一次堆外OOM问题排查
背景
线上服务有一台机器访问不通(一个管理平台),在公司的服务治理平台上查看服务的状况是正常的,说明进程还在。进程并没有完全crash掉。去线上查看机器日志,发现了大量的OOM异常:
017-03-15 00:00:00.041 [WARN] qtp1947699202-120772 nio handle failed
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658) ~[?:1.7.0_76]
at java.nio.DirectByteBuffer.(DirectByteBuffer.java:123) ~[?:1.7.0_76]
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306) ~[?:1.7.0_76]
at sun.nio.ch.Util.getTemporaryDirectBuffer(Util.java:174) ~[?:1.7.0_76]
at sun.nio.ch.IOUtil.read(IOUtil.java:195) ~[?:1.7.0_76]
at sun.nio.ch.SocketChannelImpl.read(SocketChannelImpl.java:379) ~[?:1.7.0_76]
at org.eclipse.jetty.io.nio.ChannelEndPoint.fill(ChannelEndPoint.java:235) ~[jetty-io-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.io.nio.SelectChannelEndPoint.fill(SelectChannelEndPoint.java:326) ~[jetty-io-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.http.HttpParser.fill(HttpParser.java:1040) ~[jetty-http-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.http.HttpParser.parseNext(HttpParser.java:280) ~[jetty-http-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.http.HttpParser.parseAvailable(HttpParser.java:235) ~[jetty-http-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.server.AsyncHttpConnection.handle(AsyncHttpConnection.java:82) ~[jetty-server-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.io.nio.SelectChannelEndPoint.handle(SelectChannelEndPoint.java:628) [jetty-io-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.io.nio.SelectChannelEndPoint$1.run(SelectChannelEndPoint.java:52) [jetty-io-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:608) [jetty-util-8.1.10.v20130312.jar:8.1.10.v20130312]
at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:543) [jetty-util-8.1.10.v20130312.jar:8.1.10.v20130312]
at java.lang.Thread.run(Thread.java:745) [?:1.7.0_76]
at java.lang.Thread.run(Thread.java:745) [?:1.7.0_76]
2017-03-15 00:00:00.718 [WARN] elasticsearch[Thundra][transport_client_worker][T#6]{New I/O worker #6} AbstractNioSelector Unexpected exception in the selector loop.
java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658) ~[?:1.7.0_76]
at java.nio.DirectByteBuffer.(DirectByteBuffer.java:123) ~[?:1.7.0_76]
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306) ~[?:1.7.0_76]
at org.jboss.netty.channel.socket.nio.SocketReceiveBufferAllocator.newBuffer(SocketReceiveBufferAllocator.java:64) ~[netty-3.10.5.Final.jar:?]
at org.jboss.netty.channel.socket.nio.SocketReceiveBufferAllocator.get(SocketReceiveBufferAllocator.java:41) ~[netty-3.10.5.Final.jar:?]
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:62) ~[netty-3.10.5.Final.jar:?]
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.process(AbstractNioWorker.java:108) ~[netty-3.10.5.Final.jar:?]
at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:337) [netty-3.10.5.Final.jar:?]
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:89) [netty-3.10.5.Final.jar:?]
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178) [netty-3.10.5.Final.jar:?]
at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108) [netty-3.10.5.Final.jar:?]
at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42) [netty-3.10.5.Final.jar:?]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145) [?:1.7.0_76]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615) [?:1.7.0_76]
at java.lang.Thread.run(Thread.java:745) [?:1.7.0_76] 可以发现是Direct buffer memory的native memory满了,无法分配堆外内存。由于jetty使用的是nio,nio里面大量的使用native memeory。无法分配native memory之后,导致所有的请求都无效
排查
赶快去看了下监控系统上面内存和线程的一些监控指标
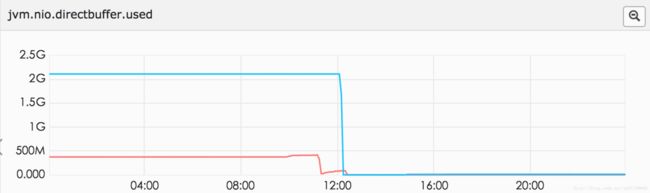
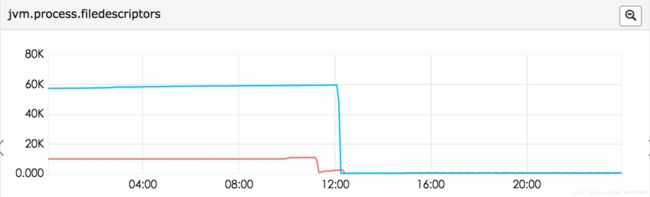

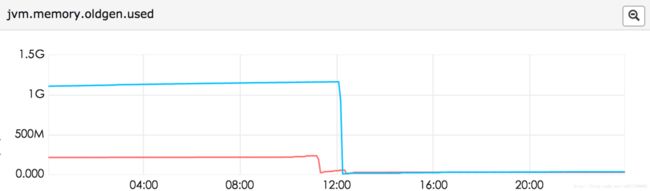

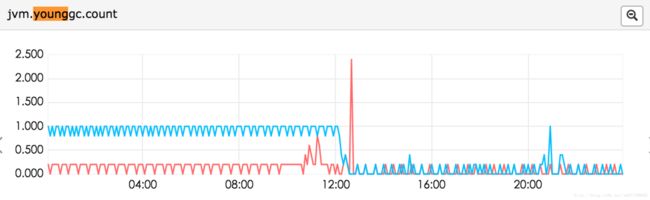
文件描述符、runable线程数 、directbuffer 已经达到了2G(我们-Xmx的值),老年代已经1G多了。但是没有fullGC。youngc次数也不是很多,但是出现问题的机器young gc明显比没出现问题的机器多
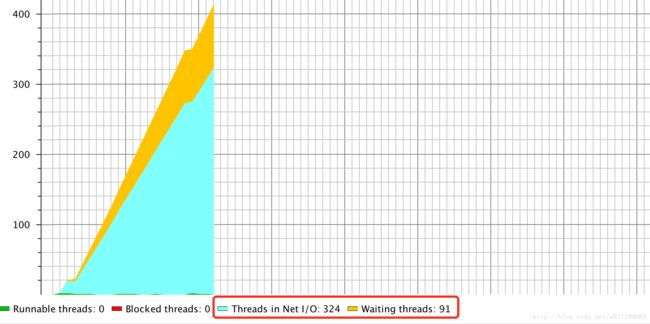
根据上面的指标,初步定位是由线程创建的网络连接造成了native memory不够 。最上面的log日志显示除了jetty之外还有一个就是ElasticSearch client的worker线程也出现的分配OOM。回想上次开发新功能的时候,会创建大量的ES client连接,会不会是这个问题。查看代码发现确实是因为创建了大量的ES连接,但是并没有主动close掉。导致线程数暴增,由于ElasticSearch client是用的netty做的网络层,使用了大量的DirectByteBuffer.引用一直存在(client线程一直存在),无法GC掉,DirectByteBuffer对象,导致native memory也无法回收。下图是用jprofile测试ElasticSearch client的时候发现的。可以得到的是ElasticSearch client确实会产生大量的DirectByteBuffer

old gen为什么会多呢?
那为什么old gen的对象这么多呢?其实就是一大堆的bytebuffer冰山对象进入了oldgen ,然而fullgc都没有发生,bytebuffer不会被回收,但是这个时候native memory已经被分配完了,所以OOM了。查了资料发现我们在JVM参数中添加了这个:-XX:+DisableExplicitGC.这个参数会导致显示调用System.gc()无效。然而在分配native memory中有这样一段代码:
// These methods should be called whenever direct memory is allocated or
// freed. They allow the user to control the amount of direct memory
// which a process may access. All sizes are specified in bytes.
static void reserveMemory(long size, int cap) {
synchronized (Bits.class) {
if (!memoryLimitSet && VM.isBooted()) {
maxMemory = VM.maxDirectMemory();
memoryLimitSet = true;
}
// -XX:MaxDirectMemorySize limits the total capacity rather than the
// actual memory usage, which will differ when buffers are page
// aligned.
if (cap <= maxMemory - totalCapacity) {
reservedMemory += size;
totalCapacity += cap;
count++;
return;
}
}
//提醒jvm该gc了,回收下死掉的对象
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException x) {
// Restore interrupt status
Thread.currentThread().interrupt();
}
synchronized (Bits.class) {
//计算可分配的是否已经超过maxMemeory,超过则抛出OOM异常
if (totalCapacity + cap > maxMemory)
throw new OutOfMemoryError("Direct buffer memory");
reservedMemory += size;
totalCapacity += cap;
count++;
}
}通过这段代码发现,每次分配native memory的时候会通知jvm进行一次GC。如果我们配置了上面的jvm参数会导致这行代码不起任何作用。old gen里面的对象就算死掉也不会回收,除非old gen本身满了,但是通过上面的old gen使用了1G,还没有到old gen的最大值。没有full gc所以native memory一直没有被回收。其实就算我们没有设置jvm参数估计也会OOM ,因为bytebuffer因为线程只有的关系不会全部死掉。大部分bytebuffer也不会被回收
关于DirectByteBuffer

- Perm中主要放一些class和meta信息,常量池,静态字段等。这些东西都放在所谓的方法区中,在hotspot中也就是“持久带”。
- 对于习惯在HotSpot虚拟机上开发和部署程序的开发者来说,很多人愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已
- 用-Xmx -Xms -Xmn 指定堆的最大值、初始值、和年轻带的大小,由上图可知young区也分为Eden 、from 、to上个区,比例默认是8:1:1 可以用-XX:SurvivorRatio设置年轻代中Eden区与Survivor区的大小比值
- 堆内内存由JVM gc统一管理回收,关于垃圾回收算法,这里不再赘述
堆外内存(off-heap memory)
和堆内内存相对应,堆外内存就是把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。堆外内存默认是和-Xmx默认一样大,也可以使用-XX:MaxDirectMemorySize指定堆外内存大小
作为JAVA开发者我们经常用java.nio.DirectByteBuffer对象进行堆外内存的管理和使用,它会在对象创建的时候就分配堆外内存。DirectByteBuffer类是在Java Heap外分配内存,对堆外内存的申请主要是通过成员变量unsafe来操作。关于Cleaner回收native memory又是另一个重要的点了。比如:为什么不用finalize来回收native memory。另外找机会写.
我们可以知道的是,随着DirectByteBuffer被GC掉之后,被分配的native memory会被回收
DirectByteBuffer(int cap) {
super(-1, 0, cap, cap);
//内存是否按页分配对齐
boolean pa = VM.isDirectMemoryPageAligned();
//获取每页内存大小
int ps = Bits.pageSize();
//分配内存的大小,如果是按页对齐方式,需要再加一页内存的容量
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//用Bits类保存总分配内存(按页分配)的大小和实际内存的大小
Bits.reserveMemory(size, cap);
long base = 0;
try {
//在堆外内存的基地址,指定内存大小
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
//计算堆外内存的基地址
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
//当this对象即directByteBuffer被gc回收时,释放native memory(为什么不用)
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
private static class Deallocator implements Runnable {
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
//回收native memory
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
}堆外内存溢出
我们知道了回收堆内的DriectByteBuffer就会回收native memory,出现OOM的情况就是native memory被分配完了。也同时因为这个原因,假设进入Old gen的对象本来已经死了,但是并没有full gc回收,native memory不能被及时回收。为了避免这种情况,在分配DirectByteByffer的时候会主动调用一次System.GC().通知JVM进行一次full gc。定期清理堆中的垃圾,及时的释放native memory。
但是用了-XX:+DisableExplicitGC参数后,System.gc()的调用就会变成一个空调用,完全不会触发任何GC(但是“函数调用”本身的开销还是存在的).为啥要用这个参数呢?最主要的原因是为了防止某些手贱的同学在代码里到处写System.gc()的调用而STW干扰了程序的正常运行吧。有些应用程序本来可能正常跑一天也不会出一次full GC,但就是因为有人在代码里调用了System.gc()而不得不间歇性被暂停。也有些时候这些调用是在某些库或框架里写的,改不了它们的代码但又不想被这些调用干扰也会用这参数。
但是如果使用堆外内存,同时使用了这个参数,比如同时满足下面3个条件,就很容易发生OOM
- 应用本身在GC堆内的对象行为良好,正常情况下很久都不发生full GC;
- 应用大量使用了NIO的direct memory,经常、反复的申请DirectByteBuffer
- 使用了-XX:+DisableExplicitGC
下面使用一些实例在看看在使用了DisableExplicitGC这个参数之后,到底会发生什么。
第一种:
native memory满了,但是young区没满,没有发生young gc回收DirectByteBuffer,所以堆外OOM(如果去掉DisableExplicitGC参数程序会一直有Full GC的信息输出,因为分配native memory的时候会主动调用System.GC())
-Xmx64m
-Xms64m
-Xmn32m
-XX:+UseConcMarkSweepGC
-XX:+PrintGCDetails
-XX:+DisableExplicitGC//限制GC限制调用
-XX:MaxDirectMemorySize=10M//堆外10M
int i =1;
while(true){
System.out.println("第"+(i++)+"次");
ByteBuffer byteBuffer = ByteBuffer.allocateDirect( 1024*1024);
}
//输出
第10次
第11次//10M就分配满了,分配第11次的时候会OOM
Heap
par new generation total 29504K, used 3149K [0x00000007f6e00000, 0x00000007f8e00000, 0x00000007f8e00000)
eden space 26240K, 12% used [0x00000007f6e00000, 0x00000007f7113578, 0x00000007f87a0000)//eden区只用了12%
from space 3264K, 0% used [0x00000007f87a0000, 0x00000007f87a0000, 0x00000007f8ad0000)
to space 3264K, 0% used [0x00000007f8ad0000, 0x00000007f8ad0000, 0x00000007f8e00000)
concurrent mark-sweep generation total 32768K, used 0K [0x00000007
Exception in thread "main" java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:658)
at java.nio.DirectByteBuffer.(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:306)
第二种:
native memory没满,但是young区在native memory满之前提前满了,发生young gc回收DirectByteBuffer,不会发生OOM
如果代码换成了下面这种(jvm参数一样),一次分配的native memory足够小,会导致在native memory没有分配满的情况下,发生young gc会搜DirectByteBuffer。同时会回收native memory
ByteBuffer byteBuffer = ByteBuffer.allocateDirect( 1024/2/2/2/2/2);
//输出会有
[GC[ParNew: 29503K->3262K(29504K), 0.0369960 secs] 44757K->25060K(62272K), 0.0370220 secs] [Times: user=0.18 sys=0.00, real=0.04 secs]
...
...
Heap
//退出程序时会发现young区并没有满
par new generation total 29504K, used 12716K [0x00000007f6e00000, 0x00000007f8e00000, 0x00000007f8e00000)
eden space 26240K, 36% used
[0x00000007f6e00000, 0x00000007f773b530, 0x00000007f87a0000)
from space 3264K, 99% used [0x00000007f8ad0000, 0x00000007f8dffbc0, 0x00000007f8e00000)
to space 3264K, 0% used
第三种
大量DirectByteBuffer对象移动到old gen。没有Full gc的发生,导致在程序中可能死掉的DirectByteBuffer对象没有回收掉,native memory则满了,发生OOM
-Xmx64m
-Xms64m
-Xmn32m
-XX:+PrintGCDetails
-XX:MaxTenuringThreshold=1//设置进去old gen的寿命是1,默认是15次才进入old gen
-XX:MaxDirectMemorySize=10M
-XX:+DisableExplicitGC//不能显示full gc
int i = 1;
List list = new ArrayList();
while (true) {
System.out.println("第" + (i++) + "次");
ByteBuffer.allocate(1024 * 1024);//分配堆内内存
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(1024 / 2 / 2 / 2 );
list.add(byteBuffer);//保证引用不被younggc
}
//输出
[GC[ParNew: 25620K->6K(29504K), 0.0004310 secs] 38176K->12564K(62272K), 0.0004450 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//中途有一些young gc
//.....
//最终输出
Heap
//young 区也没有满
PSYoungGen total 32256K, used 26419K [0x000000010d700000, 0x000000010f700000, 0x000000010f700000)
eden space 31744K, 82% used [0x000000010d700000,0x000000010f0a4c70,0x000000010f600000)
from space 512K, 31% used [0x000000010f680000,0x000000010f6a8000,0x000000010f700000)
to space 512K, 0% used [0x000000010f600000,0x000000010f600000,0x000000010f680000)
//old gen 已经用了62%了
ParOldGen total 32768K, used 20586K [0x000000010b700000, 0x000000010d700000, 0x000000010d700000)
object space 32768K, 62% used [0x000000010b700000,0x000000010cb1a908,0x000000010d700000)
PSPermGen total 21504K, used 3097K [0x0000000106500000, 0x0000000107a00000, 0x000000010b700000)
object space 21504K, 14% used [0x0000000106500000,0x00000001068065e8,0x0000000107a00000)
如果你在使用Oracle/Sun JDK 6,应用里有任何地方用了direct memory,那么使用-XX:+DisableExplicitGC要小心。如果用了该参数而且遇到direct memory的OOM,可以尝试去掉该参数看是否能避开这种OOM
先写到这里,关于DirectByteBuffer的Cleaner方式如何回收Native memory方面,以后在添加(微笑)
参考资料:
- http://hllvm.group.iteye.com/group/topic/27945%EF%BC%89%E3%80%82
- http://blog.sina.com.cn/s/blog_6940cab30101ghgj.html
https://ymgd.github.io/codereader/2016/10/17/%E4%BB%8E0%E5%88%B01%E8%B5%B7%E6%AD%A5-%E8%B7%9F%E6%88%91%E8%BF%9B%E5%85%A5%E5%A0%86%E5%A4%96%E5%86%85%E5%AD%98%E7%9A%84%E5%A5%87%E5%A6%99%E4%B8%96%E7%95%8C/ - http://huangyunbin.iteye.com/blog/1848394
- http://www.blogjava.net/fancydeepin/archive/2013/09/29/jvm_heep.html