DeepFM模型
DeepFM:
在DeepFM提出之前,已有LR,FM,FFM,FNN,PNN(以及三种变体:IPNN,OPNN,PNN*),Wide&Deep模型,这些模型在CTR或者是推荐系统中被广泛使用。但是,这些模型普遍都存在两个问题:
- 偏向于提取低阶或者高阶的组合特征,不能同时提取这两种类型的特征。
- 需要专业的领域知识人工做特征工程。
DeepFM在Wide&Deep的基础上进行改进,成功解决了这两个问题,并做了一些改进,DeepFM算法有效的结合了因子分解机与神经网络在特征学习中的优点,同时提取到低阶组合特征与高阶组合特征,其中,FM算法负责对一阶特征以及由一阶特征两两组合而成的二阶特征进行特征的提取;DNN算法负责对由输入的一阶特征进行全连接等操作形成的高阶特征进行特征的提取。FM模块和Deep模块共享Feature Embedding,不但使得训练更快,而且使得训练更加准确。相比之下,Wide&Deep中,input vector非常大,里面包含了大量的人工设计的组合特征,增加了计算复杂度。不需要预训练FM得到隐向量
但是DeepFM共享feature embedding 这个特性使得在反向传播的时候,模型学习feature embedding,而后又会在前向传播的时候影响低阶和高阶特征的学习,这使得学习更加的准确。
-
没有预训练(no pre-training)
-
训练效率高。(相比PNN没有那么多参数)
-
没有用FM去预训练隐向量V,并用V去初始化神经网络。(相比之下FNN就需要预训练FM来初始化DNN)
-
FM模块不是独立的,是跟整个模型一起训练学习得到的。(相比之下Wide&Deep中的Wide和Deep部分是没有共享的)
- 结合了广度和深度模型的优点,联合训练FM模型和DNN模型,同时学习低阶特征组合和高阶特征组合。
- 端到端模型,不需要人工特征工程
- FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习
- 评估模型时,用到了一个新的指标“Gini Normalization”
DeepFM与Wide&Deep的异同
相同点:
- 都包括wide和deep两部分,满足并行结构深度模型的框架
- 两者的DNN部分模型结构相同 两者的deep部分是一致的,都是DNN层
不同点:
- Wide&Deep模型的wide部分是高维线性模型,DeepFM的wide部分则是FM模型。
- Wide&Deep模型的输入向量维度很大,因为wide部分的特征包括了手工提取的pair-wise特征组合,大大提高计算复杂度。DeepFM的wide和deep部分共享相同的输入,可以提高训练效率,不需要额外的特征工程,用FM建模低阶的特征组合,用DNN建模高阶的特征组合,因此可以同时从raw feature中学习到高阶和低阶的特征交互。
- wide&deep需要做特征工程,二阶特征交叉需要靠特征工程来实现,通过wide部分发挥作用;DeepFM完全不需要做特征工程,直接输入原始特征即可,二阶特征交叉靠FM来实现,并且FM和DNN共享embedding;
- 从试验结果来看DeepFM效果优于wide&deep。
- 把FM Function的LR换成了FM,可以自动做特征组合。
- 在真实应用市场的数据集上实验验证,DeepFM在CTR预估的计算效率和AUC, LogLoss上超越了现有的模型((LR, FM, FNN, PNN, Wide&Deep)。如果想部署深度模型,可以考虑这个模型,这是目前效果最好的基准模型之一。
- Wide和Deep部分共享输入层
- 和Wide&Deep不同的是,DeepFM是端到端的训练,不需要人工特征工程。
- 共享feature embedding。FM和Deep共享输入和
feature embedding不但使得训练更快,而且使得训练更加准确。相比之下,Wide&Deep中,input vector非常大,里面包含了大量的人工设计的pairwise组合特征,增加了他的计算复杂度。 - Wide&Deep缺点:需要特征工程提取低阶组合特征
- Wide & Deep设计的初衷是想同时学习低阶和高阶组合特征,但是wide部分需要领域知识进行特征工程。
DeepFM架构图:
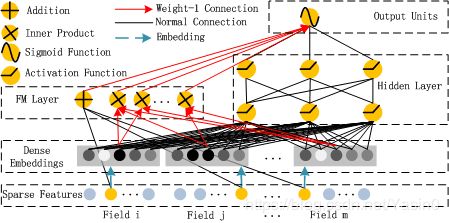
DeepFM包含两部分:因子分解机部分与神经网络部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的嵌入层输入。DeepFM 包括 FM和 DNN两部分,所以模型最终的输出也由这两部分组成,预测结果可以写为: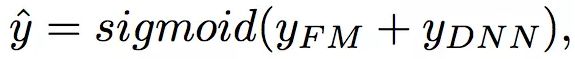
其中,DeepFM的输入可由连续型变量和类别型变量共同组成,且类别型变量需要进行One-Hot编码。One-Hot编码,导致了输入特征变得高维且稀疏。针对高维稀疏的输入特征,采用Word2Vec的词嵌入(WordEmbedding)思想,把高维稀疏的向量映射到相对低维且向量元素都不为零的空间向量中。
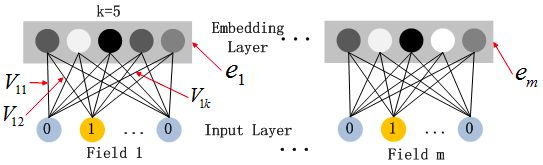
嵌入层
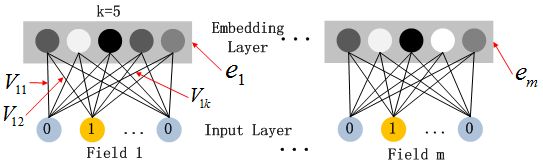
嵌入层(embedding layer)的结构如上图所示。通过嵌入层,尽管不同field的长度不同(不同离散变量的取值个数可能不同),但是embedding之后向量的长度均为K(我们提前设定好的embedding-size)。通过代码可以发现,在得到embedding之后,我们还将对应的特征值乘到了embedding上,这主要是由于fm部分和dnn部分共享嵌入层作为输入,而fm中的二次项如下:
嵌入层(embedding layer)的结构如上图所示。当前网络结构有两个有趣的特性,1)尽管不同field的输入长度不同,但是embedding之后向量的长度均为K。2)在FM里得到的隐变量Vik现在作为了嵌入层网络的权重。
这里的第二点如何理解呢,假设我们的k=5,首先,对于输入的一条记录,同一个field 只有一个位置是1,那么在由输入得到dense vector的过程中,输入层只有一个神经元起作用,得到的dense vector其实就是输入层到embedding层该神经元相连的五条线的权重,即vi1,vi2,vi3,vi4,vi5。这五个值组合起来就是我们在FM中所提到的Vi。在FM部分和DNN部分,这一块是共享权重的,对同一个特征来说,得到的Vi是相同的。
DeepFM中,很重要的一项就是embedding操作,embedding可以简单的理解为将一个特征转换为一个向量。在推荐系统当中,我们经常会遇到离散变量,如userid、itemid。对于离散变量,我们一般的做法是将其转换为one-hot,但对于itemid这种离散变量,转换成one-hot之后维度非常高,但里面只有一个是1,其余都为0。这种情况下,我们的通常做法就是将其转换为embedding。
embedding的过程其实就是一层全连接的神经网络,如下图所示:
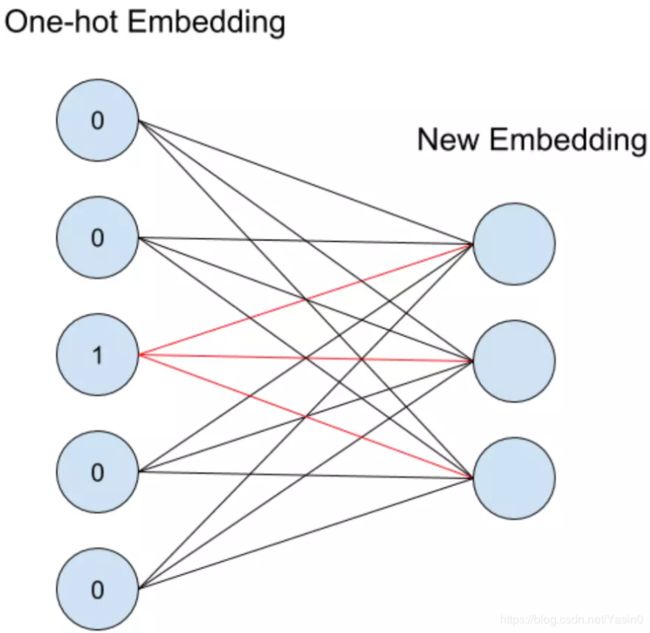
假设一个离散变量共有5个取值,也就是说one-hot之后会变成5维,我们想将其转换为embedding表示,其实就是接入了一层全连接神经网络。由于只有一个位置是1,其余位置是0,因此得到的embedding就是与其相连的图中红线上的权重。
FM部分
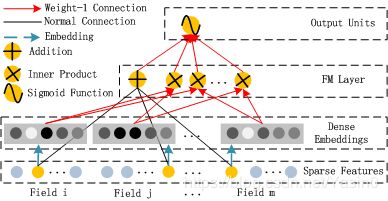
FM部分是一个因子分解机,因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,FM也可以很好的学习。
FM部分的输出由两部分组成:一个Addition Unit,多个内积单元。
这里的d是输入one-hot之后的维度,我们一般称之为feature_size。对应的是one-hot之前的特征维度,我们称之为field_size。
Addition Unit 反映的是1阶的特征。内积单元反映的是2阶的组合特征对于预测结果的影响。
FM的输出公式为:
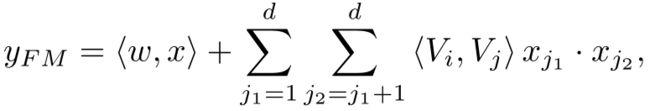
这里需要注意三点:
- 这里的wij,也就是
- 由于输入特征one-hot编码,所以embedding vector也就是输入层到Dense Embeddings层的权重,具体可阅读我在词嵌入的那些事儿(一)一文中的3.2小节。
- Dense Embeddings层的神经元个数是由embedding vector和field_size共同确定,再直白一点就是:神经元的个数为embedding vector*field_size。
注意:
虽然公式上Y_fm是所有部分都求和,是一个标量。但是从FM模块的架构图上我们可以看到,输入到输出单元的部分并不是一个标量,应该是一个向量。实际实现中采用的是FM化简之后的内积公式,最终的维度是:field_size + embedding_size
这里分别展开解释下维度的两部分是怎么来的,对于理解模型还是很重要的:
第一、
field_size对应的是。
这里的X是one-hot之后的,one-hot之后,我们认为X的每一列都是一个单独的维度的特征。这里我们表达的是X的1阶特征,说白了就是单独考虑X的每个特征,他们对最终预测的影响是多少。是多少那?是W!W对应的就是这些维度特征的权重。假设one-hot之后特征数量是feature_size,那么W的维度就是 (feature_size, 1)。
这里
这里解释下Embedding: W是一个矩阵,每一行对应X的一个维度的特征(这里是one-hot之后的维度,一定要注意)。W的列数为1,表示嵌入之后的维度是1。W的每一行对应一个特征,相当于是我们拿输入X_i作为一个index, X_i的任意一个Field i中只有1个为1,其余的都是0。哪个位置的特征值为1,那么就选中W中对应的行,作为嵌入后这个Field i对应的新的特征表示。对于每一个Field都执行这样的操作,就选出来了X_i Embedding之后的表示。注意到,每个Field都肯定会选出且仅选出W中的某一行(想想为什么?),因为W的列数是固定的,每一个Field都选出W.cols作为对应的新特征。把每个Field选出来的这些W的行,拼接起来就得到了X Embedding后的新的表示:维度是num(Field) * num(W.cols)。虽然每个Field的长度可能不同,但是都是在W中选择一行,所以选出来的长度是相同的。这也是Embedding的一个特性:虽然输入的Field长度不同,但是Embedding之后的长度是相同的。
什么?Embedding这么复杂,怎么实现的?非常简单!直接把X和W做内积即可。是的,你没看错,就是这么简单(tensoflow中封装了下,改成了tf.nn.embedding_lookup(embeddings, index),原理就是不做乘法,直接选出对应的行)。自己写个例子试试:X.shape=(1, feature_size), W.shape = (feture_size, embedding_size)就知道为什么选出1对应W的行和做内积结果是一样的是怎么回事了。
所以:FM模块图中,黑线部分是一个全连接!W就是里面的权重。把输入X和W相乘就得到了输出。至于Addition Unit,我们就不纠结了,这里并没有做什么加法,就把他当成是反应1阶特征对输出的影响就行了。
第二、
embedding_size对应的是
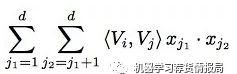
FM论文中给出了化简后的公式:
这里最后的结果中是在[1,K]上的一个求和。 K就是W的列数,就是Embedding后的维度,也就是embedding_size。也就是说,在DeepFM的FM模块中,最后没有对结果从[1,K]进行求和。而是把这K个数拼接起来形成了一个K维度的向量。
FM Component总结:
FM模块实现了对于1阶和2阶组合特征的建模。
没有使用预训练
没有人工特征工程
embedding矩阵的大小是:特征数量 * 嵌入维度。 然后用一个index表示选择了哪个特征。
需要训练的有两部分:
1. input_vector和Addition Unit相连的全连接层,也就是1阶的Embedding矩阵。 2. Sparse Feature到Dense Embedding的Embedding矩阵,中间也是全连接的,要训练的是中间的权重矩阵,这个权重矩阵也就是隐向量V。
深度部分
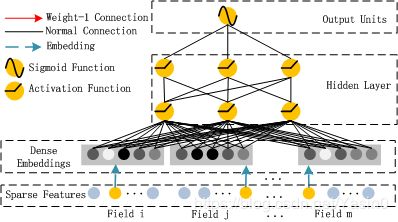
深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于CTR的输入一般是及其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。
Deep Component是用来学习高阶组合特征的。网络里面黑色的线是全连接层,参数需要神经网络去学习。
由于CTR或推荐系统的数据one-hot之后特别稀疏,如果直接放入到DNN中,参数非常多,我们没有这么多的数据去训练这样一个网络。所以增加了一个Embedding层,用于降低纬度。
这里继续补充下Embedding层,两个特点:
-
尽管输入的长度不同,但是映射后长度都是相同的.
embedding_size 或 k -
embedding层的参数其实是全连接的Weights,是通过神经网络自己学习到的。
这里DNN的作用是构造高维特征,且有一个特点:DNN的输入也是embedding vector。所谓的权值共享指的就是这里。
关于DNN网络中的输入a处理方式采用前向传播,如下所示:
这里假设a(0)=(e1,e2,...em) 表示 embedding层的输出,那么a(0)作为下一层 DNN隐藏层的输入,其前馈过程如下。
![]()
值得注意的是:FM模块和Deep模块是共享feature embedding的(也就是V)。
好处:
模型可以从最原始的特征中,同时学习低阶和高阶组合特征
不再需要人工特征工程。Wide&Deep中低阶组合特征就是同过特征工程得到的。
3、相关知识
Gini Normalization
代码中将CTR预估问题设定为一个二分类问题,绘制了Gini Normalization来评价不同模型的效果。这个是什么东西,不太懂,百度了很多,发现了一个比较通俗易懂的介绍。
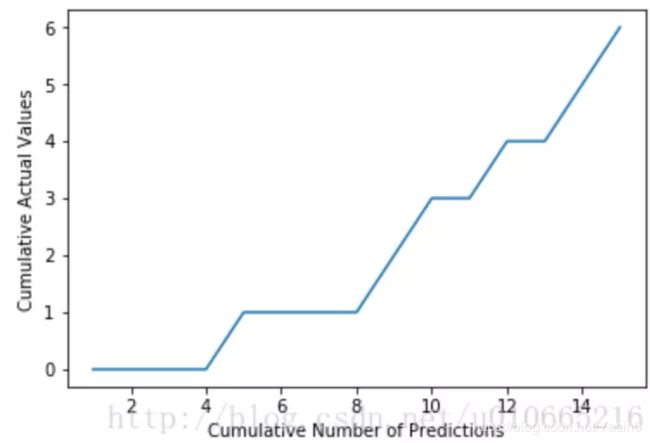
假设我们有下面两组结果,分别表示预测值和实际值:
predictions = [0.9, 0.3, 0.8, 0.75, 0.65, 0.6, 0.78, 0.7, 0.05, 0.4, 0.4, 0.05, 0.5, 0.1, 0.1]
actual = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
然后我们将预测值按照从小到大排列,并根据索引序对实际值进行排序:
Sorted Actual Values [0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1]
然后,我们可以画出如下的图片:
接下来我们将数据Normalization到0,1之间。并画出45度线。
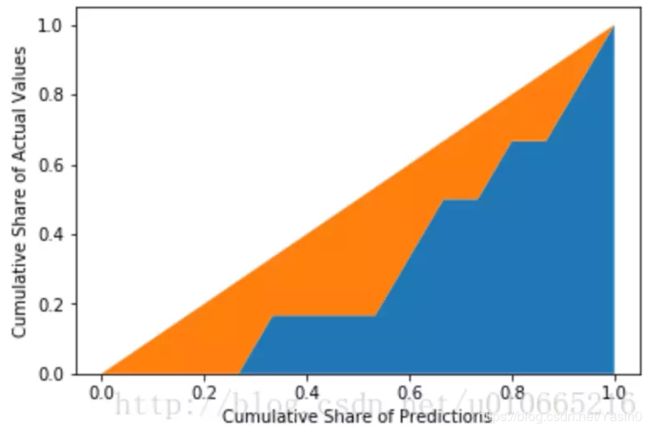
橙色区域的面积,就是我们得到的Normalization的Gini系数。
这里,由于我们是将预测概率从小到大排的,所以我们希望实际值中的0尽可能出现在前面,因此Normalization的Gini系数越大,分类效果越好。
对比其他模型
模型图: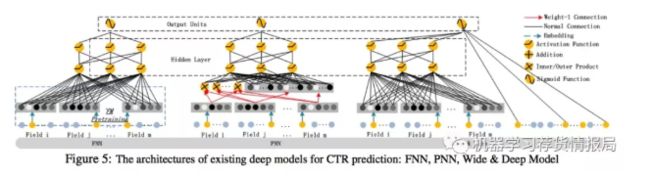
FNN
FNN is a FM-initialized feedforward neural network.
FNN使用预训练的FM来初始化DNN,然后只有Deep部分,不能学习低阶组合特征。
FNN缺点:
-
Embedding的参数受FM的影响,不一定准确
-
预训练阶段增加了计算复杂度,训练效率低
-
FNN只能学习到高阶的组合特征。模型中没有对低阶特征建模。
PNN
PNN:为了捕获高阶特征。PNN在第一个隐藏层和embedding层之间,增加了一个product layer。
根据product的不同,衍生出三种PNN:IPNN,OPNN,PNN* 分别对应内积、外积、两者混合。
作者为了加快计算,采用近似计算的方法来计算内积和外积。内积:忽略一些神经元。外积:把m*k维的vector转换成k维度的vector。由于外积丢失了较多信息,所以一般没有内积稳定。
但是内积的计算复杂度依旧非常高,原因是:product layer的输出是要和第一个隐藏层进行全连接的。
PNN缺点:
-
内积外积计算复杂度高。采用近似计算的方法外积没有内积稳定。
-
product layer的输出需要与第一个隐藏层全连接,导致计算复杂度居高不下
-
和FNN一样,只能学习到高阶的特征组合。没有对于1阶和2阶特征进行建模。
3.4 超参数建议
论文中还给出了一些参数的实验结果,直接给出结论,大家实现的时候可以参考下。
| 超参数 | 建议 | 备注 |
|---|---|---|
| 激活函数 | 1. IPNN使用tanh 2. 其余使用ReLU | |
| 学习方法 | Adam | |
| Dropout | 0.6~0.9 | |
| 隐藏层数量 | 3~5 | 根据实际数据大小调整 |
| 神经元数量 | 200~600 | 根据实际数据大小调整 |
| 网络形状 | constant | 一共有四种:固定、增长、下降、菱形。 |
PS: constant效果最好,就是隐藏层每一层的神经元的数量相同。
最后,模型对比图镇: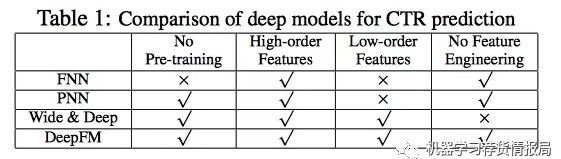
https://blog.csdn.net/john_xyz/article/details/78933253#%E7%9B%AE%E5%BD%95
https://www.hrwhisper.me/machine-learning-fm-ffm-deepfm-deepffm/
https://www.jianshu.com/p/e7b2d53ec42b
https://www.zybuluo.com/JeemyJohn/note/1197954