ML笔记:k-means聚类算法讲解+手写python实现+调用sklearn实现!
| k-means聚类算法讲解+手写python实现+调用sklearn实现! |
文章目录
- 一、聚类算法
- 二、k-means聚类算法
- 2.1、处理过程
- 2.2、简单举例
- 三、python手写实现k-means算法
- 3.1、算法的伪代码
- 3.2、导入鸢尾花数据集
- 3.3、构建欧式距离计算函数
- 3.4、编写自动生成随机质心的函数
- 3.5、编写完整的k-means聚类函数
- 3.6、最终代码进行测试
- 四、k-means算法验证
- 4.1、数据集处理
- 4.2、最终代码
- 4.3、聚类结果
- 五、聚类算法评估指标
- 5.1、误差平方和(SSE)计算
- 5.2、误差平方和(SSE)的局限
- 5.3、模型收敛稳定性探讨
- 六、sklearn库实现k-means聚类-应用1
- 6.1、问题描述
- 6.2、实验代码
- 文章参考
一、聚类算法
对于"监督学习"(supervised learning),其训练样本是带有标记信息的,并且监督学习的目的是:对带有标记的数据集进行模型学习,从而便于对新的样本进行分类。而在“无监督学习”(unsupervised learning)中,训练样本的标记信息是未知的,目标是通过对无标记训练样本的学习来揭示数据的内在性质及规律,为进一步的数据分析提供基础。对于无监督学习,应用最广的便是"聚类"(clustering)。
“聚类算法”试图将数据集中的样本划分为若干个通常是不相交的子集,每个子集称为一个“簇”(cluster),通过这样的划分,每个簇可能对应于一些潜在的概念或类别。
二、k-means聚类算法
2.1、处理过程
k-means聚类算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。
其处理过程如下:
- 随机选择k个点作为初始的聚类中心;
- 对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇;
- 对于每个簇,计算所有点的均值最为新的聚类中心(质心);
- 重复2、3步骤知道聚类中心不再发生改变;
2.2、简单举例

三、python手写实现k-means算法
3.1、算法的伪代码
创建k个点作为起始质心 (经常是随机选择)
当任意一个点的簇分配结果发生改变的时
对数据集中的每个样本点:
对每个质心:
计算质心与样本点之间的距离
将样本点分配到与其距离最近的簇
对每一个簇,计算簇中所有样本点的均值并将均值作为质心
直到簇不再发生变化或者达到最大迭代次数
3.2、导入鸢尾花数据集
此处先以经典的鸢尾花数据集为例,来进行建模,数据存放在one.txt中;下载链接: 提取码:04qd
# 导入包
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
# 加载数据集
iris = pd.read_csv('one.txt', header=None) # 数据集用逗号分隔,直接用CSV导入,
print(iris.head()) # 返回前5行,4列特征加1列标签
print(iris.shape)
运行结果:
C:\Anaconda3\envs\tf2\python.exe E:/Codes/MyCodes/TF1/svm_test/kmeans.py
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
(150, 5)
Process finished with exit code 0
3.3、构建欧式距离计算函数
我们需要定义一个两个长度相等的数组之间欧式距离计算函数,在不直接应用距离计算结果,只比较距离远近的情况下,我们可以用平方和代替距离进行比较,化简开平方运算,从而减少计算量。
另外需要说明的是,涉及到距离计算的,一定要注意量纲的统一。如果不统一的话,模型极易偏向量纲大的那一方,此处选用鸢尾花数据集,基本不需要考虑量纲的问题。
# 计算欧式距离平方
def distEclu(arrA, arrB):
dist = np.sum(arrA-arrB, axis=1)
return dist
3.4、编写自动生成随机质心的函数
在定义随机质心生成函数时,首先需要计算每列数值的范围,然后从该范围中随机生成指定个数的质心。此处使用numpy.random.uniform()函数生成随机质心。首先测试一下这个函数;

import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
# 计算欧式距离平方
def distEclu(arrA, arrB):
"""
函数功能:计算两个数据集之间的欧式距离
输入:两个array数据集
返回:两个数据集之间的欧式距离(此处用距离平方和代替距离)
"""
dist = np.sum(arrA-arrB, axis=1)
return dist
# 随机生成质心
def randCent(dataset, k):
"""
函数功能:随机生成k个质心
参数说明:
dataset: 包含标签的数据集
k : 簇的个数
返回:
data_cent: k个质心
"""
n = dataset.shape[1] # 特征有多少列
data_min = dataset.iloc[:, :n-1].min() # 每一列的最小值;这个列不包含标签的为:n-1
data_max = dataset.iloc[:, :n-1].max() # 每一列的最大值
data_cent = np.random.uniform(data_min, data_max, (k, n-1)) # 参数:最小值,最大值,shape形状。
return data_cent
if __name__ == '__main__':
# 导入数据集
iris = pd.read_csv('one.txt', header=None) # 数据集用逗号分隔,直接用CSV导入,
print(iris.head()) # 返回前5行,4列特征加1列标签
print(iris.shape)
iris_cent = randCent(iris, 3) # 简单测试一下,随机生成质心
print(iris_cent)
运行结果: 我们知道鸢尾花有3种,就是3个类,这个我们这里设置3个簇好了,下面随机生成了3个质心。
C:\Anaconda3\envs\tf2\python.exe E:/Codes/MyCodes/TF1/svm_test/kmeans.py
0 1 2 3 4
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
(150, 5)
[[5.75705224 2.97777172 4.53823141 1.51209317]
[6.93696032 2.5715126 3.98805229 2.01570094]
[6.61900612 3.55158816 2.65495576 1.06736773]]
Process finished with exit code 0
3.5、编写完整的k-means聚类函数
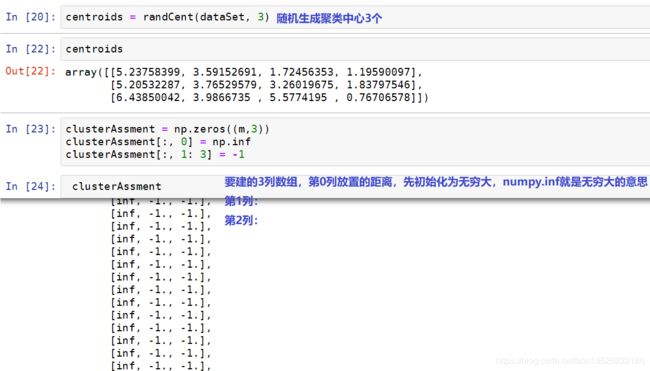
在执行k-means的时候,需要不断的迭代质心(聚类中心),因此我们需要2个迭代容器完成该目标:
第一个容器: 用于存放和更新质心,该容器可考虑使用list来执行,list不仅是可迭代对象,同时list内不同元素索引也可以用于标记和区分各质心,即各簇的编号。
第二个容器: 则需要记录、保存和更新各个样本点到质心之间的距离,并能够方便对其进行比较,该容器考虑使用一个三列的数组来执行。其中第一个用于存放最近一次计算完成后某点到质心的最短距离。第二个用于记录最近一次计算完成后根据最短距离得到的代表对应质心的数值索引,即所属簇,就是质心的编号。第三个用于存放上一次某点所对应质心编号(某点所属簇),后两列用于比较质心发生变化后某点所属簇的情况是否发生变化。
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
1. 下面的代码3列数组形象展示:
2. 下面的拼接这里形象展示:
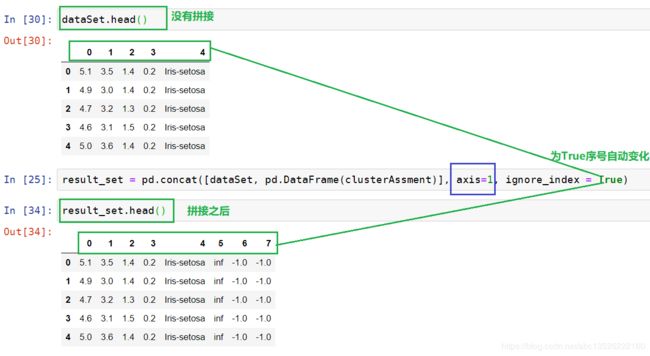
3. 我们自己建的是array,需要转换为DataFrame, DataFrame是Python中Pandas库中的一种数据结构,它类似excel,是一种二维表。

5. 第一个样本到3个质心的距离:

6. np.where以及提取当前质心位置放到n+1列中:
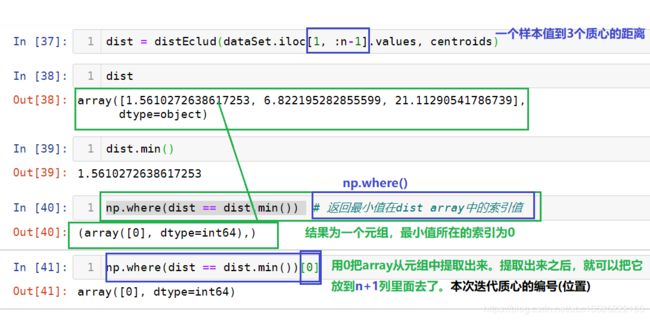
注意: 补充
numpy.where()用法详解:numpy.where() 用法详解
1、np.where(condition, x, y),满足条件(condition),输出x,不满足输出y。
2、np.where(condition),只有条件 (condition),没有x和y,则输出满足条件 (即非0) 元素的坐标 (等价于numpy.nonzero)。这里的坐标以tuple的形式给出,通常原数组有多少维,输出的tuple中就包含几个数组,分别对应符合条件元素的各维坐标。
7. a==b 和 (a == b).all(),(a == b).any()方法对比

++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
# 完整的k-means聚类函数
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
"""
函数功能:完整的k-means聚类函数
:param dataSet: 数据集包含有标签
:param k: 我们自己规定的簇的个数
:param distMeas: 上面建好的距离计算函数
:param createCent: 上面建好的随机生成质心的函数
:return:
"""
m,n = dataSet.shape # 找出数据集多少行,多少列.
centroids = createCent(dataSet, k) # 随机生成我们的质心
clusterAssment = np.zeros((m,3)) # 先用numpy.zeros生成m行,3列的数组。这里为150*3
clusterAssment[:, 0] = np.inf # 先看第0列,放置的距离,先初始化为无穷大,numpy.inf就是无穷大的意思
clusterAssment[:, 1: 3] = -1 # 第1列放置本次迭代簇的编号,第2列放置上一次迭代簇的编号.先初始化为-1
# 把原来的dataSet和3列数组给concat起来,
result_set = pd.concat([dataSet, pd.DataFrame(clusterAssment)], axis=1, ignore_index = True)
# result_set好之后,我们就可以更新我们的result_set了。需要迭代更新质心,计算距离.
clusterChanged = True
while clusterChanged: # 使用while循环,先假设条件为True,进入循环之后立马变为False
clusterChanged = False
for i in range(m): # 遍历数据集中的每一个样本点,计算每个样本点和质心之间的距离.除了标签那一列。
dist = distMeas(dataSet.iloc[i, :n-1].values, centroids) # iloc是根据行号来索引,行号从0开始,逐次加1。
result_set.iloc[i, n] = dist.min() # 拼接后,这一列就是我们放最短距离的这一列,上面图中可以看
result_set.iloc[i, n+1] = np.where(dist == dist.min())[0]
# 最后1列(上次迭代结果)是不是和倒数第2列(本次)相等,如果全都是相等的才返回True.这里用not取反,假设全都相等,取反为False,不满足循环,迭代结束。
clusterChanged = not (result_set.iloc[:, -1] == result_set.iloc[:, -2]).all()
if clusterChanged: # 如果True执行下面这个方法
cent_df = result_set.groupby(n+1).mean() # n+1是本次迭代簇的编号,groupby之后取一个mean作为质心
centroids = cent_df.iloc[:,:n-1].values # 更新质心
result_set.iloc[:, -1] = result_set.iloc[:, -2] # 本次迭代的变为上次迭代的那一列
return centroids, result_set
3.6、最终代码进行测试
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
# 计算欧式距离平方
def distEclud(arrA, arrB):
"""
函数功能:计算两个数据集之间的欧式距离
输入:两个array数据集
:param arrA:
:param arrB:
:return: 两个数据集之间的欧式距离(此处用距离平方和代替距离)
"""
d = arrA - arrB
dist = np.sum(np.power(d, 2), axis=1)
return dist
# 随机生成质心
def randCent(dataSet, k):
"""
函数功能:随机生成k个质心
:param dataset: 包含标签的数据集
:param k: 我们自己规定的簇的个数
:return: k个质心
"""
n = dataSet.shape[1] # 特征有多少列
data_min = dataSet.iloc[:, :n-1].min() # 每一列的最小值;这个列不包含标签的为:n-1
data_max = dataSet.iloc[:, :n-1].max() # 每一列的最大值
data_cent = np.random.uniform(data_min, data_max, (k, n-1)) # 参数:最小值,最大值,shape形状。
return data_cent
# 完整的k-means聚类函数
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
"""
函数功能:完整的k-means聚类函数
:param dataSet: 数据集包含有标签
:param k: 我们自己规定的簇的个数
:param distMeas: 上面建好的距离计算函数
:param createCent: 上面建好的随机生成质心的函数
:return:
"""
m,n = dataSet.shape # 找出数据集多少行,多少列.
centroids = createCent(dataSet, k) # 随机生成我们的质心
clusterAssment = np.zeros((m,3)) # 先用numpy.zeros生成m行,3列的数组。这里为150*3
clusterAssment[:, 0] = np.inf # 先看第0列,放置的距离,先初始化为无穷大,numpy.inf就是无穷大的意思
clusterAssment[:, 1: 3] = -1 # 第1列放置本次迭代簇的编号,第2列放置上一次迭代簇的编号.先初始化为-1
# 把原来的dataSet和3列数组给concat起来,
result_set = pd.concat([dataSet, pd.DataFrame(clusterAssment)], axis=1, ignore_index = True)
# result_set好之后,我们就可以更新我们的result_set了。需要迭代更新质心,计算距离.
clusterChanged = True
while clusterChanged: # 使用while循环,先假设条件为True,进入循环之后立马变为False
clusterChanged = False
for i in range(m): # 遍历数据集中的每一个样本点,计算每个样本点和质心之间的距离.除了标签那一列。
dist = distMeas(dataSet.iloc[i, :n-1].values, centroids) # iloc是根据行号来索引,行号从0开始,逐次加1。
result_set.iloc[i, n] = dist.min() # 拼接后,这一列就是我们放最短距离的这一列,上面图中可以看
result_set.iloc[i, n+1] = np.where(dist == dist.min())[0]
# 最后1列(上次迭代结果)是不是和倒数第2列(本次)相等,如果全都是相等的才返回True.这里用not取反,假设全都相等,取反为False,不满足循环,迭代结束。
clusterChanged = not (result_set.iloc[:, -1] == result_set.iloc[:, -2]).all()
if clusterChanged: # 如果True执行下面这个方法
cent_df = result_set.groupby(n+1).mean() # n+1是本次迭代簇的编号,groupby之后取一个mean作为质心
centroids = cent_df.iloc[:,:n-1].values # 更新质心
result_set.iloc[:, -1] = result_set.iloc[:, -2] # 本次迭代的变为上次迭代的那一列
return centroids, result_set
if __name__ == '__main__':
# 导入数据集
iris = pd.read_csv('one.txt', header=None) # 数据集用逗号分隔,直接用CSV导入,
# print(iris.head()) # 返回前5行,4列特征加1列标签
# print(iris.shape)
# iris_cent = randCent(iris, 3) # 简单测试一下,随机生成质心
# print(iris_cent)
iris_cent, iris_result = kMeans(iris, 3)
print(iris_cent)
# print(iris_result)
print(iris_result.iloc[:, -1].value_counts())
运行结果:
C:\Anaconda3\envs\tf2\python.exe E:/Codes/MyCodes/TF1/svm_test/kmeans.py
[[6.85 3.07368421 5.74210526 2.07105263]
[5.9016129 2.7483871 4.39354839 1.43387097]
[5.006 3.418 1.464 0.244 ]]
1.0 62
2.0 50
0.0 38
Name: 7, dtype: int64
Process finished with exit code 0
注意一下几点:

四、k-means算法验证
4.1、数据集处理
下面我们对k-means算法进行验证一下,因为我们使用的是鸢尾花数据集,因为鸢尾花每个样本数据有4个特征,我们没有办法直接进行可视化帮助我们理解。下面我们用testSet.txt数据集帮助我们做可视化理解!下载链接: 提取码:04qd
数据是以空格分割的,所以我们可以直接用pd.read_table方法,部分如下:

数据只有2列
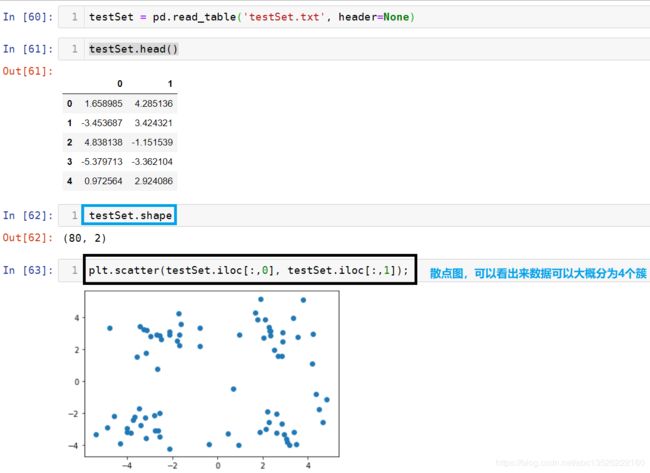
大家注意前面鸢尾花数据集是带有标签的,这里为了表示一致,我们也给它加了一列全为0的值。
进行concat之前变成DateFrame的形式;pd.concat() 主要是沿着一条轴(axis=0 或1)将多个对象堆叠在一起;

调用kmeans函数
4.2、最终代码
最终代码如下:
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
# 计算欧式距离平方
def distEclud(arrA, arrB):
"""
函数功能:计算两个数据集之间的欧式距离
输入:两个array数据集
:param arrA:
:param arrB:
:return: 两个数据集之间的欧式距离(此处用距离平方和代替距离)
"""
d = arrA - arrB
dist = np.sum(np.power(d, 2), axis=1)
return dist
# 随机生成质心
def randCent(dataSet, k):
"""
函数功能:随机生成k个质心
:param dataset: 包含标签的数据集
:param k: 我们自己规定的簇的个数
:return: k个质心
"""
n = dataSet.shape[1] # 特征有多少列
data_min = dataSet.iloc[:, :n-1].min() # 每一列的最小值;这个列不包含标签的为:n-1
data_max = dataSet.iloc[:, :n-1].max() # 每一列的最大值
data_cent = np.random.uniform(data_min, data_max, (k, n-1)) # 参数:最小值,最大值,shape形状。
return data_cent
# 完整的k-means聚类函数
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
"""
函数功能:完整的k-means聚类函数
:param dataSet: 数据集包含有标签
:param k: 我们自己规定的簇的个数
:param distMeas: 上面建好的距离计算函数
:param createCent: 上面建好的随机生成质心的函数
:return:
"""
m,n = dataSet.shape # 找出数据集多少行,多少列.
centroids = createCent(dataSet, k) # 随机生成我们的质心
clusterAssment = np.zeros((m,3)) # 先用numpy.zeros生成m行,3列的数组。这里为150*3
clusterAssment[:, 0] = np.inf # 先看第0列,放置的距离,先初始化为无穷大,numpy.inf就是无穷大的意思
clusterAssment[:, 1: 3] = -1 # 第1列放置本次迭代簇的编号,第2列放置上一次迭代簇的编号.先初始化为-1
# 把原来的dataSet和3列数组给concat起来,
result_set = pd.concat([dataSet, pd.DataFrame(clusterAssment)], axis=1, ignore_index = True)
# result_set好之后,我们就可以更新我们的result_set了。需要迭代更新质心,计算距离.
clusterChanged = True
while clusterChanged: # 使用while循环,先假设条件为True,进入循环之后立马变为False
clusterChanged = False
for i in range(m): # 遍历数据集中的每一个样本点,计算每个样本点和质心之间的距离.除了标签那一列。
dist = distMeas(dataSet.iloc[i, :n-1].values, centroids) # iloc是根据行号来索引,行号从0开始,逐次加1。
result_set.iloc[i, n] = dist.min() # 拼接后,这一列就是我们放最短距离的这一列,上面图中可以看
result_set.iloc[i, n+1] = np.where(dist == dist.min())[0]
# 最后1列(上次迭代结果)是不是和倒数第2列(本次)相等,如果全都是相等的才返回True.这里用not取反,假设全都相等,取反为False,不满足循环,迭代结束。
clusterChanged = not (result_set.iloc[:, -1] == result_set.iloc[:, -2]).all()
if clusterChanged: # 如果True执行下面这个方法
cent_df = result_set.groupby(n+1).mean() # n+1是本次迭代簇的编号,groupby之后取一个mean作为质心
centroids = cent_df.iloc[:,:n-1].values # 更新质心
result_set.iloc[:, -1] = result_set.iloc[:, -2] # 本次迭代的变为上次迭代的那一列
return centroids, result_set
if __name__ == '__main__':
# 导入数据集
testSet = pd.read_table('testSet.txt', header=None) # 数据集用空格分隔,直接用CSV导入,
print(testSet.head())
print(testSet.shape)
ze = pd.DataFrame(np.zeros(testSet.shape[0]).reshape(-1, 1)) # 进行concat之前变成DateFrame的形式
test_set = pd.concat([testSet, ze], axis=1, ignore_index=True) # 沿着一条轴(axis=0 或1)将多个对象堆叠在一起
test_set.head()
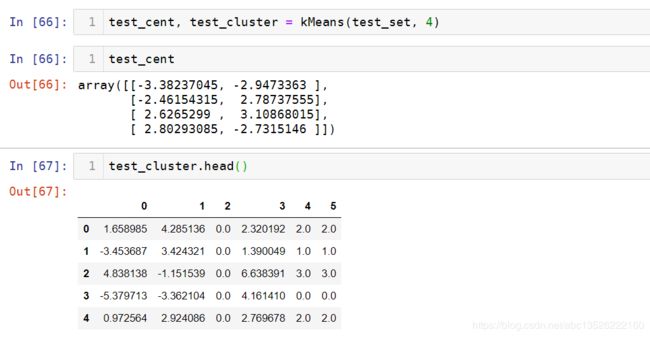
test_cent, test_cluster = kMeans(test_set, 4)
print(test_cent)
# plt.scatter(testSet.iloc[:,0], testSet.iloc[:, 1])
# plt.show()
plt.scatter(test_cluster.iloc[:,0], test_cluster.iloc[:,1], c=test_cluster.iloc[:, -2]) # 颜色的区分
plt.scatter(test_cent[:, 0], test_cent[:, 1], color='red',marker='+',s=80); # 画出质心, s定义的大小
plt.show()
4.3、聚类结果
运行结果如下:

五、聚类算法评估指标
5.1、误差平方和(SSE)计算
误差平方和(SSE)是聚类算法模型最重要的评估指标,下面,在手动编写的k-means快速聚类函数基础上,我们计算结果集合中的误差平方和。在k-means函数生成的结果result_set中,第n列,也就是我们定义的clusterAssment容器中的第一列就保留了最近一次分类结果的某点到对应所属簇质心的距离平方和,因此我们只需要对result_set中的第n列进行简单求和汇总,即可得到聚类模型误差平方和。
print(test_cluster.iloc[:, 3].sum()) # 结果为:149.95430467642635
iris_result.iloc[:, 5].sum() # 结果为:78.94506582597731
5.2、误差平方和(SSE)的局限

因此,模型误差平方和没有绝对的意义,比较不同的数据集聚类结果的误差平常和没有任何意义,误差平方和在聚类算法分析中主要有以下两点作用:

接下来,尝试绘制聚类分类数量的学习曲线,这里任然考虑自定义一个函数来进行绘制,此处需要注意,质心数量选取建议从2开始,质心为1的时候SSE数值较大,对后续曲线显示效果有较大影响。
# 聚类学习曲线
def kclearningCurve(dataSet, cluster = kMeans, k=10):
"""
函数功能:聚类学习曲线
:param dataSet: 原始数据集
:param cluster: kmeans聚类方法
:param k: 簇的个数
:return: 误差平方和SSE
"""
n = dataSet.shape[1] # n列
SSE = []
for i in range (1, k):
centroids, result_set = cluster(dataSet, i+1)
SSE.append(result_set.iloc[:, n].sum())
print(SSE)
plt.plot(range(2, k+1), SSE, '--o')
plt.show()
return SSE
然后在已有数据集上进行测试
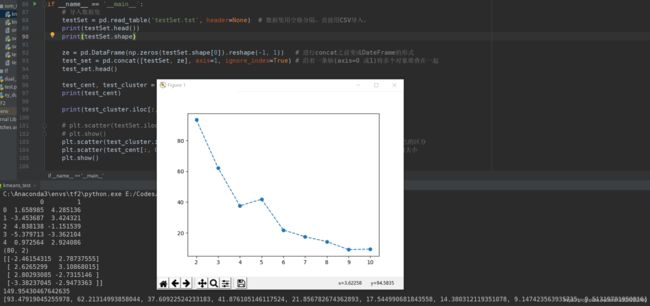
kclearningCurve(testSet)
测试结果: 分析从运行结果2次看出,学习曲线很不稳定,但是基本上在3和4之间,从图中可以看出来4处有一个拐点,拐点一个情况,这里就是最佳k的取值,此时SSE相对比较小,簇的个数也不是很多,相对比较好的取值。
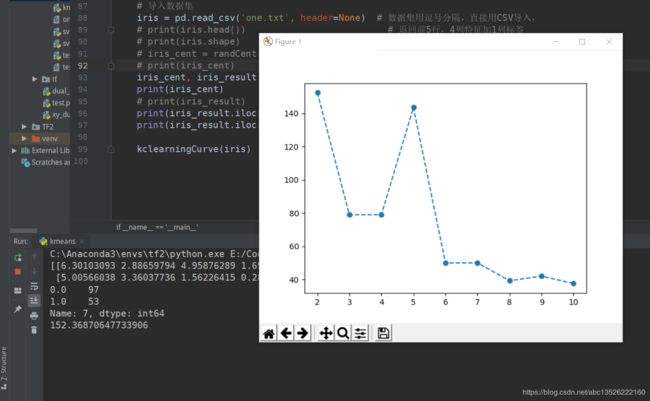
kclearningCurve(iris)

5.3、模型收敛稳定性探讨
在执行前面聚类算法的过程中,好像虽然初始质心的随机生成的,但最终分类结果均保持一致。若初始化参数是随机设置(如此处初始质心位置是随机生成的),但最终模型在多次迭代之后稳定输出结果,则可认为最终模型收敛,所谓迭代是指上次运算结果作为下一次运算的条件参与运算,kmeans的每次循环本质上都是迭代,我们利用上次生成的中心点参与到下次距离计算中。
同时前面编写的kmeans聚类算法中我们设置的收敛条件比较简单,就是最近2次迭代各点归属簇的划分结果,若不在发生变化,则说明结果收敛,停止迭代。但是实际上这种收敛条件并不稳定,尤其是在我们采用均值作为质心代入计算的过程中,实际上采用了梯度下降作为优化手段,但梯度下降本质是无约束条件下局部最优手段,局部最优手段最终不一定导致全局最优,即我们使用均值作为质心带人迭代,最终依据收敛判别结果计算的最终结果一定是基于初始质心的局部最优结果,但不一定是全局最优的结果,因此其实刚才的结果并不稳定,最终分类和计算的结果会受到初始质心选取的影响。
接下来验证初始质心选取最终如何影响k-means聚类结果的。这里我们可提前设置随机数种子,由于我们的初始质心由np.random类函数生成,所以随机种子也要用np.random类生成:
np.random.seed(123) # 设置在程序的开头吧。
然后执行算法,注意,这里我们每执行一次kmeans函数,初始质心就会随机生成一次,我们需要观察的是重复执行算法过程会不会最终输出不同的分类结果。为了方便更直观的表达,此处仅仅以test_set数据集验证过程为例进行探讨。
1. 验证test_set数据集三分类的结果,同时利用多子图功能进行可视化结果展示
for i in range(1, 5):
plt.subplot(2, 2, i) # 两行一列的图,第三个参数为第几个图
test_cent, test_cluster = kMeans(test_set, 3)
plt.scatter(test_cluster.iloc[:, 0], test_cluster.iloc[:, 1], c=test_cluster.iloc[:, -2]) # 颜色的区分
plt.plot(test_cent[:, 0], test_cent[:, 1], '+', color = 'black')
print(test_cluster.iloc[:, 3].sum())
plt.show()

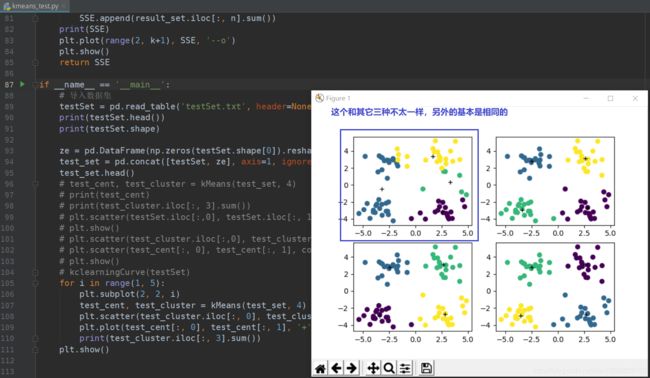
2. 验证test_set数据集4分类的结果,同时利用多子图功能进行可视化结果展示
for i in range(1, 5):
plt.subplot(2, 2, i)
test_cent, test_cluster = kMeans(test_set, 4)
plt.scatter(test_cluster.iloc[:, 0], test_cluster.iloc[:, 1], c=test_cluster.iloc[:, -2]) # 颜色的区分
plt.plot(test_cent[:, 0], test_cent[:, 1], '+', color = 'black')
print(test_cluster.iloc[:, 3].sum())
plt.show()
2. 验证test_set数据集5分类的结果,同时利用多子图功能进行可视化结果展示
for i in range(1, 5):
plt.subplot(2, 2, i)
test_cent, test_cluster = kMeans(test_set, 5)
plt.scatter(test_cluster.iloc[:, 0], test_cluster.iloc[:, 1], c=test_cluster.iloc[:, -2]) # 颜色的区分
plt.plot(test_cent[:, 0], test_cent[:, 1], '+', color = 'black')
print(test_cluster.iloc[:, 3].sum())
plt.show()
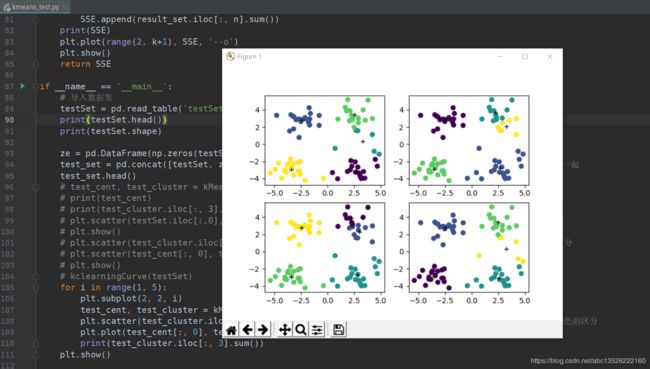
可以继续对iris数据集和更多分类的test_set数据集进行测试,最终能得到如下的结论:
 接下来我们以test_set三分类为例,稍微修改kmeans函数,使其每一步都生成一张点图来查看随机初始化质心是如何一步步最终影响聚类结果的:
接下来我们以test_set三分类为例,稍微修改kmeans函数,使其每一步都生成一张点图来查看随机初始化质心是如何一步步最终影响聚类结果的:
# 完整的k-means聚类函数
def kMeans_1(dataSet, k, distMeas=distEclud, createCent=randCent):
"""
函数功能:完整的k-means聚类函数
:param dataSet: 数据集包含有标签
:param k: 我们自己规定的簇的个数
:param distMeas: 上面建好的距离计算函数
:param createCent: 上面建好的随机生成质心的函数
:return:
"""
m,n = dataSet.shape # 找出数据集多少行,多少列.
centroids = createCent(dataSet, k) # 随机生成我们的质心
clusterAssment = np.zeros((m,3)) # 先用numpy.zeros生成m行,3列的数组。这里为150*3
clusterAssment[:, 0] = np.inf # 先看第0列,放置的距离,先初始化为无穷大,numpy.inf就是无穷大的意思
clusterAssment[:, 1: 3] = -1 # 第1列放置本次迭代簇的编号,第2列放置上一次迭代簇的编号.先初始化为-1
# 把原来的dataSet和3列数组给concat起来,
result_set = pd.concat([dataSet, pd.DataFrame(clusterAssment)], axis=1, ignore_index = True)
# result_set好之后,我们就可以更新我们的result_set了。需要迭代更新质心,计算距离.
clusterChanged = True
while clusterChanged: # 使用while循环,先假设条件为True,进入循环之后立马变为False
clusterChanged = False
for i in range(m): # 遍历数据集中的每一个样本点,计算每个样本点和质心之间的距离.除了标签那一列。
dist = distMeas(dataSet.iloc[i, :n-1].values, centroids) # iloc是根据行号来索引,行号从0开始,逐次加1。
result_set.iloc[i, n] = dist.min() # 拼接后,这一列就是我们放最短距离的这一列,上面图中可以看
result_set.iloc[i, n+1] = np.where(dist == dist.min())[0]
# 最后1列(上次迭代结果)是不是和倒数第2列(本次)相等,如果全都是相等的才返回True.这里用not取反,假设全都相等,取反为False,不满足循环,迭代结束。
clusterChanged = not (result_set.iloc[:, -1] == result_set.iloc[:, -2]).all()
if clusterChanged: # 如果True执行下面这个方法
cent_df = result_set.groupby(n+1).mean() # n+1是本次迭代簇的编号,groupby之后取一个mean作为质心
centroids = cent_df.iloc[:,:n-1].values # 更新质心
result_set.iloc[:, -1] = result_set.iloc[:, -2] # 本次迭代的变为上次迭代的那一列
plt.scatter(result_set.iloc[:, 0], result_set.iloc[:, 1], c=result_set.iloc[:, -1]) # 颜色的区分
plt.plot(centroids[:, 0], centroids[:, 1], '+', color = 'red')
plt.show()

从中可以清楚的看到随机初始质心是如何影响最终聚类分类结果的。解决该问题的方法是尽量降低初始化质心随机性对最后聚类结果造成影响的方案有以下几种:

六、sklearn库实现k-means聚类-应用1
6.1、问题描述
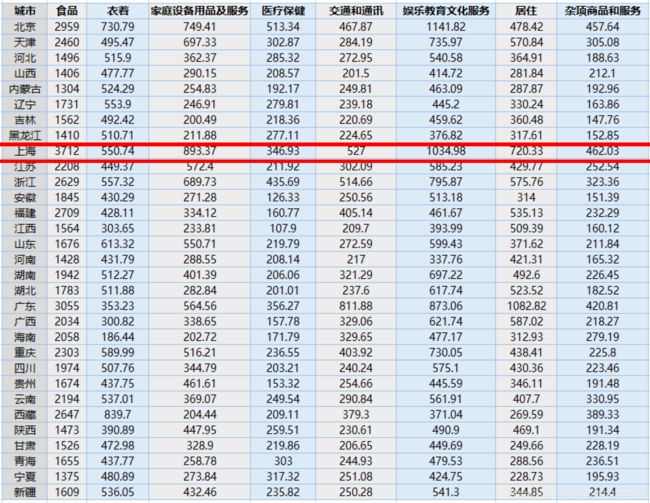
问题描述: 现有1999年全国31个省份城镇居民家庭平均每人全年消费性支出的八个主要变量数据,这八个变量分别是:食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。利用已有数据,对31个省份进行聚类。
实验目的 :通过聚类,了解 1999 年各省份的消费水平在国内的情况。城市按照消费水平 n_clusters类,消消费水平相近的城市归为一类。
数据如下: city.txt;下载链接: 提取码:04qd
6.2、实验代码
# 导入sklearn相关包
import numpy as np
from sklearn.cluster import KMeans
# 加载数据,创建k-means算法实例,并进行训练,获得标签
def loadData(filePath):
fr = open(filePath, 'r+') # r+:读写方式打开一个文本文件
lines = fr.readlines() # .readlines() 一次读取整个文件(类似于.read())
retData = [] # 存储城市的各项消费信息
retCityName = [] # 存储城市名字
for line in lines:
items = line.strip().split(",")
retCityName.append(items[0])
retData.append([float(items[i]) for i in range(1, len(items))])
return retData, retCityName # 返回值返回城市名称,和各项消费信息;
if __name__ == '__main__':
data, cityName = loadData('D:\\city.txt') # 利用loadData方法读取数据
km = KMeans(n_clusters=2) # 创建实例
label = km.fit_predict(data) # 调用k-means() fit_predict()方法进行计算
expenses = np.sum(km.cluster_centers_, axis=1) # 聚类中心点的数值加和,也是平均消费水平
# print(expenses)
CityCluster = [[], [], [], []] # 将城市按label分成设定的簇
for i in range(len(cityName)):
CityCluster[label[i]].append(cityName[i]) # 将每个簇的城市输出
for i in range(len(CityCluster)): # 将每个簇的平均花费进行输出
print("Expenses:%.2f" % expenses[i])
print(CityCluster[i])
- 结果
Expenses:6457.13
['北京', '天津', '上海', '浙江', '福建', '广东', '重庆', '西藏']
Expenses:4040.42
['河北', '山西', '内蒙古', '辽宁', '吉林', '黑龙江', '江苏', '安徽', '江西', '山东', '河南', '湖南', '湖北', '广西', '海南', '四川', '贵州', '云南', '陕西', '甘肃', '青海', '宁夏', '新疆']
Process finished with exit code 1
文章参考
- 关于python中axis=0还是axis=1的讨论
- NumPy、pandas中(axis=0 与axis=1)区分