现在 SELECT 或 ORDER BY 子句中。
这一点要注意咯~~
下面,汇总每个学生的学科排行信息:
Select *,rank()over(partition by studentid order by score desc) as [rank] from #Student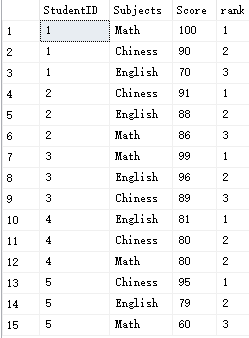
根据这个汇总信息我想要查找“数学”相对自己其他学科比较弱需要加强的都有哪些人:
WITH A AS(
Select *,rank()over(partition by studentid order by score desc) as [rank] from #Student
)SELECT * FROM A WHERE SUBJECTS='MATH' AND RANK=3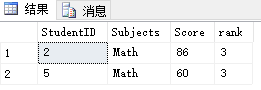 1
1
下面,我们再来汇总一下全部学生的总分排行情况::
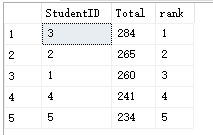
最后,来对比一下rank()、dense_rank()、row_number()这三者之间的区别:
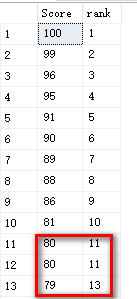
rank ():如图1
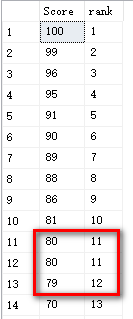
dense_rank(): 如图2
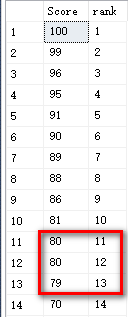
row_number():如图3
当排序过程当中出现重复相同值的时候,这三者的区别显而易见~~