MySQL基础教程 更全
本文结合资料对原文进行了大量补充和修改
本教程以跳蚤市场数据库为背景 仅包含部分实例 推荐打开你的命令行与本文同步练习
原文:mysql 基础教程 很全 博主:by甘蔗
补充资料来源:MySQL教程:MySQL数据库学习宝典(从入门到精通)C语言中文网
编译环境
- MySQL 8.0
- 命令行
(一)数据库操作
数据库关键字推荐大写,分号别漏,单词不要拼错
显示当前所有数据库
SHOW databases;
创建数据库
CREATE DATABASE 数据库名;
CREATE DATABASE flea_market;
将某数据库设置为当前(默认)数据库
USE 数据库名;
USE flea_market;
删除数据库
DROP DATABASE 数据库名;
DROP DATABASE flea_market;
(二)数值类型
1)整数类型及浮点数类型

2) 日期/时间类型(详细请移步至原教程查看)
包括 YEAR、TIME、DATE、DATETIME 和 TIMESTAMP
3) 字符串类型
包括 CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM 和 SET 等
4) 二进制类型
包括 BIT、BINARY、VARBINARY、TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB
其中TEXT、带有VAR字段的都是可变长度类型
(三)数据表
一个数据库中包含多个数据表。MySQL中,表的结构定义为:
| Field | Type | Null | Key | Default | Extra |
其中,各个字段的含义如下:
- Null:表示该列是否可以存储 NULL 值。
- Key:表示该列是否已编制索引。PRI 表示该列是表主键的一部分,UNI 表示该列是 UNIQUE 索引的一部分,MUL 表示在列中某个给定值允许出现多次。
- Default:表示该列是否有默认值,如果有,值是多少。
- Extra:表示可以获取的与给定列有关的附加信息,如 AUTO_INCREMENT 等。
针对表的表的结构定义,可根据需要对不同的字段设置约束关系
- 主键约束 PRIMARY
- 外键约束 FORGIVEN…REFERENCES…
- 唯一约束 UNIQUE
- 检查约束 CHECK
- 默认值约束 DEFAULT
- 非空约束 NOT NULL
各约束的添加删除操作请移步至原文查看
创建数据表
在创建表之前确保执行过USE语句将当前数据库设置为当前操作对象
CREATE TABLE 数据表名 (字段名 字段类型);
CREATE TABLE flea_market
->(
->item VARCHAR(100) NOT NULL, // 非空约束
->price INT UNSIGNED AUTO_INCREMENT,
->expire_date DATE DEFAULT'2099-12-31', //默认值约束
->PRIMARY KEY ( item, price ) // 单/复合主键约束
->FOREIGN KEY(deptId) REFERENCES China_flea_market(item) // 外键约束 没有China_flea_market这个父类表时删除此句
->)ENGINE=InnoDB DEFAULT CHARSET=utf8; // 设置存储引擎和字符集
查看数据表
SHOW TABLES;
查看数据表字段信息
DESCRIBE 数据表名;
DESCRIBE flea_market;
数据表重命名
ALTER TABLE flea_market RENAME TO fm;
删除数据表
DROP TABLE 数据表名;
DROP TABLE flea_market;
(四)记录操作
增
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
INSERT INTO flea_market(item, price, expire_date)
VALUES
('四六级耳机', 36, '2019-12-31'),
('進撃の巨人BD', 450, '2020-02-04')
('iPad2018', 2018, '2019-7-14')
('iPad2018', 2299, '2019-12-31');
看
SELECT * FROM tb_courses;
改
UPDATE table_name SET field1=newvalue1, field2=newvalue2
[WHERE Clause];
UPDATE flea_market SET price=500 WHERE item='進撃の巨人BD'; // 修改价格至500
删
DELETE FROM table_name [WHERE Clause];
DELETE FROM flea_market WHERE item='四六级耳机';
查(条件查询)
SELECT field1, field2,...fieldN FROM table_name1, table_name2...
WHERE condition1 AND / OR condition2.....
SELECT * from flea_market WHERE item='iPad2018';
(五)查询
特定字段
SELECT item FROM flea_market;
分组查找
SELECT DISTINCT item FROM flea_market;
设置别名
SELECT item, price FROM flea_market AS fl;
将item和price两个字段提取出来作为一个名为fl的子表
其他主要查询功能:
- 去重查找 DISTINCT
- 模糊查找 LIKE
- 限制记录条数的查询 LIMIT
- 查询排序 ORDER BY
- 内/外连接查询 INNER JOIN、LEFT/RIGHT JOIN
- 子查询/嵌套查询 IN
- 分组查询 GROUP BY
- 指定过滤条件 HAVING
- 正则表达式查询 REGEXP
(六)字段操作
增
ALTER TABLE 数据表名 ADD 新增字段 字段类型;
ALTER TABLE flea_market ADD item_type VARCHAR(10) NOT NULL DEFAULT 'NULL';
看
直接使用DESCRIBE<表名>;或者SELECT * FROM <表名>;都行
改
// 修改字段数据类型
ALTER TABLE flea_market MODIFY item_type CHAR(100);
// 修改字段名称及数据类型
ALTER TABLE flea_market CHANGE item_type item_status CHAR(10);
// 修改其他属性
ALTER TABLE flea_market MODIFY item_type CHAR(100) NOT NULL DEFAULT'NONE';
删
ALTER TABLE 数据表名 DROP 字段名;
ALTER TABLE flea_market DROP item_type;
(七)索引
索引简介
- 索引是 MySQL 中一种十分重要的数据库对象。它是数据库性能调优技术的基础,常用于实现数据的快速检索。
- 索引就是根据表中的一列(一个字段)或若干列按照一定顺序建立的列值与记录行之间的对应关系表,实质上是一张描述索引列的列值与原表中记录行之间一一对应关系的有序表。
在 MySQL 中,通常有以下两种方式访问数据库表的行数据:
1) 顺序访问
1顺序访问是在表中实行全表扫描,从头到尾逐行遍历,直到在无序的行数据中找到符合条件的目标数据。这种方式实现比较简单,但是当表中有大量数据的时候,效率非常低下。例如,在几千万条数据中查找少量的数据时,使用顺序访问方式将会遍历所有的数据,花费大量的时间,显然会影响数据库的处理性能。
2) 索引访问
索引访问是通过遍历索引来直接访问表中记录行的方式。使用这种方式的前提是对表建立一个索引,在列上创建了索引之后,查找数据时可以直接根据该列上的索引找到对应记录行的位置,从而快捷地查找到数据。索引存储了指定列数据值的指针,根据指定的排序顺序对这些指针排序。
例如,在学生基本信息表 students 中,如果基于 student_id 建立了索引,系统就建立了一张索引列到实际记录的映射表,当用户需要查找 student_id 为 12022 的数据的时候,系统先在 student_id 索引上找到该记录,然后通过映射表直接找到数据行,并且返回该行数据。因为扫描索引的速度一般远远大于扫描实际数据行的速度,所以采用索引的方式可以大大提高数据库的工作效率。
根据检索方式的物理和逻辑上的不同,索引又分为以下几种:
-
物理
- 二叉树索引 BTree
- 哈希索引 Hash
-
逻辑
- 普通索引 INDEX / KEY
- 唯一索引 UNIQUE
- 主键索引 PRIMARY KEY
- 空间索引 GEOMETRY
- 全文索引
详细内容请移步至参考资料
创建普通索引
可以在创建表时顺便创建索引
CREATE TABLE flea_market2
-> (
-> item VARCHAR(100) NOT NULL, // 非空约束
-> price INT DEFAULT 0,
-> expire_date DATE DEFAULT '2099-12-31',
-> status CHAR(10) DEFAULT 'NONE',
-> INDEX(item)
-> );
创建以后DESCRIBE一下可以看到KEY这一列出现了MUL,则该字段是非唯一索引的第一列,允许在列中多次出现给定值。
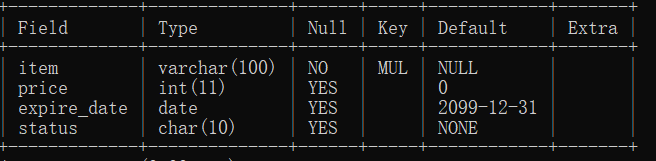
也可以为已有表添加索引
CREATE INDEX 索引名 ON 数据表名 (字段名);
CREATE INDEX index1 ON flea_market (item);
创建唯一索引
索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
与创建普通索引的方法类似 只是多了一个UNIQUE关键字
CREATE UNIQUE INDEX 索引名 ON 数据表名 (字段名);
CREATE UNIQUE INDEX index2 ON flea_market (price);
查看索引
SHOW INDEX FROM 数据表名;
SHOW INDEX FROM flea_market;
该语句会返回一张结果表
![]()
该表有如下几个字段,每个字段所显示的内容说明如下。
- Table:表的名称。
- Non_unique:用于显示该索引是否是唯一索引。若不是唯一索引,则该列的值显示为 1;若是唯一索引,则该列的值显示为 0。
- Key_name:索引的名称。
- Seq_in_index:索引中的列序列号,从 1 开始计数。
- Column_name:列名称。
- Collation:显示列以何种顺序存储在索引中。在 MySQL 中,升序显示值“A”(升序),若显示为 NULL,则表示无分类。
- Cardinality:显示索引中唯一值数目的估计值。基数根据被存储为整数的统计数据计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL 使用该索引的机会就越大。
- Sub_part:若列只是被部分编入索引,则为被编入索引的字符的数目。若整列被编入索引,则为 NULL。
- Packed:指示关键字如何被压缩。若没有被压缩,则为 NULL。
- Null:用于显示索引列中是否包含 NULL。若列含有 NULL,则显示为 YES。若没有,则该列显示为 NO。
- Index_type:显示索引使用的类型和方法(BTREE、FULLTEXT、HASH、RTREE)。
- Comment:显示评注。
删除索引
DROP INDEX 索引名 ON 数据表名
DROP INDEX index1 ON flea_market;
(八)视图
- 视图是一个虚拟表,同真实表一样,视图包含一系列带有名称的列和行数据,但视图并不是数据库真实存储的数据表。
- 视图是数据的窗口,而表是内容。表是实际数据的存放单位,而视图只是以不同的显示方式展示数据,其数据来源还是实际表。
- 视图的建立和删除只影响视图本身,不影响对应的基本表。
创建视图
CREATE VIEW 视图名 AS <SELECT语句>;
CREATE VIEW view_flea_market AS SELECT * FROM flea_market;
或
CREATE VIEW view_flea_market
-> (s_item,s_price)
-> AS SELECT item,price
-> FROM flea_market;
查询视图
同表类似,使用DESCRIBE或SELECT语句可以分别查看视图的字段信息和记录信息
删除视图
DROP VIEW 视图名1 ,视图名2...;
DROP VIEW view_flea_market;
(九)自定义函数
自定义函数是由 SQL 语句和过程式语句组成的代码片段,并且可以被应用程序和其他 SQL 语句调用
创建函数
CREATE FUNCTION PriceIs500()
-> RETURNS VARCHAR(100)
-> RETURN
-> (SELECT item FROM flea_market
-> WHERE price=500);
第一次使用的时候可能会出现这种情况
ERROR 1418 (HY000): This function has none of DETERMINISTIC, NO SQL, or READS SQL DATA in its declaration and binary logging is enabled (you *might* want to use the less safe log_bin_trust_function_creators variable)
原因是开启了bin-log,需要指明函数类型
这里的解决方法是执行下列语句
set global log_bin_trust_function_creators=TRUE;
子查询调用函数
SELECT <自定义函数名>;
SELECT PriceIs500();
注意,通过这种方法返回的函数值不能超过一个,如果有多个对象需要返回则可以使用存储过程(见后文)
删除函数
DROP FUNCTION PriceIs500;
不需要括号
(十)存储过程
存储过程是一组为了完成特定功能的 SQL 语句集合。使用存储过程的目的是将常用或复杂的工作预先用 SQL 语句写好并用一个指定名称存储起来,这个过程经编译和优化后存储在数据库服务器中,因此称为存储过程。当以后需要数据库提供与已定义好的存储过程的功能相同的服务时,只需调用CALL 存储过程名即可自动完成
存储过程和函数的差别可参考下文
Mysql存储过程和函数区别介绍 作者:北斜杠
不带参数的存储过程
创建存储过程
DELIMITER将结束符从;变成//
DELIMITER //
CREATE PROCEDURE MediumPriceItem()
-> BEGIN
-> SELECT item FROM flea_market WHERE price<=500 AND price>=200;
-> END //
调用存储过程
先将结束符变回; DELIMITER和逗号之间的空格不要漏了(掉坑 )
DELIMITER ;
CALL MediumPriceItem();
修改存储过程
写错就删了重新写吧(/▽\)
删除存储过程
DROP PROCEDURE 存储过程名;
DROP PROCEDURE MediumPriceItem;
带参数的存储过程
创建存储过程
CREATE <触发器名> < BEFORE | AFTER >
<INSERT | UPDATE | DELETE >
ON <表名> FOR EACH Row<触发器主体>
CREATE PROCEDURE GetPrice
-> (IN parameter VARCHAR(100))
-> BEGIN
-> SELECT price FROM flea_market WHERE item=parameter;
-> END //
调用存储过程
CALL GetPrice('iPad2018');
(十一)触发器
触发器是一个特殊的存储过程,不同的是执行存储过程要使用 CALL 语句来调用,而触发器的执行不需要使用 CALL 语句来调用,也不需要手工启动,只要一个预定义的事件发生就会被 MySQL自动调用。
MySQL中的触发器中按照条件分类有:INSERT 触发器、UPDATE 触发器和 DELETE 触发器。按照作用时间分类有:BEFORE触发器、AFTER触发器。BEFORE和AFTER的区别有点类似与C语言中的i++和++i,自行体会~
引发触发器执行的事件一般如下:
- 增加一条学生记录时,会自动检查年龄是否符合范围要求(BEFORE INSERT)
- 每当删除一条学生信息时,自动删除其成绩表上的对应记录(AFTER DELETE)
- 每当更新一条数据时,在数据库存档表中保留原版本备份副本(BEFORE UPDATE)
创建触发器
操作的对象TABLE如下图所示

创建触发器
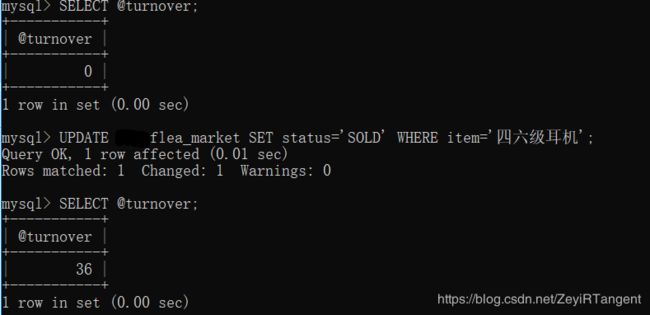
CREATE TRIGGER Turnover
-> BEFORE UPDATE ON bit_flea_market
-> FOR EACH ROW
-> SET @turnover=@turnover+NEW.price;
@turnover是用户变量,接下来需要设置初始值。NEW是保留字,对应的还有OLD

触发触发器
初始化用户变量
SET turnover=0;
触发
UPDATE flea_market SET status='SOLD' WHERE item='四六级耳机';
查看结果
SELECT turnover=0;
删除触发器
DROP TRIGGER 触发器名;
DROP TRIGGER Turnover;
触发器主体如果是多条语句的话可参考下面这篇文章
mysql触发器trigger 实例详解 作者:周伯通的麦田
(十三)[其他内容]
以下部分内容本文就不涉及了,因为用的次数不多,感兴趣可以移步至参考资料学习~
- 事务
- 用户
- 备份、恢复
实战应用
1、mysql统计-关于学生成绩
https://blog.csdn.net/mayanyun2013/article/details/50845667
[与教程无关] 自我总结(闲言碎语时间 )
数据库学得蛮快的,语法结构相当简单,只要练习练习很快就可以掌握基础内容。ところが、关于数据库的语法知识是有一些了,但是对于其工作生态和原理还不是很了解,DataGrip下了也还不会用,更别提和Java或者这些编程语言嵌合,还有很多东西要学的。
从早上9点敲到下午3点,敲字敲到忘了午餐。中间还没保存闪退一次白写了5个章节…(。﹏。*)…点个外卖吧