glove入门实战
前两天怒刷微博,突然发现了刘知远老师分享的微博,顿时眼前一惊,原Po如下:
http://weibo.com/1464484735/BhbLD70wa
由于我目前的研究方向是word2vec,暗自折服于它在word analogy task上狂暴吊炸天的能力,对于glove这样可以击败word2vec的大牛,也必然会产生好奇心。于是便对它做了初步分析,便有了本文,希望可以抛砖引玉,期待更多人对这方面的研究。
由于本人学术水平不够,本文不会涉及glove具体实现的方法,仅仅是介绍如何使用官网代码,并利用python脚本,将glove训练好的model读取,(仿照word2vec)计算任意单词的最相似的TOP N个单词,并利用kmeans对单词进行聚类,用于与word2vec比较结果。
首先,先发出这个paper的homepage:
http://www.socher.org/index.php/Main/GloveGlobalVectorsForWordRepresentation
今天更新发现跳转到如下页面:
http://nlp.stanford.edu/projects/glove/
这里可以找到几个他们用wekipida训练好的model,不过我们一开是不需要关心这个,我们需要关心的是源代码所在的位置,也就是:
http://nlp.stanford.edu/software/glove.tar.gz
下载好glove.tar.gz,基本就可以开始训练了。大家从它的后缀名就应该猜出来,它也是需要在linux下编译运行的程序。各位用windows的,只能参考当初如何用cygwin解决运行word2vec的方法了。(这也不会是本文重点,各位加油!)在linux下解压该文件:
tar -xzvf glove.tar.gz进入glove目录下,首先先参考README.txt,里面主要介绍这个程序包含了四部分子程序,按步骤分别是vocab_count、cooccur、shuffle、glove。本人用拙劣的翻译技巧大概为各位介绍下每部分要做的事情,如果有介绍错误的,还望指出:
1.vocab_count:用于计算原文本的单词统计(生成vocab.txt,每一行为:单词 词频)
2.cooccur:用于统计词与词的共现,目测类似与word2vec的窗口内的任意两个词(生成的是cooccurrence.bin,二进制文件,呵呵)
3. shuffle:对于2中的共现结果重新整理(一看到shuffle瞬间想到hadoop,生成的也是二进制文件cooccurrence.shuf.bin)
4.glove:glove算法的训练模型,会运用到之前生成的相关文件(1&3),最终会输出vectors.txt和vectors.bin(前者直接可以打开,下文主要针对它做研究,后者还是二进制文件)
上面已经介绍了这个程序的执行流程,下面就具体训练出这个vectors.txt。
首先二话不说,直接
make编译程序,如果报错,那只能呵呵了,自己研究下报错原因,多半可能是gcc版本不对,我用的是4.7.3。
如果编译通过了,你要注意的是,其实大牛早就已经给你写好了执行程序,就是demo.sh,你需要做的就是简单的一步:
sh demo.sh如果报错说权限不够,相信各位大牛一定知道如何修改权限,我就是最暴力的:
chmod 777 glove/*我在运行的时候报了:
demo.sh: 26: demo.sh: [[: not found这样的错误,为了解决这个错误,我打开了恐怖的demo.sh,发现它做的任务非常简单。首先它自己一开始就make了(笔者上述的make操作略显多余),接下来去下那个text8(目测和word2vec是同一个东西),接下来定义了一系列常量,然后执行了四步操作,由于笔者对bash的不熟悉,笔者就暴力的把里面的所有的if都干掉了,训练部分代码变成如下这样:
./vocab_count -min-count $VOCAB_MIN_COUNT -verbose $VERBOSE < $CORPUS > $VOCAB_FILE
./cooccur -memory $MEMORY -vocab-file $VOCAB_FILE -verbose $VERBOSE -window-size $WINDOW_SIZE < $CORPUS > $COOCCURRENCE_FILE
./shuffle -memory $MEMORY -verbose $VERBOSE < $COOCCURRENCE_FILE > $COOCCURRENCE_SHUF_FILE
./glove -save-file $SAVE_FILE -threads $NUM_THREADS -input-file $COOCCURRENCE_SHUF_FILE -x-max $X_MAX -iter $MAX_ITER -vector-size $VECTOR_SIZE -binary $BINARY -vocab-file $VOCAB_FILE -verbose $VERBOSE
octave -nodisplay -nodesktop -nojvm -nosplash < ./eval/read_and_evaluate.m 1>&2各位不要笑我,训练出model先。最后执行sh demo.sh,成功生成vectors.txt。(说句题外话,我们可以从glove的参数看得出来,人家也是支持多线程的,在text8语料库训练50维向量,我花了7分钟时间《i5 core+4g内存》,还没有来得及和word2vec对比时间,感觉比word2vec慢)但是还是会报错,具体错误就不显示,主要是因为这个demo.sh接下来调用自己在eval文件夹下写好的matlab代码来分析结果,无奈我Linux下没有安装matlab,我还自做聪明的把matlab修改成octave(见刚刚的第四行),但还是不行,就在这时,我得到张成老师的给力回复:

瞬间发现自己好傻,明明已经生成了vectors.txt,为啥还要用它的matlab代码调用,于是就有了如下的脚本文件:
https://github.com/eclipse-du/glove_py_model_load/blob/master/glove_dist.py
可以看到,我这个脚本函数使用到了两个第三方类库,分别是numpy和sklearn,希望没有装的朋友安装下,具体安装方法在此就不再赘述,有问题的可以和我交流。
这里说个插曲,我打开vectors.txt的时候发现它就是每行用空格分割,为首的是单词,后面接着就是这个单词所对应的向量,为了对比,我又打开了word2vec训练出来的vectors.txt(注意-binary 0)发现二者唯一的区别是,word2vec会在一开始写下单词个数与向量的维度,因此一个邪恶的念头在我脑海中飘过(自己在开头补上单词个数和向量维度),然后就可以被当成是word2vec的bin来被调用。这样可行吗?我一上来遇到个挫折,就是word2vec的原版.distance只支持2进制的model的读入,但我不放弃,总算在python版本的实现(gensim)中发现了load方法,为如下代码:
from gensim.models import Word2Vec
model = Word2Vec.load_word2vec_format(‘vectors.txt’, binary=False)喜欢调用gensim的其他函数的人可以自行玩耍。
说完插曲,可以看看我惨不忍睹的代码,如果不说我的list comprehensive 执行了两次split,也不说我的top k排序是基于全部排序的前K个(按理说K小的时候,用堆排序或者冒泡会更快),更不说我一上来没有进行向量归一化来减少计算时间,在这样的情况下,我觉得我的代码还是基本完成任务了。主要的两个函数分别用来进行余弦计算和找出与当前单词最相近的K个单词。下面又利用sklearn的kmeans对词向量聚类,本人已经用中文文本训练完毕,但由于时间限制,本文还是继续介绍如何在维基的数据进行聚类,我会在以后的博客中介绍如何对中文进行glove学习和聚类(如果还有下文)。
我特地在代码结尾出打印出china和father所对应的类别数(本例中为80和76),进入相对应的类别查看所属类别词。
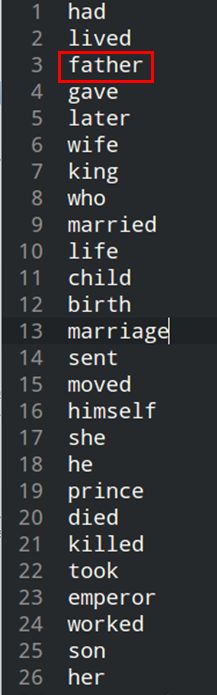

我们可以看出,在china所对应的类别中,包含了很多国家名,比如,germany,ireland, scotland等。在father所对应的第76类中,也包含了许多相关词汇,包括:child,son,wife,king。当然我只是列举几个好的,里面也包含很多杂质,而且很多类别以笔者的词汇是不清楚其具体的聚类含义。不过我们可以用这个100M的文本大体看到glove的初态,也算对得起入门二字。
最后把我训练好的vectors.txt和result文件夹放到github上,供大家查对结果:
https://github.com/eclipse-du/glove_py_model_load
下一步笔者会打算比较word2vec和glove的结果,以及分析glove运用在中文上面的效果,如果你们愿意看的话,去github上点个star(赞),那样会加快我码文章的积极性。(弄到一点多不容易啊~~~)
如果对安装和我的脚本有任何疑问,欢迎及时和我联系。