图像语义分割:从头开始训练deeplab v2系列之三【pascal-context数据集】
在之前的博客已经讲过deeplab v2源码解析与基于VOC2012数据集的训练,本博客基于pascal-context数据集进行fine tuning
官方源码地址如下:https://bitbucket.org/aquariusjay/deeplab-public-ver2/overview
但是此源码只是为deeplab网络做相应变形的caffe,如果需要fine tuning微调网络,还需要准备以下文件:
txt文件:文件中有数据集的名字列表的txt文件,此处不同于源码,在pascal-context数据集上自己制作,训练测试集列表
训练好的init.caffemodel: 针对deeplab v2,作者有已经预训练好的两个模型参数:DeepLabv2_VGG16 和DeepLabv2_ResNet101
网络结构prototxt文件: train.prototxt和solver.prototxt,分别在:DeepLabv2_VGG16 和 DeepLabv2_ResNet101
- 官网脚本文件: 三个sh文件,建议使用脚本文件,初看虽不懂,但是比python版本的运行简单很多
**注:本博客只涉及脚本版本的训练,pascal-context的list文件要自己根据数据集制作,或者使用此博客的list
准备工作
1.必要工具
下载安装matio,下载地址
2.数据集准备
本文采用的数据集为pascal-context,由voc2010数据集和pascal-context的注释组成,正如下图数据说明:

原始数据集为voc2010,label即为上图中所说的the annotations for training/validation set为ma,需要把mat文件转为png文件
数据下载
# original PASCAL VOC 2010
cd ~/DL_dataset #save datasets 为$DATASETS
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2010/VOCtrainval_03-May-2010.tar #1.3 GB
tar -xvf VOCtrainval_03-May-2010.tar
# the annotations for training/validation set
cd ~/DL_dataset/VOCdevkit
wget http://www.stat.ucla.edu/~ccvl/datasets/pascal-context/trainval.tar.gz #30.7MB only contains the annotations for training set
tar -zxvf trainval.tar.gz
数据转换
修改其中的数据路径为你的trainval所在路径,并在此路径下创建labels文件
cd ~/deeplab_v2/pascal-context
vim convert_rawmat_labels.py 
然后进行数据转换,生成的png数据移动到voc2010数据文件夹中
python convert_rawmat_labels.py
mv ~/DL_dataset/VOCdevkit/trainval/labels ~/DL_dataset/VOCdevkit/VOC2010/PASCALContexts
符合list文件夹中train_aug.txt的调用

到此处, ~/DL_dataset/VOCdevdit/VOC2010文件夹中有五个文件夹
![]()
1.从github克隆train deeplab_v2文件夹
此github已经将文件夹结构建好,已保存有源码的prototxt文件,脚本sh文件,并已经自己制作好对应的数据集txt文件,放置到对应文件夹下。由于官方model文件大,不宜放GitHub,将在第3步下载。
cd ~
git clone git@github.com:xmojiao/deeplab_v2.git2.将源码下载到此文件夹下,并编译安装deeplab caffe
cd deeplab_v2
git clone https://bitbucket.org/aquariusjay/deeplab-public-ver2.git
cd deeplab-public-ver2
make all
make pycaffe
make test # NOT mandatory
make runtest # NOT mandatory
3.将官方预训练的model放置到pascal-context的model/deeplab_largeFOV
此处以VGG16训练为例,model下载地址
也可在命令行下载并移动到相应文件夹,如下:
wget http://liangchiehchen.com/projects/released/deeplab_aspp_vgg16/prototxt_and_model.zip
unzip prototxt_and_model.zip
mv *caffemodel ~/pascal-context/model/deeplab_largeFOV
rm *prototxt4.deeplab2的script脚本文件run_pascal.sh 解析
目前我们已经准备好数据集和数据txt文件,参数文件model,网络结构文件prototxt,和三个sh脚本文件,接下来只需要修改run_pascal.sh文件,deeplabv2就可以run起来了。
注:与从头开始训练deeplab v2系列之二【VOC2012数据集】最大的区别之处是修改了label的类别数为459类
## MODIFY PATH for YOUR SETTING
ROOT_DIR=/home/guo/DL_dataset
CAFFE_DIR=../deeplab-public-ver2 #所下载编译的deeplab源码目录
CAFFE_BIN=${CAFFE_DIR}/.build_release/tools/caffe.bin
EXP=.
if [ "${EXP}" = "." ]; then
NUM_LABELS=459 #**本脚本文件与voc2012的最大区别之处,修改类别21为459类**
DATA_ROOT=${ROOT_DIR}/VOCdevkit/VOC2010/
else
NUM_LABELS=0
echo "Wrong exp name"
fi
which model to train
########### voc12 ################
NET_ID=deeplab_largeFOV ##此处原文件名有问题应该改为deeplab_largeFOV
## Variables used for weakly or semi-supervisedly training
#TRAIN_SET_SUFFIX=
TRAIN_SET_SUFFIX=_aug #此处为选择train_aug.txt数据集
#TRAIN_SET_STRONG=train
#TRAIN_SET_STRONG=train200
#TRAIN_SET_STRONG=train500
#TRAIN_SET_STRONG=train1000
#TRAIN_SET_STRONG=train750
#TRAIN_SET_WEAK_LEN=5000
DEV_ID=0
#####
## Create dirs
CONFIG_DIR=${EXP}/config/${NET_ID} #此处目录为/pascal-context/config/deeplab_largeFOV
MODEL_DIR=${EXP}/model/${NET_ID}
mkdir -p ${MODEL_DIR}
LOG_DIR=${EXP}/log/${NET_ID}
mkdir -p ${LOG_DIR}
export GLOG_log_dir=${LOG_DIR}
## Run
RUN_TRAIN=1 #为1说明执行train
RUN_TEST=0 #为1说明执行test
RUN_TRAIN2=0
RUN_TEST2=0
## Training #1 (on train_aug)
if [ ${RUN_TRAIN} -eq 1 ]; then #r如果RUN_TRAIN为1
#
LIST_DIR=${EXP}/list
TRAIN_SET=train${TRAIN_SET_SUFFIX}
if [ -z ${TRAIN_SET_WEAK_LEN} ]; then #如果TRAIN_SET_WEAK_LEN长度为零则为真
TRAIN_SET_WEAK=${TRAIN_SET}_diff_${TRAIN_SET_STRONG}
comm -3 ${LIST_DIR}/${TRAIN_SET}.txt ${LIST_DIR}/${TRAIN_SET_STRONG}.txt > ${LIST_DIR}/${TRAIN_SET_WEAK}.txt
else
TRAIN_SET_WEAK=${TRAIN_SET}_diff_${TRAIN_SET_STRONG}_head${TRAIN_SET_WEAK_LEN}
comm -3 ${LIST_DIR}/${TRAIN_SET}.txt ${LIST_DIR}/${TRAIN_SET_STRONG}.txt | head -n ${TRAIN_SET_WEAK_LEN} > ${LIST_DIR}/${TRAIN_SET_WEAK}.txt
fi
#
MODEL=${EXP}/model/${NET_ID}/init.caffemodel #下载的vgg16或者ResNet101中的 model
#
echo Training net ${EXP}/${NET_ID}
for pname in train solver; do
sed "$(eval echo $(cat sub.sed))" \
${CONFIG_DIR}/${pname}.prototxt > ${CONFIG_DIR}/${pname}_${TRAIN_SET}.prototxt
done #此部分运行时如以下命令
CMD="${CAFFE_BIN} train \
--solver=${CONFIG_DIR}/solver_${TRAIN_SET}.prototxt \
--gpu=${DEV_ID}"
if [ -f ${MODEL} ]; then
CMD="${CMD} --weights=${MODEL}"
fi
echo Running ${CMD} && ${CMD}
fi
#train部分运行时,即以下运行命令 ../deeplab-public-ver2/.build_release/tools/caffe.bin train --solver=./config/deeplab_largeFOV/solver_train_aug.prototxt --gpu=0 --weights=./model/deeplab_largeFOV/init.caffemodel
#上述命令中,solver_train_aug.prototxt由solve.prototxt文件复制而来,init.caffemodel为原始下载了的VGG16的model
## Test #1 specification (on val or test)
if [ ${RUN_TEST} -eq 1 ]; then
#
for TEST_SET in val; do
TEST_ITER=`cat ${EXP}/list/${TEST_SET}.txt | wc -l` #此处计算val.txt文件中测试图片个数,共1449个
MODEL=${EXP}/model/${NET_ID}/test.caffemodel
if [ ! -f ${MODEL} ]; then
MODEL=`ls -t ${EXP}/model/${NET_ID}/train_iter_*.caffemodel | head -n 1`
fi
#
echo Testing net ${EXP}/${NET_ID}
FEATURE_DIR=${EXP}/features/${NET_ID}
mkdir -p ${FEATURE_DIR}/${TEST_SET}/fc8
mkdir -p ${FEATURE_DIR}/${TEST_SET}/fc9
mkdir -p ${FEATURE_DIR}/${TEST_SET}/seg_score
sed "$(eval echo $(cat sub.sed))" \
${CONFIG_DIR}/test.prototxt > ${CONFIG_DIR}/test_${TEST_SET}.prototxt
CMD="${CAFFE_BIN} test \
--model=${CONFIG_DIR}/test_${TEST_SET}.prototxt \
--weights=${MODEL} \
--gpu=${DEV_ID} \
--iterations=${TEST_ITER}"
echo Running ${CMD} && ${CMD}
done
fi
#test部分运行时,即以下运行命令../deeplab-public-ver2/.build_release/tools/caffe.bin test --model=./config/deeplab_largeFOV/test_val.prototxt --weights=./model/deeplab_largeFOV/train_iter_20000.caffemodel --gpu=0 --iterations=499
#上述命令中,test_val.prototxt由test.prototxt文件复制而来,train_iter_20000.caffemode由第一部分train得到的model5.deeplab跑起来
此处我将train和test分开操作,即是修改run_pascal.sh脚本中的如下代码:
- RUN_TRAIN=1 时
cd ~/deeplab_v2/pascal-context
sh run_pascal.sh 2>&1|tee train.log
2>&1|tee train.log
指令的作用为在命令行展示log的同时,保存log到当前目录的train.log文件夹。前工作做的顺利的话,你就能看到如下结果。

- RUN_TEST=1
目前没发现作者有写单张图片测试的代码,但是当我们跑此部分run_test时,会得到png格式的测试结果
跑出测试结果
sh run_pascal.sh 2>&1|tee train.log

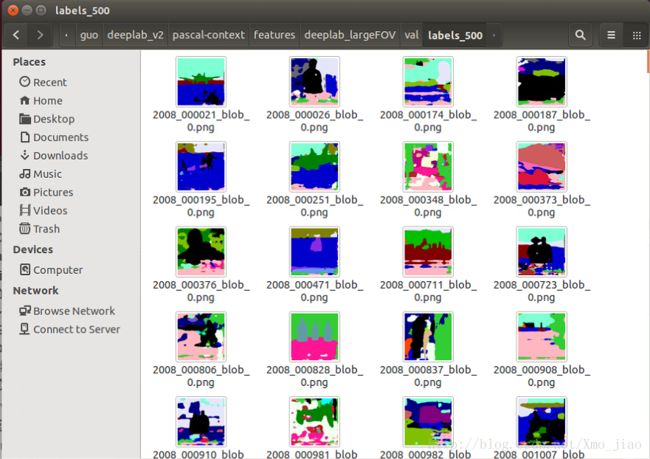
6.将test的结果mat文件转换为png文件
同voc2012的测试结果一样,test结束,你会在~/deeplab_v2/pascal-context/features/deeplab_largeFOV/val/fc8目录下跑出mat格式的结果。
mat转png图片
-修改creat_labels.py中文件目录
cd ~/deeplab_v2/pascal-context/
vim create_labels_249.py
-在此目录运行creat_labels_249.py
由于pascal-context数据集图像采用全分割的方式,不同于voc2012的21类,本次训练的数据集有459个类别,原来的21种颜色无法充分表达,但考虑到颜色类别有限,所以博主采用249种颜色来表达459种类物体。
python create_labels_249.py
pascal-context得到的结果如下图: