Hadoop—archive
HDFS并不擅长存储小文件,因为每个文件最少一个block,每个block的元数据都会在namenode节点占用内存,如果存在这样大量的小文件,它们会吃掉namenode节点的大量内存。Hadoop Archive是一个高效地将小文件放入HDFS块中的文件存档文件格式,它能够将多个小文件打包成一个后缀为.har文件,这样减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
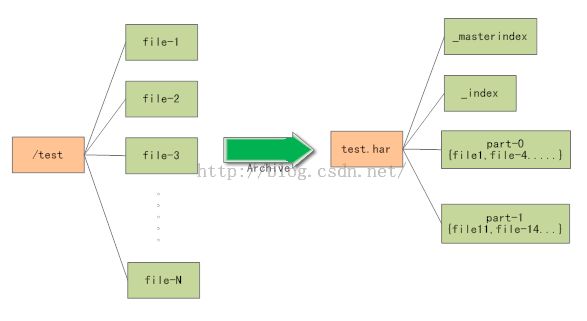
Hadoop Archive目录包含metadata(in the form of _index and _masterindex)和data (part-*)文件。The _index file contains the name of the files that are part of the archive and the location within the part files.
Hadoop官网的Hadoop Archives Guide
1. 怎么使用Archive
用法:hadoop archive -archiveName name -p
-archiveName用来指定要创建的archive的文件名,必须以.har结尾,例如:foo.har;
-p用来指定Archive文件的父路径,指定了之后,后面的src、dest都是相对路径,例如:-p /foo/bar a/b/c e/f/g;
-r用来指定所需的复制因子,这个参数是可有可无的,如果没有的话,默认选择10作为复制因子。
[hadoop@master ~]$ hadoop fs -ls -R /
drwxr-xr-x - hadoop supergroup 0 2016-01-30 19:56 /user
drwxr-xr-x - hadoop supergroup 0 2016-01-30 19:59 /user/hadoop
drwxr-xr-x - hadoop supergroup 0 2016-01-30 19:59 /user/hadoop/har
drwxr-xr-x - hadoop supergroup 0 2016-01-30 19:58 /user/hadoop/test_archive
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 /user/hadoop/test_archive/2016-1
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 /user/hadoop/test_archive/2016-2
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 /user/hadoop/test_archive/2016-3
现在要将/user/hadoop/test_archive目录下的2016-1、2016-2、2016-3文件归档到/user/hadoop/har目录下,可以使用如下命令:hadoop archive -archiveName combine.har -p /user/hadoop test_archive/2016-1 test_archive/2016-2 test_archive/2016-3 har。当然了,也可以使用通配符来完成:hadoop archive -archiveName combine2.har -p /user/hadoop test_archive/2016-[1-3] har
2. 怎么查看Archive文件
archive作为文件系统层暴露给外界。所以所有的fs shell命令都能在archive上运行,但是要使用不同的URI。 另外,archive是不可改变的。所以重命名,删除和创建都会返回错误。Hadoop Archive的URI是:har://scheme-hostname:port/archivepath/fileinarchive。
如果没提供scheme-hostname,它会使用默认的文件系统。这种情况下URI是这种形式:har:///archivepath/fileinarchive
[hadoop@master ~]$ hadoop fs -ls /user/hadoop/har
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2016-01-30 20:02 /user/hadoop/har/combine.har[hadoop@master ~]$ hadoop fs -ls /user/hadoop/har/combine.har
Found 4 items
-rw-r--r-- 3 hadoop supergroup 0 2016-01-30 20:02 /user/hadoop/har/combine.har/_SUCCESS
-rw-r--r-- 5 hadoop supergroup 378 2016-01-30 20:02 /user/hadoop/har/combine.har/_index
-rw-r--r-- 5 hadoop supergroup 23 2016-01-30 20:02 /user/hadoop/har/combine.har/_masterindex
-rw-r--r-- 3 hadoop supergroup 6 2016-01-30 20:02 /user/hadoop/har/combine.har/part-0
[hadoop@master ~]$ hadoop fs -ls -R har://hdfs-master:9000/user/hadoop/har/combine.har
16/01/30 20:27:45 WARN hdfs.DFSClient: DFSInputStream has been closed already
drwxr-xr-x - hadoop supergroup 0 2016-01-30 19:58 har://hdfs-master:9000/user/hadoop/har/combine.har/test_archive
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 har://hdfs-master:9000/user/hadoop/har/combine.har/test_archive/2016-1
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 har://hdfs-master:9000/user/hadoop/har/combine.har/test_archive/2016-2
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 har://hdfs-master:9000/user/hadoop/har/combine.har/test_archive/2016-3
也可以省略掉hdfs-master:9000
[hadoop@master ~]$ hadoop fs -ls -R har:///user/hadoop/har/combine.har
16/01/30 20:31:32 WARN hdfs.DFSClient: DFSInputStream has been closed already
drwxr-xr-x - hadoop supergroup 0 2016-01-30 19:58 har:///user/hadoop/har/combine.har/test_archive
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 har:///user/hadoop/har/combine.har/test_archive/2016-1
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 har:///user/hadoop/har/combine.har/test_archive/2016-2
-rw-r--r-- 3 hadoop supergroup 2 2016-01-30 19:58 har:///user/hadoop/har/combine.har/test_archive/2016-33. 怎么解压Archive文件
Since all the fs shell commands in the archives worktransparently, unarchiving is just a matter of copying.
To unarchive sequentially(串行解压):
hdfs dfs -cp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
To unarchive in parallel(并行解压), use DistCp:
hadoop distcp har:///user/zoo/foo.har/dir1 hdfs:/user/zoo/newdir
4. Hadoop Archives and MapReduce
Using Hadoop Archives in MapReduce is as easy as specifying a different input filesystem than the default file system. If you have a hadoop archive stored in HDFS in /user/zoo/foo.har then for using this archive for MapReduce input, all you need to specify the input directory as har:///user/zoo/foo.har. Since Hadoop Archives is exposed as a file system MapReduce will be able to use all the logical input files in Hadoop Archives as input.