(三)快速图像风格转换代码解析
系列文章
(一)图像风格迁移
(二)快速图像风格转换
(四)快速图像风格迁移训练模型载入及处理图像
整体架构:
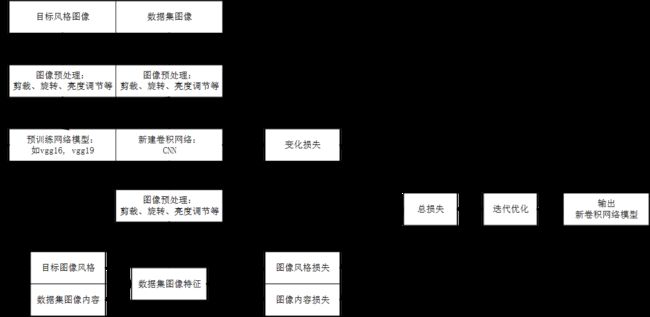
1 源码文件结构
|-- conf
|-- eval.py
|-- export.py
|-- generated
|-- img
|-- losses.py
|-- model.py
|-- model.pyc
|-- models
|-- nets
| |-- __init__.py
| |-- nets_factory.py
| |-- vgg.py
|-- preprocessing
| |-- vgg_preprocessing.py
|-- pretrained
|-- process
|-- reader.py
|-- requirements.txt
|-- resize_process_image.py
|-- resized_image
|-- stylerun.py
|-- stylerunbase64.py
|-- train.py
`-- utils.py
2 train训练
风格转换训练包含了所有转换步骤,有图像风格特征提取,图像内容损失提取,图像风格损失提取,图像内容和风格损失融合等过程,下面针对训练解析各个过程.
【运行】
python/python3.x train.py -c conf/candy.yml
【train.py】
def main(FLAGS):
'''目标图像:slim-VGG结构提取图像风格特征'''
style_features_t = losses.get_style_features(FLAGS)
'''模型路径检查,若不存在,则新建路径'''.
training_path = os.path.join(FLAGS.model_path, FLAGS.naming)
if not(os.path.exists(training_path)):
os.makedirs(training_path)
'''新建图'''
with tf.Graph().as_default():
with tf.Session() as sess:
"""获取预训练网络结构:vgg_16"""
network_fn = nets_factory.get_network_fn(
FLAGS.loss_model,
num_classes=1,
is_training=False)
'''预处理图像:返回图像处理函数.'''
image_preprocessing_fn, image_unprocessing_fn = preprocessing_factory.get_preprocessing(
FLAGS.loss_model,
is_training=False)
'''
数据集图像预处理:读取图像内容
处理过程:裁剪,旋转,去均值(RGB-RGB_mean)即图像数字化
'''
processed_images = reader.image(FLAGS.batch_size, FLAGS.image_size, FLAGS.image_size,
'train2014/', image_preprocessing_fn, epochs=FLAGS.epoch)
'''
新建神经网络处理图像,获取图像信息
训练该神经网络,通过该网络处理图像,
再通过slim-vgg处理,计算两个神经网络间处理图像的损失,
使损失按照比例达到最优,即实现了新建网络的训练;
还原归一化的图像,输出最终的图像组,
即生成: Tensor("Slice_1:0", shape=(4, 256, 256, 3), dtype=float32)
处理过程: (image+1)*127.5
'''
generated = model.net(processed_images, training=True)
'''
对处理过的图像进行二次处理
处理过程:减去RGB对应的均值.
'''
processed_generated = [image_preprocessing_fn(image, FLAGS.image_size, FLAGS.image_size)
for image in tf.unstack(generated, axis=0, num=FLAGS.batch_size)
]
processed_generated = tf.stack(processed_generated)
'''
将第一次处理和第二次处理的图像进行级联,slim-vgg获取网络结构,这解释了生成的图像shape:[8, 256, 256, 64]
processed_generated:经过新建神经网络NN处理生成图像,(image+1)*127.5和一次均值计算(RGB-RGB_mean)
processed_images:数据集图像读取,获取图像信息,整理数据为训练的batch及shuffle
endpoints_dict:神经网络命名空间
'''
'''
network layers:
OrderedDict([('vgg_16/conv1/conv1_1', ),
('vgg_16/conv1/conv1_2', ),
('vgg_16/pool1', ),
('vgg_16/conv2/conv2_1', ),
('vgg_16/conv2/conv2_2', ),
('vgg_16/pool2', ),
('vgg_16/conv3/conv3_1', ),
('vgg_16/conv3/conv3_2', ),
('vgg_16/conv3/conv3_3', ),
('vgg_16/pool3', ),
('vgg_16/conv4/conv4_1', ),
('vgg_16/conv4/conv4_2', ),
('vgg_16/conv4/conv4_3', ),
('vgg_16/pool4', ),
('vgg_16/conv5/conv5_1', ),
('vgg_16/conv5/conv5_2', ),
('vgg_16/conv5/conv5_3', ),
('vgg_16/pool5', ),
('vgg_16/fc6', ),
('vgg_16/fc7', ),
('vgg_16/fc8', )])
'''
_, endpoints_dict = network_fn(tf.concat([processed_generated, processed_images], 0), spatial_squeeze=False)
# 损失网络日志结构
tf.logging.info('Loss network layers(You can define them in "content_layers" and "style_layers"):')
for key in endpoints_dict:
tf.logging.info(key)
"""计算数据集图像内容损失
提取图像内容网络层:vgg_16/conv3/conv3_3
vgg_16提取图像内容:提取数据集图像内容特征
新建网络提取图像特征
对两个特征计算损失,使新建网络具备提取图像内容的能力
"""
content_loss = losses.content_loss(endpoints_dict, FLAGS.content_layers)
'''计算目标图像风格损失
提取图像风格特征网络层:- "vgg_16/conv1/conv1_2"
- "vgg_16/conv2/conv2_2"
- "vgg_16/conv3/conv3_3"
- "vgg_16/conv4/conv4_3"
vgg_16提取目标图像风格特征:style_features_t
新建网络提取数据集图像特征
两个特征计算损失,使新网络具备提取图像风格的能力
'''
style_loss, style_loss_summary = losses.style_loss(endpoints_dict, style_features_t, FLAGS.style_layers)
'''全部变量损失'''
tv_loss = losses.total_variation_loss(generated)
'''目标图像风格,数据集图像内容和风格损失及变量损失的综合损失,依据不同比例银子进行计算.'''
loss = FLAGS.style_weight * style_loss + FLAGS.content_weight * content_loss + FLAGS.tv_weight * tv_loss
"""
准备训练
定义训练步数变量,该变量不可训练,用于记录训练的轮数
"""
global_step = tf.Variable(0, name="global_step", trainable=False)
'''定义可训练变量'''
variable_to_train = []
for variable in tf.trainable_variables():
if not(variable.name.startswith(FLAGS.loss_model)):
variable_to_train.append(variable)
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss, global_step=global_step, var_list=variable_to_train)
'''定义保存的变量'''
variables_to_restore = []
for v in tf.global_variables():
if not(v.name.startswith(FLAGS.loss_model)):
variables_to_restore.append(v)
saver = tf.train.Saver(variables_to_restore, write_version=tf.train.SaverDef.V1)
'''初始化变量'''
sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()])
'''初始化损失网络的变量'''
init_func = utils._get_init_fn(FLAGS)
init_func(sess)
'''检查是否存在最新的训练模型'''
last_file = tf.train.latest_checkpoint(training_path)
if last_file:
tf.logging.info('Restoring model from {}'.format(last_file))
saver.restore(sess, last_file)
"""
开始训练
coord:开启协程
coord.join:保证线程的完全运行即线程锁,保证线程池中的每个线程完成运行后,再开启下一个线程.
threads:开启多线程,提高训练速度.
"""
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
start_time = time.time()
try:
while not coord.should_stop():
_, loss_t, step = sess.run([train_op, loss, global_step])
elapsed_time = time.time() - start_time
start_time = time.time()
"""每训练10次,打印一次运行日志"""
if step % 10 == 0:
tf.logging.info('step: %d, total Loss %f, secs/step: %f' % (step, loss_t, elapsed_time))
"""每训练25次,更新tensorboard的数据一次"""
if step % 25 == 0:
tf.logging.info('adding summary...')
summary_str = sess.run(summary)
writer.add_summary(summary_str, step)
writer.flush()
"""每训练1000次,保存一次模型"""
if step % 1000 == 0:
saver.save(sess, os.path.join(training_path, 'fast-style-model.ckpt'), global_step=step)
except tf.errors.OutOfRangeError:
saver.save(sess, os.path.join(training_path, 'fast-style-model.ckpt-done'))
tf.logging.info('Done training -- epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
if __name__ == '__main__':
tf.logging.set_verbosity(tf.logging.INFO)
'''获取外部输入参数'''
args = parse_args()
'''解析外部输入的文件'''
FLAGS = utils.read_conf_file(args.conf)
main(FLAGS)
3 配置文件内容
配置文件中包含了目标图像风格图片,损失权重,神经网络模型等,以cubist风格为例,解析如下:
【conf/cubist.yml】
'''图像风格图片'''
style_image: img/candy.jpg # targeted style image
'''保存的模型名称'''
naming: "candy"
'''保存模型路径'''
model_path: models
'''图像内容权重'''
content_weight: 1.0
'''图像风格权重'''
style_weight: 50.0
'''所有变量权重损失'''
tv_weight: 0.0
'''图像尺寸'''
image_size: 256
'''图像组数'''
batch_size: 4
'''循环次数'''
epoch: 2
'''神经网络:vgg_16'''
loss_model: "vgg_16"
'''内容损失使用的网络层:conv3/conv3_3'''
content_layers:
- "vgg_16/conv3/conv3_3"
'''风格损失使用的网络层'''
style_layers: # use these layers for style loss
- "vgg_16/conv1/conv1_2"
- "vgg_16/conv2/conv2_2"
- "vgg_16/conv3/conv3_3"
- "vgg_16/conv4/conv4_3"
'''使用vgg的卷积层,忽略全连接层'''
checkpoint_exclude_scopes: "vgg_16/fc"
'''预训练的vgg模型路径:用于提取图像特征'''
loss_model_file: "pretrained/vgg_16.ckpt" # the path to the checkpoint
4 目标图像处理:风格特征提取
目标图像即需要转换风格的单张图片,提取该图像的风格并存储,以备训练时计算综合损失.
style_features_t = losses.get_style_features(FLAGS)
【losses.py】
def gram(layer):
'''
Gram矩阵提取图像风格
:params layer:神经网络层,如
('vgg_16/conv1/conv1_2', )
获取shape,重新设定尺寸,生成Gram矩阵,获取图像风格.
'''
shape = tf.shape(layer)
'''图像数量:batch尺寸:1'''
num_images = shape[0]
'''图像宽度:256'''
width = shape[1]
'''图像高度:256'''
height = shape[2]
'''图像层深:64'''
num_filters = shape[3]
'''重新设定尺寸:Tensor("Reshape:0", shape=(1, 65536, 64), dtype=float32)'''
filters = tf.reshape(layer, tf.stack([num_images, -1, num_filters]))
'''Gram矩阵计算图像风格'''
grams = tf.matmul(filters, filters, transpose_a=True) / tf.to_float(width * height * num_filters)
'''返回Gram矩阵:图像风格'''
return grams
def get_style_features(FLAGS):
"""
提取目标图像的风格特征.
params: FLAGS:yml文件的标志位
"""
with tf.Graph().as_default():
'''搭建神经网络'''
network_fn = nets_factory.get_network_fn(
FLAGS.loss_model,
num_classes=1,
is_training=False)
'''网络处理图像:vgg_preprocessing,返回图像处理函数'''
image_preprocessing_fn, image_unprocessing_fn = preprocessing_factory.get_preprocessing(
FLAGS.loss_model,
is_training=False)
'''图像处理:size=256'''
size = FLAGS.image_size
'''风格图像读取:img/candy.jpg'''
img_bytes = tf.read_file(FLAGS.style_image)
'''图像解码为Tensor'''
if FLAGS.style_image.lower().endswith('png'):
image = tf.image.decode_png(img_bytes)
else:
image = tf.image.decode_jpeg(img_bytes)
'''增加一个维度,Tensorflow处理的维度为维'''
images = tf.expand_dims(image_preprocessing_fn(image, size, size), 0)
# images = tf.stack([image_preprocessing_fn(image, size, size)])
'''
神经网络函数处理图像,返回神经网络全连接层Tensor和网络节点dict:
net: Tensor("vgg_16/fc8/BiasAdd:0", shape=(1, 2, 2, 1), dtype=float32),
字典用于提取特征值
endpoints_dict: OrderedDict([('vgg_16/conv1/conv1_1', ),.....]
'''
_, endpoints_dict = network_fn(images, spatial_squeeze=False)
features = []
'''指定神经网络:提取图像风格特征值'''
for layer in FLAGS.style_layers:
feature = endpoints_dict[layer]
feature = tf.squeeze(gram(feature), [0]) # remove the batch dimension
features.append(feature)
with tf.Session() as sess:
'''保存计算损失神经网络变量'''
init_func = utils._get_init_fn(FLAGS)
init_func(sess)
'''检查风格图像路径是否存在,若不存在,则新建。'''
if os.path.exists('generated') is False:
os.makedirs('generated')
# Indicate cropped style image path
save_file = 'generated/target_style_' + FLAGS.naming + '.jpg'
# Write preprocessed style image to indicated path
with open(save_file, 'wb') as f:
target_image = image_unprocessing_fn(images[0, :])
value = tf.image.encode_jpeg(tf.cast(target_image, tf.uint8))
f.write(sess.run(value))
tf.logging.info('Target style pattern is saved to: %s.' % save_file)
'''返回神经网络处理后的特征值。'''
return sess.run(features)
【搭建神经网络:net_factory.py】
'''slim'''
slim = tf.contrib.slim
'''神经网络映射,训练的模型使用:vgg_16,对应的值为:vgg.vgg_16'''
networks_map = {'alexnet_v2': alexnet.alexnet_v2,
'cifarnet': cifarnet.cifarnet,
'overfeat': overfeat.overfeat,
'vgg_a': vgg.vgg_a,
'vgg_16': vgg.vgg_16,
'vgg_19': vgg.vgg_19,
'inception_v1': inception.inception_v1,
'inception_v2': inception.inception_v2,
'inception_v3': inception.inception_v3,
'inception_v4': inception.inception_v4,
'inception_resnet_v2': inception.inception_resnet_v2,
'lenet': lenet.lenet,
'resnet_v1_50': resnet_v1.resnet_v1_50,
'resnet_v1_101': resnet_v1.resnet_v1_101,
'resnet_v1_152': resnet_v1.resnet_v1_152,
'resnet_v1_200': resnet_v1.resnet_v1_200,
'resnet_v2_50': resnet_v2.resnet_v2_50,
'resnet_v2_101': resnet_v2.resnet_v2_101,
'resnet_v2_152': resnet_v2.resnet_v2_152,
'resnet_v2_200': resnet_v2.resnet_v2_200,
}
'''命名空间对应的数据:vgg_16对应的:vgg.vgg_arg_scope'''
arg_scopes_map = {'alexnet_v2': alexnet.alexnet_v2_arg_scope,
'cifarnet': cifarnet.cifarnet_arg_scope,
'overfeat': overfeat.overfeat_arg_scope,
'vgg_a': vgg.vgg_arg_scope,
'vgg_16': vgg.vgg_arg_scope,
'vgg_19': vgg.vgg_arg_scope,
'inception_v1': inception.inception_v3_arg_scope,
'inception_v2': inception.inception_v3_arg_scope,
'inception_v3': inception.inception_v3_arg_scope,
'inception_v4': inception.inception_v4_arg_scope,
'inception_resnet_v2':
inception.inception_resnet_v2_arg_scope,
'lenet': lenet.lenet_arg_scope,
'resnet_v1_50': resnet_v1.resnet_arg_scope,
'resnet_v1_101': resnet_v1.resnet_arg_scope,
'resnet_v1_152': resnet_v1.resnet_arg_scope,
'resnet_v1_200': resnet_v1.resnet_arg_scope,
'resnet_v2_50': resnet_v2.resnet_arg_scope,
'resnet_v2_101': resnet_v2.resnet_arg_scope,
'resnet_v2_152': resnet_v2.resnet_arg_scope,
'resnet_v2_200': resnet_v2.resnet_arg_scope,
}
'''调用时的参数为:FLAGS.loss_model=vgg_16,num_classes=1,is_training=False'''
def get_network_fn(name, num_classes, weight_decay=0.0, is_training=False):
"""
获取神经网络的层次结构函数.
:params name: 神经网络名称.
:params num_classes: 分类的类数.
:parmas weight_decay: 模型权重l2的系数.
:params is_training: `True` 训练标志.
返回值:
network_fn: 模型处理批量图像的函数,返回有: logits, end_points = network_fn(images)
异常:
ValueError: If network `name` is not recognized.
"""
if name not in networks_map:
raise ValueError('Name of network unknown %s' % name)
arg_scope = arg_scopes_map[name](weight_decay=weight_decay)
'''func=vgg.vgg_16'''
func = networks_map[name]
@functools.wraps(func)
def network_fn(images, **kwargs):
with slim.arg_scope(arg_scope):
return func(images, num_classes, is_training=is_training, **kwargs)
if hasattr(func, 'default_image_size'):
network_fn.default_image_size = func.default_image_size
return network_fn
【图像处理:preprocessing_factory.py】
返回图像处理函数.
'''slim'''
slim = tf.contrib.slim
def get_preprocessing(name, is_training=False):
"""
返回处理函数:preprocessing_fn(image, height, width, **kwargs).
参数:
name: 处理模型名称,vgg_16.
is_training: 训练标志.
返回:
preprocessing_fn: 单一图片处理函数.
image = preprocessing_fn(image, output_height, output_width, ...).
Raises:
ValueError: If Preprocessing `name` is not recognized.
"""
preprocessing_fn_map = {
'cifarnet': cifarnet_preprocessing,
'inception': inception_preprocessing,
'inception_v1': inception_preprocessing,
'inception_v2': inception_preprocessing,
'inception_v3': inception_preprocessing,
'inception_v4': inception_preprocessing,
'inception_resnet_v2': inception_preprocessing,
'lenet': lenet_preprocessing,
'resnet_v1_50': vgg_preprocessing,
'resnet_v1_101': vgg_preprocessing,
'resnet_v1_152': vgg_preprocessing,
'vgg': vgg_preprocessing,
'vgg_a': vgg_preprocessing,
'vgg_16': vgg_preprocessing,
'vgg_19': vgg_preprocessing,
}
if name not in preprocessing_fn_map:
raise ValueError('Preprocessing name [%s] was not recognized' % name)
def preprocessing_fn(image, output_height, output_width, **kwargs):
return preprocessing_fn_map[name].preprocess_image(
image, output_height, output_width, is_training=is_training, **kwargs)
def unprocessing_fn(image, **kwargs):
return preprocessing_fn_map[name].unprocess_image(
image, **kwargs)
return preprocessing_fn, unprocessing_fn
【预处理图像:vgg_processing.py】
主要对图片进行裁剪,图像维度转换,返回处理后(减去均值后)的图像数据.
def _mean_image_subtraction(image, means):
"""
RGB通道减去对应的均值.
如:
means = [123.68, 116.779, 103.939]
image = _mean_image_subtraction(image, means)
Note that the rank of `image` must be known.
参数:
image: 图像Tensor. 尺寸[height, width, C].
means: 各通道均值.
返回:
中心化的图像.
"""
if image.get_shape().ndims != 3:
raise ValueError('Input must be of size [height, width, C>0]')
num_channels = image.get_shape().as_list()[-1]
if len(means) != num_channels:
raise ValueError('len(means) must match the number of channels')
'''
将RGB拆成3个独立的通道,R,G,B
[, , ]
'''
channels = tf.split(image, num_channels, 2)
for i in range(num_channels):
'''每个通道减去对应的均值'''
channels[i] -= means[i]
'''将拆开的RGB通道复原,并返回Tensor("concat:0", shape=(?, ?, 3), dtype=uint8)'''
return tf.concat(channels, 2)
def preprocess_image(image, output_height, output_width, is_training=False,
resize_side_min=_RESIZE_SIDE_MIN,
resize_side_max=_RESIZE_SIDE_MAX,
):
"""
处理给定图像.
参数:
image: 张量图像.
output_height: 预处理后的图像高度.
output_width: 预处理后的图像宽度.
is_training: 训练标志位
resize_side_min: 保持纵横比的最小边的长度.
resize_side_max: 保持纵横比的最大边长度.
[resize_size_min, resize_size_max].
返回:
处理后的图像.
"""
if is_training:
return preprocess_for_train(image, output_height, output_width,
resize_side_min, resize_side_max)
else:
return preprocess_for_eval(image, output_height, output_width,
resize_side_min)
def preprocess_for_train(image,
output_height,
output_width,
resize_side_min=_RESIZE_SIDE_MIN,
resize_side_max=_RESIZE_SIDE_MAX):
"""
训练预处理图像.
参数:
image: 张量图像.
output_height: 预处理后的图像高度..
output_width: 预处理后的图像宽度.
resize_side_min: 保持纵横比的最小边的长度.
resize_side_max: 保持纵横比的最大边长度.
返回:
处理后的图像.
"""
resize_side = tf.random_uniform(
[], minval=resize_side_min, maxval=resize_side_max + 1, dtype=tf.int32)
image = _aspect_preserving_resize(image, resize_side)
image = _random_crop([image], output_height, output_width)[0]
image.set_shape([output_height, output_width, 3])
image = tf.to_float(image)
image = tf.image.random_flip_left_right(image)
'''图像RGB减去均值'''
return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
def preprocess_for_eval(image, output_height, output_width, resize_side):
"""
评估处理图像.
参数:
image: 张量图像.
output_height: 预处理后的图像高度.
output_width: 预处理后的图像宽度.
返回:
处理后的图像.
"""
image = _aspect_preserving_resize(image, output_height, output_width)
image = _central_crop([image], output_height, output_width)[0]
# image = tf.image.resize_image_with_crop_or_pad(image, output_height, output_width)
image.set_shape([output_height, output_width, 3])
image = tf.to_float(image)
return _mean_image_subtraction(image, [_R_MEAN, _G_MEAN, _B_MEAN])
【vgg神经网络处理图片:vgg.py】
def vgg_16(inputs,
num_classes=1000,
is_training=True,
dropout_keep_prob=0.5,
spatial_squeeze=True,
scope='vgg_16'):
"""Oxford Net VGG 16-Layers version D Example.
Note:所有全连接层转化为卷积层,为使用分类模型,将图像裁剪为224x224.
参数:
inputs: 输入图像Tensor[batch_size, height, width, channels].
num_classes: 预测种类.
is_training: 是否使用预训练模型.
dropout_keep_prob: 训练时激活网络层的概率
spatial_squeeze: 是否压缩输出的维度,有助于移除不必要的分类维度
scope: 变量空间.
返回:
返回预测即全连接层和网络结构.
"""
with tf.variable_scope(scope, 'vgg_16', [inputs]) as sc:
end_points_collection = sc.name + '_end_points'
# Collect outputs for conv2d, fully_connected and max_pool2d.
with slim.arg_scope([slim.conv2d, slim.fully_connected, slim.max_pool2d],
outputs_collections=end_points_collection):
net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1')
net = slim.max_pool2d(net, [2, 2], scope='pool1')
net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2')
net = slim.max_pool2d(net, [2, 2], scope='pool2')
net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3')
net = slim.max_pool2d(net, [2, 2], scope='pool3')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4')
net = slim.max_pool2d(net, [2, 2], scope='pool4')
net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5')
net = slim.max_pool2d(net, [2, 2], scope='pool5')
# Use conv2d instead of fully_connected layers.
net = slim.conv2d(net, 4096, [7, 7], padding='VALID', scope='fc6')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout6')
net = slim.conv2d(net, 4096, [1, 1], scope='fc7')
net = slim.dropout(net, dropout_keep_prob, is_training=is_training,
scope='dropout7')
net = slim.conv2d(net, num_classes, [1, 1],
activation_fn=None,
normalizer_fn=None,
scope='fc8')
# Convert end_points_collection into a end_point dict.
end_points = slim.utils.convert_collection_to_dict(end_points_collection)
if spatial_squeeze:
net = tf.squeeze(net, [1, 2], name='fc8/squeezed')
end_points[sc.name + '/fc8'] = net
return net, end_points
net: Tensor("vgg_16/fc8/BiasAdd:0", shape=(1, 2, 2, 1), dtype=float32),
endpoints_dict: OrderedDict([('vgg_16/conv1/conv1_1', ), ('vgg_16/conv1/conv1_2', ), ('vgg_16/pool1', ), ('vgg_16/conv2/conv2_1', ), ('vgg_16/conv2/conv2_2', ), ('vgg_16/pool2', ), ('vgg_16/conv3/conv3_1', ), ('vgg_16/conv3/conv3_2', ), ('vgg_16/conv3/conv3_3', ), ('vgg_16/pool3', ), ('vgg_16/conv4/conv4_1', ), ('vgg_16/conv4/conv4_2', ), ('vgg_16/conv4/conv4_3', ), ('vgg_16/pool4', ), ('vgg_16/conv5/conv5_1', ), ('vgg_16/conv5/conv5_2', ), ('vgg_16/conv5/conv5_3', ), ('vgg_16/pool5', ), ('vgg_16/fc6', ), ('vgg_16/fc7', ), ('vgg_16/fc8', )])
【载入预训练模型:utils.py】
def _get_init_fn(FLAGS):
"""
slim函数.
返回:
管理者初始化函数.
"""
tf.logging.info('Use pretrained model %s' % FLAGS.loss_model_file)
exclusions = []
if FLAGS.checkpoint_exclude_scopes:
exclusions = [scope.strip()
for scope in FLAGS.checkpoint_exclude_scopes.split(',')]
'''变量:滑动窗口变量'''
variables_to_restore = []
for var in slim.get_model_variables():
excluded = False
for exclusion in exclusions:
if var.op.name.startswith(exclusion):
excluded = True
break
if not excluded:
variables_to_restore.append(var)
'''返回提取变量函数'''
return slim.assign_from_checkpoint_fn(
FLAGS.loss_model_file,
variables_to_restore,
ignore_missing_vars=True)
【新建的训练网络model.py】
该网络用于处理图像即将输入的目标内容图像转换为指定风格的图像,其中用到了下采样对图像卷积和池化,抛弃全连接层,然后对图像进行上采样,通过最近邻域法扩大图像尺寸,返回指定风格的正常图像.
def net(image, training):
# Less border effects when padding a little before passing through ..
image = tf.pad(image, [[0, 0], [10, 10], [10, 10], [0, 0]], mode='REFLECT')
'''
(4, 276, 276, 3)
:params 4: batch size
:params [276, 276, 3] : padded image shapes.
'''
print("image shape after padding: {}".format(image.shape))
with tf.variable_scope('conv1'):
'''
:params 3: current deep
:params 32: next deep
:params 9:kernel for padding and filter window.
:parmas 1: filter edge size(strides)
'''
'''下采样'''
'''[276, 276, 32]'''
conv1 = relu(instance_norm(conv2d(image, 3, 32, 9, 1)))
print("conv1 shape: {}".format(conv1.shape))
with tf.variable_scope('conv2'):
'''[]'''
conv2 = relu(instance_norm(conv2d(conv1, 32, 64, 3, 2)))
print("conv2 shape: {}".format(conv2.shape))
with tf.variable_scope('conv3'):
conv3 = relu(instance_norm(conv2d(conv2, 64, 128, 3, 2)))
with tf.variable_scope('res1'):
res1 = residual(conv3, 128, 3, 1)
with tf.variable_scope('res2'):
res2 = residual(res1, 128, 3, 1)
with tf.variable_scope('res3'):
res3 = residual(res2, 128, 3, 1)
with tf.variable_scope('res4'):
res4 = residual(res3, 128, 3, 1)
with tf.variable_scope('res5'):
res5 = residual(res4, 128, 3, 1)
print("NN processed shape: {}".format(res5.get_shape()))
'''上采样'''
with tf.variable_scope('deconv1'):
# deconv1 = relu(instance_norm(conv2d_transpose(res5, 128, 64, 3, 2)))
deconv1 = relu(instance_norm(resize_conv2d(res5, 128, 64, 3, 2, training)))
print("deconv1 shape: {}".format(deconv1.shape))
with tf.variable_scope('deconv2'):
# deconv2 = relu(instance_norm(conv2d_transpose(deconv1, 64, 32, 3, 2)))
deconv2 = relu(instance_norm(resize_conv2d(deconv1, 64, 32, 3, 2, training)))
print("deconv2 shape: {}".format(deconv2.shape))
with tf.variable_scope('deconv3'):
# deconv_test = relu(instance_norm(conv2d(deconv2, 32, 32, 2, 1)))
deconv3 = tf.nn.tanh(instance_norm(conv2d(deconv2, 32, 3, 9, 1)))
'''
deconv3 value: Tensor("deconv3/Tanh:0", shape=(4, 276, 276, 3), dtype=float32)
processed value: Tensor("mul_2:0", shape=(4, 276, 276, 3), dtype=float32)
'''
print("deconv3 shape: {}".format(deconv3.shape))
print("deconv3 value: {}".format(deconv3))
y = (deconv3 + 1) * 127.5
print("processed value: {}".format(y))
# Remove border effect reducing padding.
height = tf.shape(y)[1]
width = tf.shape(y)[2]
y = tf.slice(y, [0, 10, 10, 0], tf.stack([-1, height - 20, width - 20, -1]))
'''final y: Tensor("Slice_1:0", shape=(4, 256, 256, 3), dtype=float32)'''
print("final y: {}".format(y))
return y
5 数据集数据处理
数据集即待训练的大量图像,通过裁剪,归一化,获取处理后的图像数据组.
【数据集图像读取:reader.py】
def image(batch_size, height, width, path, preprocess_fn, epochs=2, shuffle=True):
filenames = [join(path, f) for f in listdir(path) if isfile(join(path, f))]
if not shuffle:
filenames = sorted(filenames)
png = filenames[0].lower().endswith('png') # If first file is a png, assume they all are
'''打乱数据集顺序'''
filename_queue = tf.train.string_input_producer(filenames, shuffle=shuffle, num_epochs=epochs)
'''读取图片'''
reader = tf.WholeFileReader()
'''图片转bytes'''
_, img_bytes = reader.read(filename_queue)
'''图片bytes转为RGB'''
image = tf.image.decode_png(img_bytes, channels=3) if png else tf.image.decode_jpeg(img_bytes, channels=3)
'''图像减去均值后的RGB图像'''
processed_image = preprocess_fn(image, height, width)
'''
返回批量数据Tensor:processed images:
Tensor("batch:0", shape=(4, 256, 256, 3), dtype=float32)
'''
return tf.train.batch([processed_image], batch_size, dynamic_pad=True)
6 内容损失提取
【内容损失提取:losses.py】
content_loss = losses.content_loss(endpoints_dict, FLAGS.content_layers)
内容损失网络层:
content_layers: # use these layers for content loss
- "vgg_16/conv3/conv3_3"
数据集图像内容提取:
【内容损失提取:losses.py】
def content_loss(endpoints_dict, content_layers):
content_loss = 0
for layer in content_layers:
'''
提取图像内容:endpoints_dict[layer]
获取为:Tensor("vgg_16/conv3/conv3_3/Relu:0", shape=(8, 64, 64, 256), dtype=float32)
拆分:[, ]
第一个为神经网络和均值处理的图像数据,(images+1)*127.5,(RGB-RGB_mean)
第二个为是数据集的原始数据,通过特定网络层对源数据的内容提取
计算损失
'''
generated_images, content_images = tf.split(endpoints_dict[layer], 2, 0)
size = tf.size(generated_images)
'''
通过处理后的图像与图像内容计算内容损失,例如源数据为10, 内容为8,则损失为10-8=2
正则化损失,防止过拟合
'''
content_loss += tf.nn.l2_loss(generated_images - content_images) * 2 / tf.to_float(size)
return content_loss
7 风格损失提取
【风格损失提取:losses.py】
style_loss, style_loss_summary = losses.style_loss(endpoints_dict, style_features_t, FLAGS.style_layers)
数据集图像风格提取:
def style_loss(endpoints_dict, style_features_t, style_layers):
'''
数据集图像风格提取
:params endpoints_dict:神经网络结构字典
:params style_features_t:目标图像风格特征
:params style_layers:指定图像风格所在的神经网络层
'''
style_loss = 0
style_loss_summary = {}
for style_gram, layer in zip(style_features_t, style_layers):
'''提取经过神经网络和均值处理的图像数据'''
generated_images, _ = tf.split(endpoints_dict[layer], 2, 0)
size = tf.size(generated_images)
'''
利用Gram矩阵提取图像的风格并计算损失
参照的损失为目标图像的损失
正则化损失,防止过拟合
'''
layer_style_loss = tf.nn.l2_loss(gram(generated_images) - style_gram) * 2 / tf.to_float(size)
style_loss_summary[layer] = layer_style_loss
style_loss += layer_style_loss
return style_loss, style_loss_summary
8 内容与风格总损失优化
【train.py】
'''总损失'''
loss = FLAGS.style_weight * style_loss + FLAGS.content_weight * content_loss + FLAGS.tv_weight * tv_loss
'''优化损失'''
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss, global_step=global_step, var_list=variable_to_train)
9 训练及保存模型
【train.py】
'''定义训练步数变量,该变量不可训练,用于记录训练的轮数'''
global_step = tf.Variable(0, name="global_step", trainable=False)
variable_to_train = []
for variable in tf.trainable_variables():
if not(variable.name.startswith(FLAGS.loss_model)):
variable_to_train.append(variable)
train_op = tf.train.AdamOptimizer(1e-3).minimize(loss, global_step=global_step, var_list=variable_to_train)
variables_to_restore = []
for v in tf.global_variables():
if not(v.name.startswith(FLAGS.loss_model)):
variables_to_restore.append(v)
saver = tf.train.Saver(variables_to_restore, write_version=tf.train.SaverDef.V1)
'''初始化变量'''
sess.run([tf.global_variables_initializer(), tf.local_variables_initializer()])
'''保存损失网络变量'''
init_func = utils._get_init_fn(FLAGS)
init_func(sess)
'''检查模型,若有模型则读取最新的训练状态.'''
last_file = tf.train.latest_checkpoint(training_path)
if last_file:
tf.logging.info('Restoring model from {}'.format(last_file))
saver.restore(sess, last_file)
"""
开始训练
coord:开启协程
coord.join:保证线程的完全运行即线程锁,保证线程池中的每个线程完成运行后,再开启下一个线程.
threads:开启多线程,提高训练速度.
"""
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(coord=coord)
start_time = time.time()
try:
while not coord.should_stop():
_, loss_t, step = sess.run([train_op, loss, global_step])
elapsed_time = time.time() - start_time
start_time = time.time()
"""每训练10次,打印一次运行日志"""
if step % 10 == 0:
tf.logging.info('step: %d, total Loss %f, secs/step: %f' % (step, loss_t, elapsed_time))
"""每训练25次,更新tensorboard的数据一次"""
if step % 25 == 0:
tf.logging.info('adding summary...')
summary_str = sess.run(summary)
writer.add_summary(summary_str, step)
writer.flush()
"""每训练1000次,保存一次模型"""
if step % 1000 == 0:
saver.save(sess, os.path.join(training_path, 'fast-style-model.ckpt'), global_step=step)
except tf.errors.OutOfRangeError:
saver.save(sess, os.path.join(training_path, 'fast-style-model.ckpt-done'))
tf.logging.info('Done training -- epoch limit reached')
finally:
coord.request_stop()
coord.join(threads)
10 总结
(1)快速图像风格转换步骤:
(2) 图像处理有三个阶段:第一阶段是直接读取数据集图像内容,仅对图像进行剪裁,不进行深度处理;第二阶段根据读取的原始数据,对图像进行归一化处理,即RGB通道减去各自通道的均值;第三阶段是利用神经网络对图像数据进行提取,获取图像风格则进一步利用Gram矩阵进行计算,提取图像内容则可用直接使用NN提取的内容.
(3) 图像处理过程中,使用了图形级联(tf.concat)与拆解(tf.split),其中级联是将神经网络提取的图像内容与图像原始内容级联,后续计算进行拆解计算内容损失.
(4) 为防止计算损失时出现过拟合或欠拟合,使用$tf.nn.l2_loss$正则方法.
(5) 训练过程中,使用了多线成,和协程,保证了数据的处理速度和处理的完整性.
[参考文献]
[1]https://blog.csdn.net/Xin_101/article/details/86346697
[2]https://blog.csdn.net/Xin_101/article/details/86366221
[3]https://github.com/hzy46/fast-neural-style-tensorflow