【Linux】线程总结:初识、创建、等待、终止、分离
学习环境 : Centos6.5 Linux 内核 2.6
Linux线程部分总结分为两部分:(1)线程的使用 ,(2)线程的同步与互斥。
第一部分线程的使用主要介绍,线程的概念,创建线程,线程退出,以及线程的终止与分离。
第二部分主要介绍在多线程环境下,使用同步与互斥保护共享资源,有互斥锁,条件变量,信号量,以及读写锁。
第一部分开始
初识线程
线程:也称轻量级进程(Lightweight Process , LWP),是程序执行流的最小单元。而多线程就是指,在一个进程中有多个执行流,在同时执行。
为什么需要多线程呢?
在客户端,我们需要界面和用户交互动作,此时就可以在后台线程去处理交互逻辑。比如下载一个文件利用一个线程,而同时还可以用一个线程响应用户的其他操作。
在服务端,如http服务器,会同时有多个请求需要处理,此时利用多线程可以大大提高请求的处理效率。
线程与进程的区别:
进程是资源分配的基本单位,而线程是调度的基本单元。操作系统中每一个执行的进程,都有它自己的地址空间,而同一进程中可以有多个线程,也就是多个执行流在同时执行。这里的同时,如果是单核处理器,则此时并不是真正意义上的同时,由于处理器运行速度很快,给每个执行流分配了时间片,在单核处理器中微观上还是顺序执行,而在多核处理器中,就是真正意义上的并行。由于同一进程的多个线程共享同一地址空间,因此线程之间有互相共享的资源,也有彼此独占的资源。
线程之间共享的资源主要有:
- 地址空间
- 数据段和代码段
- 全局变量
- 文件描述符表
- 信号处理方式(忽略或者有自定义动作)
- 用户ID和组ID
- 当前工作目录
每个线程各有一份的资源主要有:
- 线程ID
- 上下文(寄存器,程序计数器,栈指针)
- 栈空间
- 状态字
- 信号屏蔽字
- 调度优先级
进程与线程的区别归纳如下几点:
1. 地址空间:进程间相互独立,每个进程都有自己独立的地址空间,同一进程的各线程间共享地址空间。某个进程内的线程在其他进程内不可见。
2. 通信关系:进程间通信有管道,消息队列,共享内存,信号量。线程间通信可以直接读写全局变量来进行通信。不管是进程还是线程,通信时可能出现数据不一致的情况,需要用同步互斥机制来保证数据的一致性。
3. 切换和调度:由于进程间独占数据段代码段等信息,所以切换进程的时候,需要把进程间独占的资源切换去,把要执行的进程资源换进来,而线程是进程的子集,共享大部分资源,切换时只需要保存上下文相关信息就好,所以线程切换的开销比进程切换的开销小。
线程的三种状态
线程主要有三种状态分别是就绪、阻塞、运行。
就绪:线程具备运行的所有条件,逻辑上已可以运行,在等待处理机。
阻塞:指线程在等待某一时间的发生,如I/O操作。
运行:占有处理器正在运行。
注:关于进程与线程之间阻塞状态的关系,在文末做了个实验。
线程的控制
主要学习如何创建一个线程,线程有哪些终止方式,以及怎么获取一个线程的运行结果,判断线程是否异常退出,线程生命结束时有没有”遗言“。
这里学习的线程库函数由POSIX标准定义的,称为POSIX thread 或者 pthread。在Linux中函数位于libpthread共享库中,在gcc编译或者Makefile中记得要加上 -lpthread选项,用来指定要链接的库。函数在执行错误时的错误信息将作为返回值返回,并不修改全局变量errno,也就无法通过
perror()打印错误信息。
创建线程
#include 描述:创建一个线程,用第一个参数线程标识符,第二个参数设置线程属性,第三个参数指定线程函数运行的起始地址(函数指针),第四个参数是运行函数的参数。
实例:下面的代码创建了两个线程,并分别在线程中调用pthread_self()打印各自的线程ID,以及调用 getpid() 打印进程ID,为了对比也在创建线程的Main执行流中打印线程ID,和进程ID。
#include // pthread_create()
#include // sleep()
#include // getpid()
// 打印每个线程的ID, 和进行ID
void * run_1(void *arg) // 线程1 执行代码
{
sleep(1);
printf(" thread 1 tid is %u, pid is %u \n", pthread_self(), getpid());
}
void * run_2(void *arg) // 线程2 执行代码
{
sleep(1);
printf(" thread 2 tid is %u, pid is %u \n", pthread_self(), getpid());
}
int main()
{
pthread_t tid1, tid2;
pthread_create(&tid1, NULL, run_1, NULL ); // 创建线程1
pthread_create(&tid2, NULL, run_2, NULL ); // 创建线程2
sleep(2);
printf("I am main tid is %u, pid is %u \n", pthread_self(), getpid());
return 0;
}

从上图执行结果以及对代码的分析可以得出:
1).线程1 和线程2 的进程ID一样,可以说明同一个进程可以拥有多个线程,即多个执行流。
2 ) .我们发现在main 执行流中打印线程ID ,与创建的线程差异并不大,也就是说main 执行流也是一个线程。也可以这样理解:在Linux中,一个进程默认有一个线程。单线程也就是单进程。
3 ).在代码中之所以要在main 的执行流中sleep(2),是因为线程执行顺序与操作系统的调度算法有关系,为了保证创建的线程1 和线程2 先执行,故在 main的打印之前加上sleep(2)。
4 ).在线程1 和线程2 的执行代码中都是一开始就sleep(1),而我们在main中创建线程的时候却是先创建的线程1,但是打印结果却是,线程2 先打印,这进一步证实了 3) 中所说,同一个进程中哪一个线程先执行与操作系统调度有关。
5 ). 有一点需要强调,当main 结束的时候,运行到return,或者调用exit(),所有线程也会随之结束,下面的小程序证明这点。
#include // sleep()
#include // exit()
void *run( void * arg)
{
while(1)
{
printf("I am still alive ... \n");
sleep(1);
}
}
int main()
{
pthread_t tid1;
pthread_create(&tid1, NULL, run, NULL);
sleep(2);
printf(" The main thread ends and all threads end.\n");
exit(0); // main thread quit
return 0;
}
执行结果:新线程每隔1秒打印一次,主线程在2秒后exit,新线程也随之结束。

终止线程
如果需要只终止某个线程而不是整个进程都终止,有三种方法。
1). 从线程函数return,对主线程不使用,在main函数中return 相当于exit。
#include 
2 ). 一个线程可以调用pthread_cancel() 终止同一进程中的另一个线程。比较复杂,暂不分析。
3 ).线程可以调用 pthread_exit() 终止自己。
#include 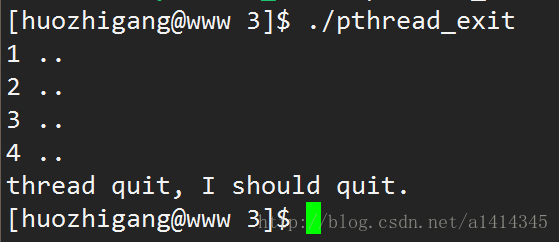
等待线程
说说我理解的为什么需要线程等待,有时候需要让一个线程去执行一段代码,我们需要知道它是否帮我们完成了指定的要求,或者异常终止,这时候我们就需要获取线程运行结果,线程退出可以通过返回值带出或者通过pthread_exit()参数带出,拿到它的“遗言”。线程等待也有回收资源的用处,如果一个线程结束运行但没有被等待,那么它类似于僵尸进程,占用的资源在进程结束前都不会被回收,所以当一个线程运行完成后,我们应该等待回收资源。
我们可以注意到在上面的例子中,线程退出返回值和pthread_exit()的参数都是NULL,说明我们根本不关心线程的”死活“。
还有一个用处,在上面的例子中,我们都是在主线程中sleep()函数来防止新创建的线程还未结束,整个进程就结束,而现在我们可以用线程等待函数来达到这个目的。
#include 描述:调用该函数的线程将挂起等待,直到id为thread的线程终止。thread线程以不同的方法终止,通过pthread_join() 得到的终止状态是不同的,主要有如下几种:
thread线程通过return 返回, retval 所指向的单元里存放的是 thread线程函数的返回值。
thread线程是被的线程调用
pthread_cancel()异常终止掉,retval 所指向的单元存放的是常数PTHREAD_CANCELED.- 如果thread线程调用
pthread_exit()终止的,retval 所指向的单元存放的是传给pthread_exit的参数。
下面来举个栗子,拿到线程的”遗言“:
#include 执行结果,成功得到线程的”遗言“:
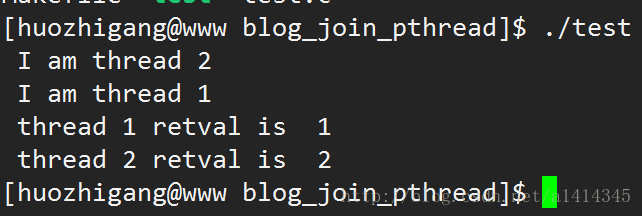
注意:在上面的例子中,我们带出的是整型值,如果需要带出别的数据类型,则需要使用全局变量或者malloc动态分配的空间,不能带出线程执行函数内的变量,因为执行结束后,栈里的数据变成垃圾数据。
线程分离
无论何时,一个线程是可结合(joinable )的或者是分离(detached)的。
当线程属于可结合时,它能够被其他线程join或者cancel回收资源。相反一个已经处于分离的线程是不能被join或cancel,资源会在终止时自动释放。
创建一个线程,默认是可结合的,为了防止资源的泄露,我们可以显示的调用pthread_join() 回收资源。对一个处于可结合的线程调用pthread_join()后,可以将线程置于分离状态。不能对同一个线程调用两个join,对一个已经分离的线程调用join会返回错误号。
其实在上面的例子中,已经有过通过join将一个线程分离,但是当在一个线程中通过调用pthread_join()来回收资源时,调用者就会被阻塞,如果需要回收的线程数目过多时,效率就大大下降。比如在一个Web 服务器中, 主线程为每一个请求创建一个线程去响应动作,我们并不希望主线程也为了回收资源而被阻塞,因为可能在阻塞的同时有新的请求,我们可以再使用下面的方法,让线程办完事情后自动回收资源。
1 ). 在子线程中调用pthread_detach( pthread_self() )。
2 ).在主线程中调用pthread_detach( tid )。
可以将线程状态设为分离。运行结束后会自动释放所有资源。
#include 执行结果:

补文中提到的实验:
说明:之所有会有这个实验,是因为之前一直对进程阻塞时,线程是什么状态不是很清楚,以及线程阻塞会对进程和别的线程有什么影响。因此本次基于Linux中的轻量级线程做出实验,实验结果不一定对所有平台都有效。
实验环境:centos 6.5 Linux 2.6
实验内容:
1). 阻塞一个线程,看其他线程是否也会阻塞,如果其他线程也阻塞,说明线程阻塞会导致整个进程阻塞。若其他线程未阻塞,则说明线程间状态独立。
#include 实验结果:

结果分析:
通过实验结果可以看到,在线程3阻塞前后,线程1 和 2 的运行状态没有任何变化。可以说明 一个线程的阻塞并不会导致所有线程都阻塞。
2).不阻塞线程,阻塞进程,看其他线程是否阻塞,若其他线程也阻塞,则说明进程阻塞会导致所有线程阻塞。反之则反。
#include 实验结果:
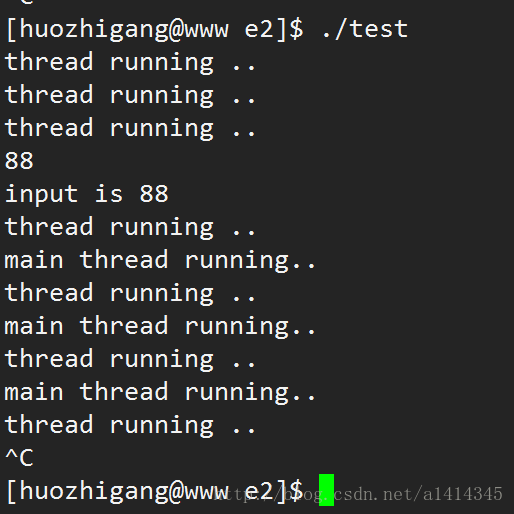
结果分析:
第二个实验就有点尴尬,因为严格意义上来说在现在的实验环境中让进程阻塞,也只能让主线程阻塞,而主线程除了结束的时候会导致整个进程都结束,和别的线程没有什么大的区别。因此实验结果和实验1区别并不大。
第一部分到此结束。