Kafka session.timeout.ms heartbeat.interval.ms参数的区别以及对数据存储的一些思考
Kafka session.timeout.ms heartbeat.interval.ms参数的区别以及对数据存储的一些思考
在计算机世界中经常需要与数据打交道,这也是我们戏称CURD工程师的原因之一。写了两年代码,接触了不少存储系统,Redis、MySQL、Kafka、Elasticsearch…慢慢地发现背后的一些公共的设计思想总是那么似曾相识,再深究一下,就会发现一些隐藏在这些系统背后的数学理论。
生活中产生的大量数据需要交由计算机来处理,根据处理方式的不同分为OLTP和OLAP两大类应用。有些数据比如登录流水、系统日志信息,源源不断,先采集下来抛给消息中间件(Kafka);有些数据,比如一条描述用户特征的记录,就适合存储到MySQL,并按日期建查询索引。也就是说:面对大量的数据,把数据存储起来只是一小步,重要的是如何把这些数据用起来,体现到存储系统则是:有没有一套方便的查询接口能够方便快速地查到我们想要的数据。如果将数据放到Kafka上了,那要怎么查?如果把数据放到MySQL上了,非常适合针对高cardinality列建B+树索引查询,而对于文本类的数据,放到ES上,则基于倒排索引这种数据结构,根据tf-idf、bm25等这些衡量文档相似度的算法来快速地获得想要的数据。
从这也可以看出,不同的存储系统,为了满足"查询",它们背后的存储原理(所采用的数据结构)是不同的。而对于这些存储系统而言,都面临着两个问题:高可靠性和高可用性。可靠性,在我看来,是站在存储系统本身来看,一般是讨论单个实例如何保证数据的可靠。比如,一个正在运行的MySQL实例,它根据checkpoint机制,通过redo log 文件来保证持久性,另外还有double write buffer,保证数据页的写入是可靠的。类似地,在Elasticsearch里面也有translog机制,用来保证数据的可靠性。所以,想深入了解存储系统,不妨对比一下它们之间的各种checkpoint机制。
数据为什么需要有可靠性呢?根本原因还是内存是一种易失性存储,根据冯偌依曼体系结构,程序总是从内存中取数据交给CPU做运算。如果数据没有fsync到磁盘,如果系统宕机那数据会不会丢?
而对于可用性,是从Client角度而言的。即我不管你背后是一个redis实例还是一个redis 集群,你只管正常地给我提供好读写服务就好了。这里为了避免SPOF,分布式集群就派上用场了,一台机器挂了,另一台机器顶上。在分布式系统中,需要管理好各个存储实例,这时就需要节点的角色划分,比如master节点、controller节点之类的称呼。毕竟管理是要有层级的嘛,大家角色都一样,怎么管理呢?在这一点上,Redis集群与Kafka集群或者Elasticsearch集群有很大的不同,具体体现在Redis本质上是一个P2P结构的集群,而Elasticsearch和Kafka 采用的主从模型,为什么这么说呢?Redis虽然也有Master节点和Slave节点之分,但它的各个Master节点之间是平等的,Redis的数据分布方式是hash16384个槽到各个master节点上,每个master节点负责处理落在这些槽内的数据,这是从数据分布的角度来定义的Master节点,而Kafka中的Controller节点、Elasticsearch中的master节点并不是从数据分布的角度定义的,而是从集群元信息维护、集群管理的角度定义的,关于它们之间的具体区别我在这篇文章中也有过一些描述。另外,MySQL作为关系型数据库,受数据完整性约束、事务支持的限制,在分布式集群能力上要弱一些。
最近碰到一个问题,多个业务往向一个Kafka topic发送消息,有些业务的消费量很大,有些业务的消息量很小。因Kafka尚未较好地支持按优先级来消费消息,导致某些业务的消息消费延时的问题。一种简单的解决方案是再增加几个Topic,面对一些系统遗留问题,增加Topic带来的是生产者和消费者处理逻辑复杂性。一种方法是使用Kafka Standalone consumer,先使用consumer.partitionFor("TOPIC_NAME")获取topic下的所有分区信息,再使用consumer.assign(partitions)显示地为consumer指定消费分区。另一种方法是基于consumer group 自定义Kafka consumer的分区分配策略,那这时候就得对Kafka目前已有的分区分配策略有所了解,并且明白什么时候、什么场景下触发rebalance?
Kafka consumer要消费消息,哪些的分区的消息交给哪个consumer消费呢?这是consumer的分区分配策略,默认有三个:range、round-robin、sticky。说到round-robin这个算法,真是无处不在,它经常用在一些需要负载均衡的场景。比如Elasticsearch client向ES Server发送搜索请求时,因为默认情况下每台ES节点都可做为coordinator节点接收用户的查询请求,而在coordinator节点上需要汇总所有分片的查询结果,这需要消耗大量的内存和CPU,因此ES Client 也是基于round-robin算法选择将查询请求发送到哪个ES节点上。如果你仔细留意,会发现在Redis里面也会有这个算法的身影。再比如说:Redis LRU Cache中关于Key的access pattern,一般服从幂指分布(power-law distribution):具有某一特征的一小部分的Key访问频率远远大于其他的Key,正如这种访问特性,LRU能达到很好的缓存效果。另外,Redis sorted set类型是基于skiplist实现,新的skipNode节点最大层数设置为多少合适呢?这也是个power-law distribution问题,其源码注释中:
Returns a random level for the new skiplist node we are going to create. The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL (both inclusive), with a powerlaw-alike distribution where higher levels are less likely to be returned.
其实,我想表达的是有些思想或者说是解决方案,它是通用的,应用于各个不同的存储系统中,将它们对比起来看,能更好地理解系统背后的原理。
最近每次想写一些笔记时,脑海里总是出现一些其他各种各样的想法。这次本来主要是想写kafka 中这两个配置参数:session.timeout.ms 和 heartbeat.interval.ms的区别的,结果就先扯了一通数据存储相关的东西。
下面继续:
因为一个topic往往有多个分区,而我们又会在一个consumer group里面创建多个消费者消费这个topic,因此:就有了一个问题:哪些的分区的消息交给哪个consumer消费呢?这里涉及到三个概念:consumer group,consumer group里面的consumer,以及每个consumer group有一个 group coordinator。conusmer分区分配是通过组管理协议来实施的:具体如下:
consumer group里面的各个consumer都向 group coordinator发送JoinGroup请求,这样group coordinator就有了所有consumer的成员信息,于是它从中选出一个consumer作为Leader consumer,并告诉Leader consumer说:你拿着这些成员信息和我给你的topic分区信息去安排一下哪些consumer负责消费哪些分区吧
接下来,Leader consumer就根据我们配置的分配策略(由参数partition.assignment.strategy指定)为各个consumer计算好了各自待消费的分区。于是,各个consumer向 group coordinator 发送SyncGroup请求,但只有Leader consumer的请求中有分区分配策略,group coordinator 收到leader consumer的分区分配方案后,把该方案下发给各个consumer。画个图,就是下面这样的:
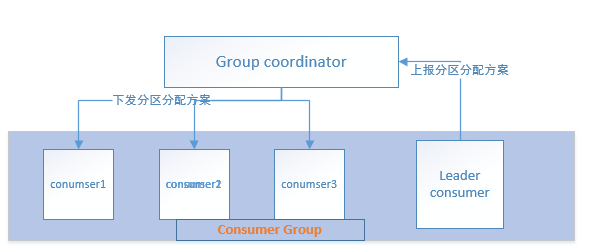
而在正常情况下 ,当有consumer进出consumer group时就会触发rebalance,所谓rebalance就是重新制订一个分区分配方案。而制订好了分区分配方案,就得及时告知各个consumer,这就与 heartbeat.interval.ms参数有关了。具体说来就是:每个consumer 都会根据 heartbeat.interval.ms 参数指定的时间周期性地向group coordinator发送 hearbeat,group coordinator会给各个consumer响应,若发生了 rebalance,各个consumer收到的响应中会包含 REBALANCE_IN_PROGRESS 标识,这样各个consumer就知道已经发生了rebalance,同时 group coordinator也知道了各个consumer的存活情况。
那为什么要把 heartbeat.interval.ms 与 session.timeout.ms 进行对比呢?session.timeout.ms是指:group coordinator检测consumer发生崩溃所需的时间。一个consumer group里面的某个consumer挂掉了,最长需要 session.timeout.ms 秒检测出来。举个示例session.timeout.ms=10,heartbeat.interval.ms=3
session.timeout.ms是个"逻辑"指标,它指定了一个阈值---10秒,在这个阈值内如果coordinator未收到consumer的任何消息,那coordinator就认为consumer挂了。而heartbeat.interval.ms是个"物理"指标,它告诉consumer要每3秒给coordinator发一个心跳包,heartbeat.interval.ms越小,发的心跳包越多,它是会影响发TCP包的数量的,产生了实际的影响,这也是我为什么将之称为"物理"指标的原因。
如果group coordinator在一个heartbeat.interval.ms周期内未收到consumer的心跳,就把该consumer移出group,这有点说不过去。就好像consumer犯了一个小错,就一棍子把它打死了。事实上,有可能网络延时,有可能consumer出现了一次长时间GC,影响了心跳包的到达,说不定下一个heartbeat就正常了。
而heartbeat.interval.ms肯定是要小于session.timeout.ms的,如果consumer group发生了rebalance,通过心跳包里面的REBALANCE_IN_PROGRESS,consumer就能及时知道发生了rebalance,从而更新consumer可消费的分区。而如果超过了session.timeout.ms,group coordinator都认为consumer挂了,那也当然不用把 rebalance信息告诉该consumer了。
在kafka0.10.1之后的版本中,将session.timeout.ms 和 max.poll.interval.ms 解耦了。也就是说:new KafkaConsumer对象后,在while true循环中执行consumer.poll拉取消息这个过程中,其实背后是有2个线程的,即一个kafka consumer实例包含2个线程:一个是heartbeat 线程,另一个是processing线程,processing线程可理解为调用consumer.poll方法执行消息处理逻辑的线程,而heartbeat线程是一个后台线程,对程序员是"隐藏不见"的。如果消息处理逻辑很复杂,比如说需要处理5min,那么 max.poll.interval.ms可设置成比5min大一点的值。而heartbeat 线程则和上面提到的参数 heartbeat.interval.ms有关,heartbeat线程 每隔heartbeat.interval.ms向coordinator发送一个心跳包,证明自己还活着。只要 heartbeat线程 在 session.timeout.ms 时间内 向 coordinator发送过心跳包,那么 group coordinator就认为当前的kafka consumer是活着的。
在kafka0.10.1之前,发送心跳包和消息处理逻辑这2个过程是耦合在一起的,试想:如果一条消息处理时长要5min,而session.timeout.ms=3000ms,那么等 kafka consumer处理完消息,group coordinator早就将consumer 移出group了,因为只有一个线程,在消息处理过程中就无法向group coordinator发送心跳包,超过3000ms未发送心跳包,group coordinator就将该consumer移出group了。而将二者分开,一个processing线程负责执行消息处理逻辑,一个heartbeat线程负责发送心跳包,那么:就算一条消息需要处理5min,只要底heartbeat线程在session.timeout.ms向group coordinator发送了心跳包,那consumer可以继续处理消息,而不用担心被移出group了。另一个好处是:如果consumer出了问题,那么在 session.timeout.ms内就能检测出来,而不用等到 max.poll.interval.ms 时长后才能检测出来。
一次kafka consumer 不断地 rebalance 分析
明白了session.timeout.ms 和 max.poll.interval.ms 和 heartbeat.interval.ms三个参数的意义后,现在来实际分析一下项目中经常碰到的 consumer rebalance 错误。
一般我们是在一个线程(用户线程)里面执行kafka consumer 的while true循环逻辑的,其实这里有2个线程:一个是用户线程,另一个是心跳线程。心跳线程,我想就是根据heartbeat.interval.ms参数配置的值周期性向coordinator发送心跳包以证明consumer还活着。
如果消息处理逻辑过重,也即用户线程需要执行很长的时间处理消息,然后再提交offset。咋一看,有一个后台心跳线程在不断地发送心跳啊,那为什么group coordinator怎么还老是将consumer移出group,然后导致不断地rebalance呢?
我想,问题应该是 max.poll.interval.ms这个参数引起的吧,因为在ERROR日志中,老是提示:消息处理逻辑花了太长的时间,要么减少max.poll.records值,要么增大session.timeout.ms的值。尽管有后台heartbeat 线程,但是如果consumer的消息处理逻辑时长超过了max.poll.interval.ms ,那么此consumer提交offset就会失败:
org.apache.kafka.clients.consumer.CommitFailedException: Commit cannot be completed since the group has already rebalanced and assigned the partitions to another member. This means that the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time message processing. You can address this either by increasing the session timeout or by reducing the maximum size of batches returned in poll() with max.poll.records.
此外,在用户线程中,一般会做一些失败的重试处理。比如通过线程池的 ThreadPoolExecutor#afterExecute()方法捕获到异常,再次提交Runnable任务重新订阅kafka topic。本来消费处理需要很长的时间,如果某个consumer处理超时:消息处理逻辑的时长大于max.poll.interval.ms (或者消息处理过程中发生了异常),被coordinator移出了consumer组,这时由于失败的重试处理,自动从线程池中拿出一个新线程作为消费者去订阅topic,那么意味着有新消费者加入group,就会引发 rebalance,而可悲的是:新的消费者还是来不及处理完所有消息,又被移出group。如此循环,就发生了不停地 rebalance 的现象。
参考资料
kafka kip-62
原文:https://www.cnblogs.com/hapjin/p/10926882.html
最近碰到一些中文分词的归一化、分词结果的准确度(分词生成自定义的词)、定制 ES Analyzer插件满足特殊符号搜索、中文行业术语搜索 需求的问题...有时间再写一篇。