python或pyspark,sql对一个dataframe,排序并排名

输入:
输出:
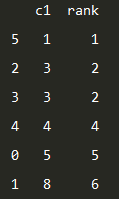
具体代码:
一:纯python代码
import pandas as pd
data=pd.DataFrame({'c1':[5,8,3,3,4,1]})
print(data)
d1= data.sort_values(by='c1')
d1['rank']=d1.rank(method='min').astype(int)
print(d1)二:pyspark代码
import pandas as pd
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext()
sqlContext = SQLContext(sc)
df=pd.DataFrame({'c1':[5,8,3,3,4,1]})
sdf = sqlContext.createDataFrame(df)
(sdf.select("c1",F.rank().over(Window.orderBy("c1")).alias("rank") ).show())
#(sdf.select("c1",F.rank().over(Window.orderBy(sdf.c1.desc())).alias("rank") ).show())#这也可以的
三:sql代码
窗口函数语法:其中[]中的内容可以省略,窗口函数的适用范围:只能在select子句中使用。
<窗口函数> over ([partition by <列清单>]order by <排序用列清单>)窗口函数大体可以分为以下两种:1.能够作为窗口函数的聚合函数(sum,avg,count,max,min)
2.rank,dense_rank。row_number等专用窗口函数。
语法的基本使用方法:使用rank函数
rank函数是用来计算记录排序的函数。
select product_name, product_type, sale_price,
rank () over (partition by product_type
order by sale_price) as ranking
from Product;
partition by 能够设定排序的对象范围,类似于group by语句,这里就是以product_type划分排序范围。
order by能够指定哪一列,何种顺序进行排序。也可以通过asc,desc来指定升序降序。
窗口函数兼具分组和排序两种功能。通过partition by分组后的记录集合称为窗口。
然而partition by不是窗口函数所必须的:
select product_name, product_type, sale_price,
rank () over (order by sale_price) as ranking
from Product;
专用函数的种类:1.rank函数:计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
2.dense_rank函数:同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
3.row_number函数:赋予唯一的连续位次。
select product_name, product_type, sale_price,
rank () over (order by sale_price) as ranking,
dense_rank () over (order by sale_price) as dense_ranking,
row_number () over (order by sale_price) as row_num
from Product;参考链接: https://blog.csdn.net/qq_33517844/article/details/58665472 https://www.cnblogs.com/cssdongl/p/6203726.html https://dzone.com/articles/difference-between-rownumber
sql:窗口函数 https://blog.csdn.net/qq_41805514/article/details/81772182