【Python学习笔记】-冒泡排序、插入排序、二分法查找
date:2017-03-30
冒泡排序
主要是拿一个数与列表中所有的数进行比对,若比此数大(或者小),就交换位置
#encoding:utf-8
l=[5,3,6,2,1,4,8,7,9]
for j in range(len(l)-1):
if l[j] > l[j+1]:
l[j],l[j+1] = l[j+1],l[j]
print(l)
运行上面的代码会发现最大的已经跑到最后一个位置了,那再加一次循环,循环列表的长度的次数,就可以把所有的都排好序了
#encoding:utf-8
l=[5,3,6,2,1,4,8,7,9]
for i in range(len(l)-1):
for j in range(len(l)-1-i):
#这里加了个-i,目的是为了简化循环次数,例如循环第三次的时候,后面两个的数就已经排好序了,没必要继续判断
if l[j] > l[j+1]:
l[j],l[j+1] = l[j+1],l[j]
print(l)插入排序
有一个已经有序的数据序列,要求在这个已经排好的数据序列中插入一个数,但要求插入后此数据序列仍然有序
—来自百度百科

基本思想为:每步将一个待排序的纪录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。
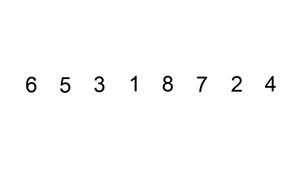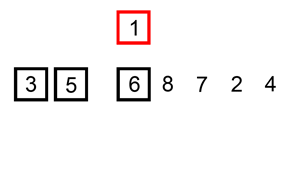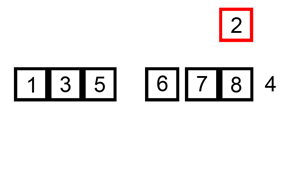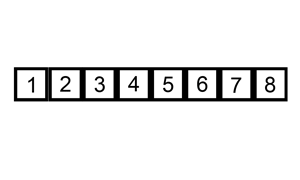
插入排序就是用一个数与一个已排好序的序列进行比对,从右向左进行。
例:5与3进行比较,5>3,将5与3不进行交换。l=[3,5],
此时再进行排序。4 < 5 l=[3,4,5] 3<4不进行交换,l=[3,4,5]
实例:
#encoding:utf-8
l=[1,5,4,7,9,3,2,6,8]
for i in range(1,len(l)):
for j in range(i,0,-1):
if l[j] < l[j-1]:
l[j],l[j-1] = l[j-1],l[j]
else:
break
print(l)
二分法查找
二分查找又称折半查找,优点是比较次数少,查找速度快,平均性能好;其缺点是要求待查表为有序表,且插入删除困难。
此方法适用于不经常变动而查找频繁的有序列表。
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
实例:
#encoding:utf-8
l = [1, 2, 3, 4, 5, 6, 7, 8, 9]
find_num = int(input('请输入一个数字:'))
start = 0
end = len(l) - 1
while True:
middle = (start + end) // 2
if find_num == l[middle]:
print('找到了!索引是:', middle)
break
elif find_num > l[middle]:
start = middle + 1
elif find_num < l[middle]:
end = middle - 1
if start > end:
print('没找到!', find_num)
break