Android常见问题总结(一)
1.Android消息机制
Message
消息分为硬件产生的消息(如按钮、触摸)和软件生成的消息;
MessageQueue
消息队列的主要功能向消息池投递消息(MessageQueue.enqueueMessage)和取走消息池的消息(MessageQueue.next);
Looper
不断循环执行(Looper.loop),按分发机制将消息分发给目标处理者。
Handler
消息辅助类,主要功能向消息池发送各种消息事件(Handler.sendMessage)和处理相应消息事件(Handler.handleMessage);
图文总结:
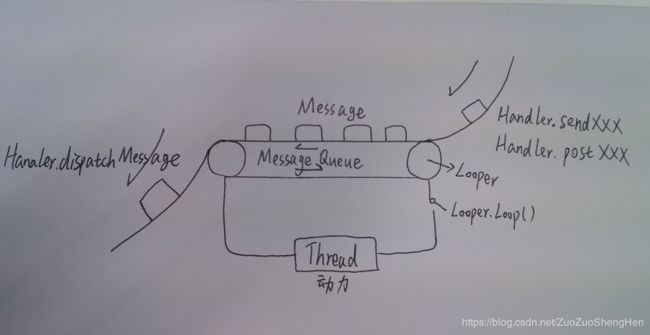
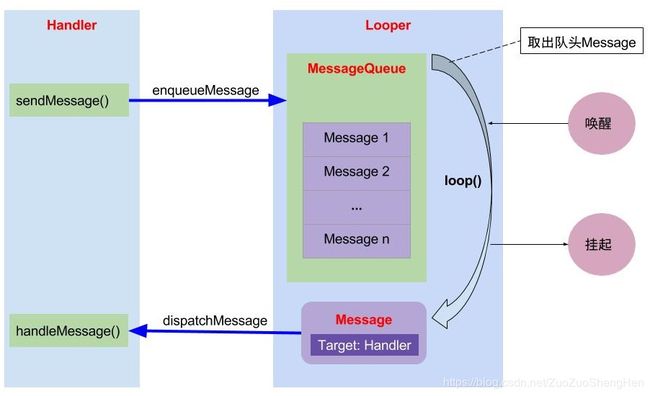
- Handler通过sendMessage()发送Message到MessageQueue队列;
- Looper通过loop(),不断提取出达到触发条件的Message,并将Message交给target来处理;
- 经过dispatchMessage()后,交回给Handler的handleMessage()来进行相应地处理。
- 将Message加入MessageQueue时,处往管道写入字符,可以会唤醒loop线程;如果MessageQueue中没有Message,并处于Idle状态,则会执行IdelHandler接口中的方法,往往用于做一些清理性地工作。
消息分发的优先级:
- Message的回调方法:
message.callback.run(),优先级最高; - Handler的回调方法:
Handler.mCallback.handleMessage(msg),优先级仅次于1; - Handler的默认方法:
Handler.handleMessage(msg),优先级最低。
2.Android View绘制流程,当一个TextView的实例调用setText()方法后执行了什么?
当一个应用启动时,会启动一个主 Activity,Android 系统会根据 Activity 的布局来对它进行绘制。如图:
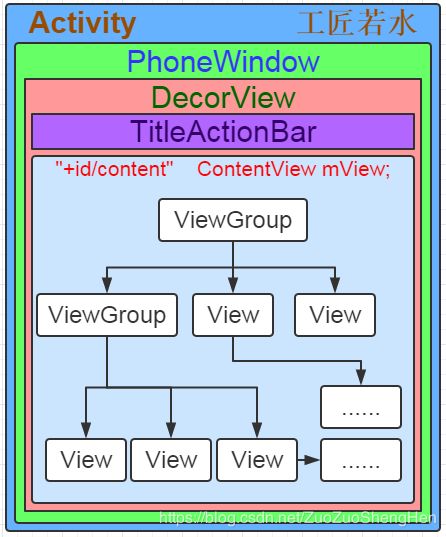
绘制会从根视图 ViewRoot 的 performTraversals() 方法开始,从上到下遍历整个视图树,每个 View 控制负责绘制自己,而 ViewGroup 还需要负责通知自己的子 View 进行绘制操作。视图操作的过程可以分为三个步骤,分别是测量(Measure)、布局(Layout)和绘制(Draw)。performTraversals 方法在 类 ViewRootImpl 内,其核心代码如下。
int childWidthMeasureSpec = getRootMeasureSpec(mWidth, lp.width);
int childHeightMeasureSpec = getRootMeasureSpec(mHeight, lp.height);
...
// 测量
performMeasure(childWidthMeasureSpec, childHeightMeasureSpec);
...
// 布局
performLayout(lp, mWidth, mHeight);
...
// 绘制
performDraw();MeasureSpec
MeasureSpec 表示的是一个 32 位的整数值,它的高 2 位表示测量模式 SpecMode,低 30 位表示某种测量模式下的规格大小 SpecSize。MeasureSpec 是 View 类的一个静态内部类,用来说明应该如何测量这个View。
三种测量模式。
- UNSPECIFIED:不指定测量模式,父视图没有限制子视图的大小,子视图可以是想要的任何尺寸,通常用于系统内部,应用开发中很少使用到。
- EXACTLY:精确测量模式,当该视图的 layout_width 或者 layout_height 指定为具体数值或者 match_parent 时生效,表示父视图已经决定了子视图的精确大小,这种模式下 View 的测量值就是 SpecSize 的值。
- AT_MOST:最大值模式,当前视图的 layout_width 或者 layout_height 指定为 wrap_content 时生效,此时子视图的尺寸可以是不超过父视图运行的最大尺寸的任何尺寸。
对 DecorView 而言,它的 MeasureSpec 由窗口尺寸和其自身的 LayoutParams 共同决定;对于普通的 View,它的 MeasureSpec 由父视图的 MeasureSpec 和其本身的 LayoutParams 共同决定。
Measure
Measure 用来计算 View 的实际大小。页面的测量流程从 performMeasure 方法开始。
Layout
Layout 过程用来确定 View 在父容器的布局位置,他是父容器获取子 View 的位置参数后,调用子 View 的 layout 方法并将位置参数传入实现的。
Draw
Draw 操作用来将控件绘制出来。
3.Android dalvik虚拟机和Art虚拟机的优化升级点
Android4.4以前使用dalvik,4.4以后使用art。
Art优点:
1.加快app冷启动速度。
2.提升GC速度
3.提供功能全面的debug特性
Art缺点:
1.APP安装速度慢,因为在APK安装的时候要生成可运行.oat文件
2.APK占用空间大,因为在APK安装的时候要生成可运行.oat文件
4.热修复原理,你都了解过几种热修复框架
Tinker、Sophix
比较:
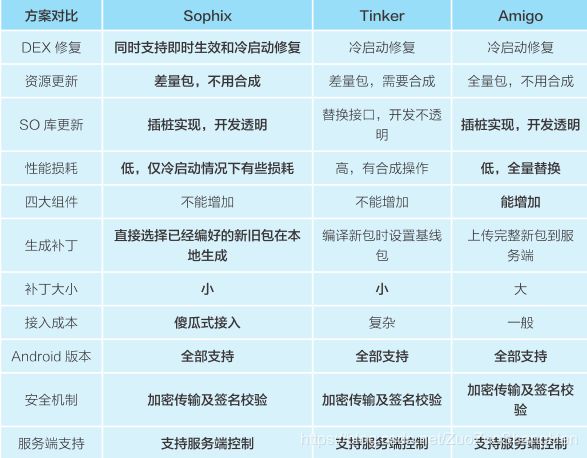
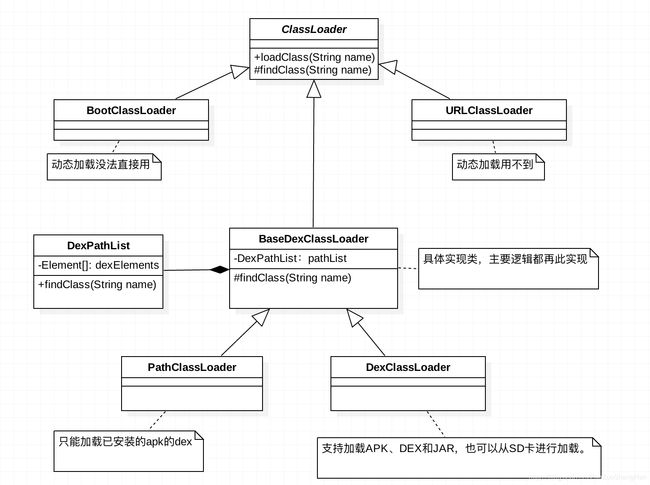
Tinker
Tinker利用了Android 的类加载机制,Android中有两个主要的Classloader,PathClassLoader和DexClassLoader,它们都继承自BaseDexClassLoader,这两个类加载器的主要区别是:Android系统通过PathClassLoader来加载系统类和主dex中的类。而DexClassLoader则可用于加载指定路径的apk、jar或dex文件。上述两个类都是继承自BaseDexClassLoader
1.新dex与旧dex通过dex差分算法生成差异包 patch.dex
2.将patch dex下发到客户端,客户端将patch dex与旧dex合成为新的全量dex
3.将合成后的全量dex 插入到dex elements前面(此部分和QQ空间机制类似),完成修复
BaseDexClassLoader 的构造函数中创建一个DexPathList实例,DexPathList的构造函数会创建一个dexElements 数组,BaseDexClassLoader 在findclass方法中调用了pathList.findClass,这个方法中会遍历dexpathlist中的dexElements数组,然后初始化DexFile,如果DexFile不为空那么调用DexFile类的loadClassBinaryName方法返回Class实例。简言之,ClassLoader会遍历dexelements,然后加载这个数组中的dex文件. ClassLoader在加载到正确的类之后就会停止加载此类,因此我们将包含正确的类的Dex文件中插入在dexElements数组前面就可以完成对问题类的修复,补丁属于冷启动生效。
Sophix
使用了热启动的底层替换方案及冷启动的类加载方案,两个方案使用的补丁是相同的。优先热启动。
底层替换方案:
原理:在已经加载的类中直接替换掉原有方法,是在原有类的结构基础上进行修改的。在hook方法入口ArtMethod时,通过构造一个新的ArtMethod实现替换方法入口的跳转。
应用:能即时生效,Andfix采用此方案。
缺点:底层替换稳定性不好,适用范围存在限制,通过改造代码绕过限制既不优雅也不方便,并且还没提供资源及so的修复。
类加载方案:
原理:让app重新启动后让ClassLoader去加载新的类。如果不重启,原来的类还在虚拟机中无法重复加载。
优点:修复范围广,限制少。
应用:腾讯系包括QQ空间,手QFix,Tinker采用此方案。
QQ空间会侵入打包流程。
QFix需要获取底层虚拟机的函数,不稳定。
Tinker是完整的全量dex加载。
dex的大小占整个apk比例较低,一个app里的dex文件大小不是主要部分,占空间大的主要是资源文件。
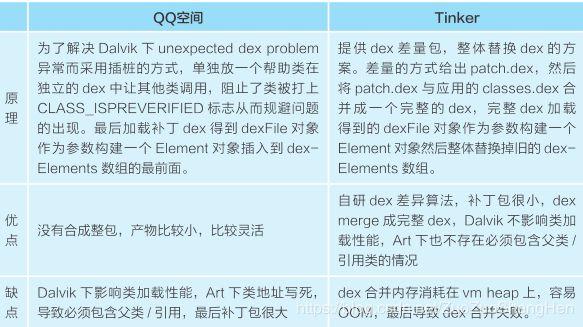
QQ空间的插桩原理
将一个单独无关版主类放到一个单独的dex中,原dex中所有类的构造函数都引用这个类,一般的实现方法都是侵入dex打包流程,利用.class字节码修改技术,在所有.class文件的构造函数中引用这个帮助类。
Tinker与Sophix方案不同之处
Tinker采用dex merge生成全量DEX方案。反编译为smali,然后新apk跟基线apk进行差异对比,最后得到补丁包。
Dalvik下Sophix和Tinker相同,在Art下,Sophix不需要做dex merge,因为Art下本质上虚拟机已经支持多dex的加载,要做的仅仅是把补丁dex作为主dex(classes.dex)加载而已:
将补丁dex命名为classes.dex,原apk中的dex依次命名为classes(2, 3, 4...).dex就好了,然后一起打包为一个压缩文件。然后DexFile.loadDex得到DexFile对象,最后把该DexFile对象整个替换旧的dexElements数组就好了。

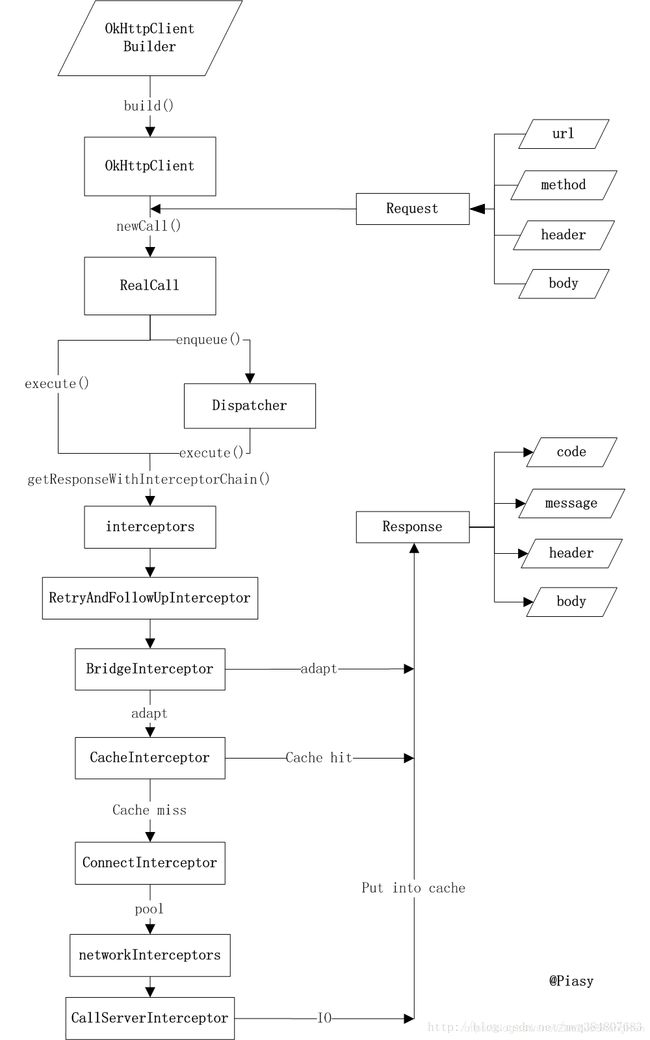
5.OkHttp的原理
OkHttp的底层是通过Java的Socket发送HTTP请求与接受响应的(这也好理解,HTTP就是基于TCP协议的),但是OkHttp实现了连接池的概念,即对于同一主机的多个请求,其实可以公用一个Socket连接,而不是每次发送完HTTP请求就关闭底层的Socket,这样就实现了连接池的概念。而OkHttp对Socket的读写操作使用的OkIo库进行了一层封装。大致流程如下:
6.JavaGC机制
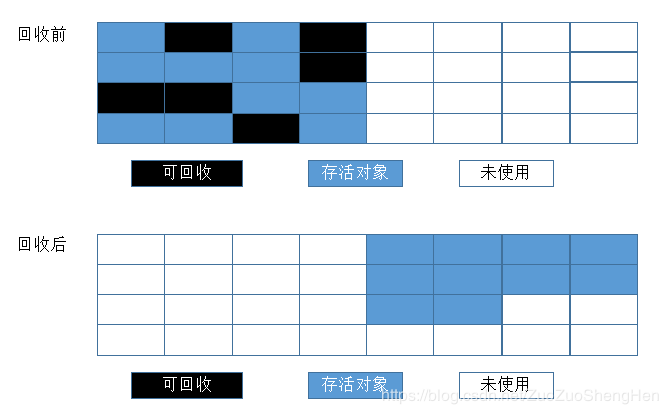
1.复制法
复制算法是为了解决效率问题而出现的,它将可用的内存分为两块,每次只用其中一块,当这一块内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已经使用过的内存空间一次性清理掉。这样每次只需要对整个半区进行内存回收,内存分配时也不需要考虑内存碎片等复杂情况,只需要移动指针,按照顺序分配即可。复制算法的执行过程如图:
不过这种算法有个缺点,内存缩小为了原来的一半,这样代价太高了。现在的商用虚拟机都采用这种算法来回收新生代,不过研究表明1:1的比例非常不科学,因此新生代的内存被划分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor。每次回收时,将Eden和Survivor中还存活着的对象一次性复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden区和Survivor区的比例为8:1,意思是每次新生代中可用内存空间为整个新生代容量的90%。当然,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖老年代进行分配担保(Handle Promotion)。
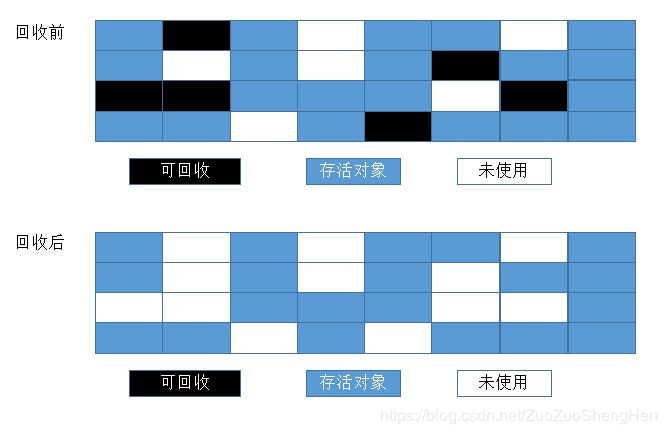
2.标记清除
标记-清除算法就如同它的名字样,分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,标记完成后统一回收所有被标记的对象。这种算法的不足主要体现在效率和空间,从效率的角度讲,标记和清除两个过程的效率都不高;从空间的角度讲,标记清除后会产生大量不连续的内存碎片, 内存碎片太多可能会导致以后程序运行过程中在需要分配较大对象时,无法找到足够的连续内存而不得不提前触发一次垃圾收集动作。标记-清除算法执行过程如图:
3.标记整理
复制算法在对象存活率较高的场景下要进行大量的复制操作,效率很低。万一对象100%存活,那么需要有额外的空间进行分配担保。老年代都是不易被回收的对象,对象存活率高,因此一般不能直接选用复制算法。根据老年代的特点,有人提出了另外一种标记-整理算法,过程与标记-清除算法一样,不过不是直接对可回收对象进行清理,而是让所有存活对象都向一端移动,然后直接清理掉边界以外的内存。标记-整理算法的工作过程如图:
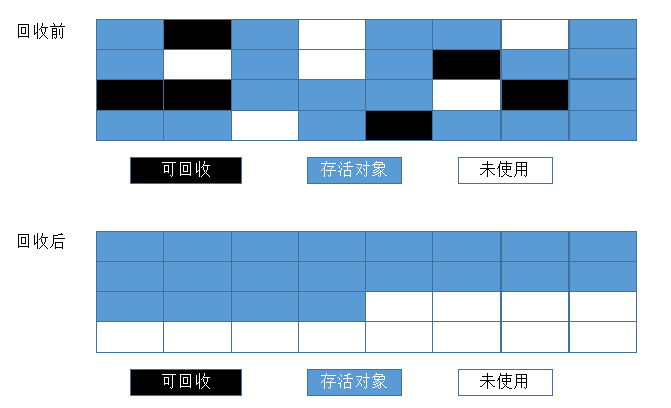
4.分代收集法
现代商用虚拟机基本都采用分代收集算法来进行垃圾回收。这种算法没什么特别的,无非是上面内容的结合罢了,根据对象的生命周期的不同将内存划分为几块,然后根据各块的特点采用最适当的收集算法。大批对象死去、少量对象存活的(新生代),使用复制算法,复制成本低;对象存活率高、没有额外空间进行分配担保的(老年代),采用标记-清理算法或者标记-整理算法。
7.HashMap实现机制,如何实现HashMap线程安全
HashMap的结构:
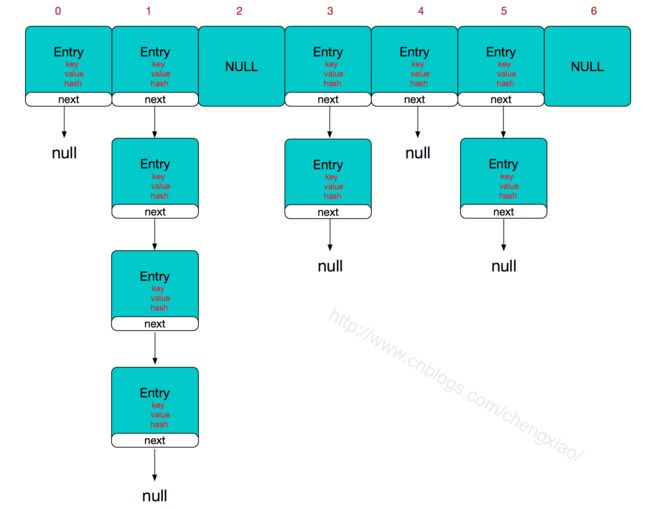
底层是个Entry数组,Entry由key、value、hash、next构成。存储方式为数组加链表形式。当有hashcode冲突时,采用链表形式存储
HashMap线程安全使用的方法
1.HashTable(Synchronized 方法) 效率低
2.ConCurrentHashMap (Java 8 Segment 摒弃了锁段的概念)
3.Synchronized Map
//Hashtable
Map hashtable = new Hashtable<>();
//synchronizedMap
Map synchronizedHashMap = Collections.synchronizedMap(new HashMap());
//ConcurrentHashMap
Map concurrentHashMap = new ConcurrentHashMap<>();
Java8调整:
1.创建链表的时候,7是插入到表头,8是插入到表尾
2.当链表长度大于8时,会对链表的结构做出变化
3.当链表长度大于32时,链表的结构会变成树的结构,加快get的查询速度
10.可重入锁的实现,公平锁和非公平锁的定义
1.volatile int state
2.Thread
3.Node双向队列
公平锁:线程按顺序依次执行(直到线程释放才执行下一个线程)
非公平锁:线程按队列排列,线程释放过程中有新的线程可与下一个等待的线程竞争
10.都用过哪些常用的数据结构,谈谈对树的理解
Map(HashMap) Collections(ArrayList、LinkedList、Vector)
从效率上说,ArrayList效率最高;
Vector线程安全
需要频繁的做插入删除操作使用LinkedList
11.WebView的优化
1.延迟图片的加载
2.JS延迟加载
3.合理使用缓存
12.使用RxJava的经验
Rxjava2+ Retrofit2
13.谈谈对设计模式的理解,开发过程中主要用到了哪些设计模式?
单例模式、构建者模式、观察者模式、策略模式等
参考博文:
Android消息机制:
https://blog.csdn.net/iispring/article/details/47180325
http://gityuan.com/2015/12/26/handler-message-framework/
Android绘制流程:
https://www.jianshu.com/p/c151efe22d0d
Tinker热修复原理:
https://www.jianshu.com/p/2216554d3291
Sophix热修复原理:
https://www.jianshu.com/p/4d30ce3e55dd
OKhttp原理:
https://www.jianshu.com/p/9ed2c2f2a52c
JavaGC原理:
https://www.cnblogs.com/xiaoxi/p/6486852.html
HashMap数据结构原理:
https://www.cnblogs.com/chengxiao/p/6059914.html
HashMap线程安全:
http://www.importnew.com/21396.html