SparkSQL in中使用子查询耗时高如何优化
目录
一、背景
二、用join替代in
三、用join替换in且map端Join
四、用Join替换in的坑
一、背景
经常遇到MySQL表太大,频繁查询影响性能,需要把MySQL数据同步到hive(通过解析MySQL binlog同步数据到hive),MySQL表一般会有create_time和update_time字段,如何同步到hive方便查询呢?我们采用的方式是按天快照,更新历史。
模拟SQL如下:在sparksql中,in操作中容易数据倾斜,产生sortMergeJoin,分析如下表,我们怎么优化呢?
SELECT base.id,
base.create_time,
base.update_time,
FROM_UNIXTIME(base.create_time,'yyyyMMdd') as dt
FROM binlogdb.testdb_test_detail base
where FROM_UNIXTIME(base.create_time,'yyyyMMdd') in (
select FROM_UNIXTIME(child.create_time,'yyyyMMdd') as dt
from binlogdb.testdb_test_detail child
where (
child.create_time >= UNIX_TIMESTAMP(concat('2019-08-06',' 00:00:00'))
and child.create_time < UNIX_TIMESTAMP(concat('2019-08-07',' 00:00:00'))
)
or (
child.update_time >= UNIX_TIMESTAMP(concat('2019-08-06',' 00:00:00'))
and child.update_time < UNIX_TIMESTAMP(concat('2019-08-07',' 00:00:00'))
)
group by FROM_UNIXTIME(child.create_time,'yyyyMMdd')
)| hive引擎执行 | SparkSql执行 |
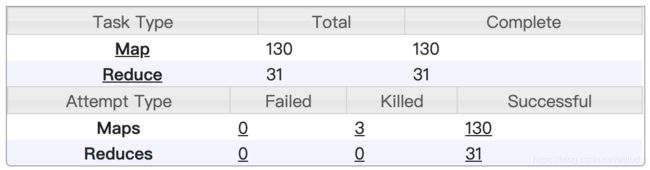
| 总共产生两个job,第一个job是查询中的,第二个是base表符合in中条件的job。 执行耗时8min(比较快)
查询结果共79039368行
第一个job: in 里面的子查询会有map有Reduce,刚开始认为是因为子查询中有group by 才会产生Reduce。
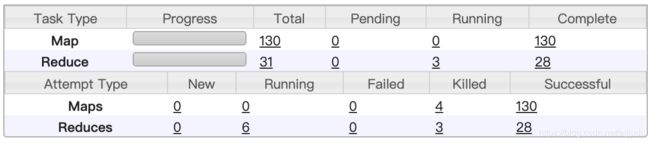
in 中子查询把group by FROM_UNIXTIME(child.create_time,'yyyyMMdd')去掉看执行任务如下:仍然有Reduce。
第二个job: 只有map阶段,也就是说hive把in中的数据进行了广播,base表每个map在本地执行最后落盘就OK。
|
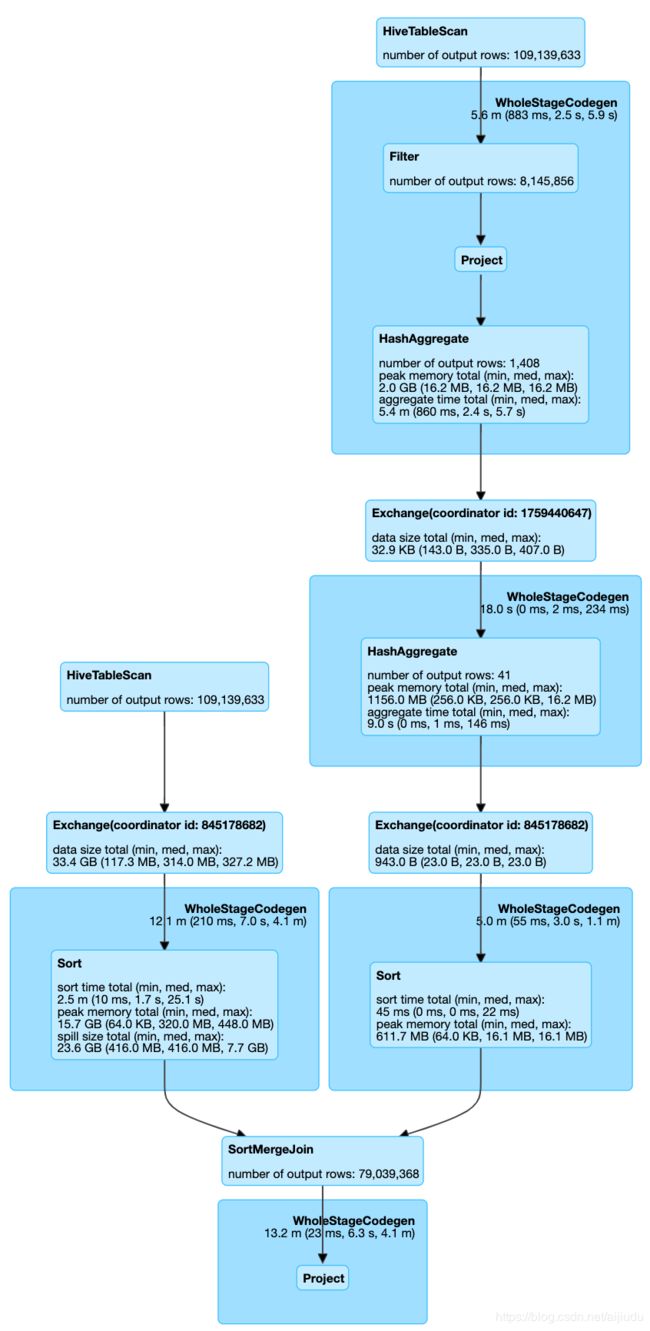
用sparkSQL,会产生sortMergeJoin超级耗时,容易产生数据倾斜,资源全开也得10min以上,数据倾斜会到1h以上。
|
二、用join替代in
hive在0.13版本以后开始支持更多的子查询,如in ,not in的子查询。
以前的版本不支持where子句中的子查询
如:. select * from base t1 where t1.key in(select t2.key from test t2);
可用以下两种方式替换:
select * from base t1 left outer join test t2 on t1.key=t2.key where t2.key <> null;
select * from base t1 left semi join test t2 on t1.key=t2.key;
如下模拟SQL把left semi join 替换成left outer join效果是一样的
SELECT base.id,
base.create_time,
base.update_time,
FROM_UNIXTIME(base.create_time,'yyyyMMdd') as dt
FROM binlogdb.testdb_test_detail base
left semi join (
select FROM_UNIXTIME(child.create_time,'yyyyMMdd') as dt
from binlogdb.testdb_test_detail child
where (
child.create_time >= UNIX_TIMESTAMP(concat('2019-08-06',' 00:00:00'))
and child.create_time < UNIX_TIMESTAMP(concat('2019-08-07',' 00:00:00')))
or (
child.update_time >= UNIX_TIMESTAMP(concat('2019-08-06',' 00:00:00'))
and child.update_time < UNIX_TIMESTAMP(concat('2019-08-07',' 00:00:00'))
)
group by FROM_UNIXTIME(child.create_time,'yyyyMMdd')
)test
on FROM_UNIXTIME(base.create_time,'yyyyMMdd') = test.dt注意:替换成Join的方式用hive跑时间和in基本没有区别,用spark跑还是会遇到sortMergeJoin,出现数据倾斜,运行时间长的问题。
三、用join替换in且map端Join
1)sql hint (从spark 2.3版本开始支持)
SELECT /*+ MAPJOIN(b) */ ...
SELECT /*+ BROADCASTJOIN(b) */ ...
SELECT /*+ BROADCAST(b) */ ...2)broadcast function:DataFrame.broadcast
testTable3= testTable1.join(broadcast(testTable2), Seq("id"), "right_outer")
3)自动优化
org.apache.spark.sql.execution.SparkStrategies.JoinSelection
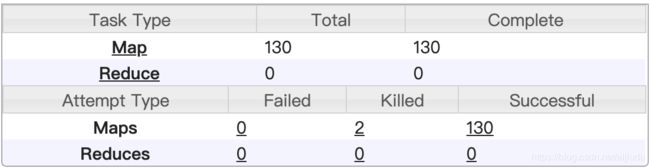
模拟SQL如下:增加了一个 /*+ BROADCAST(test) */ 可以发现运行时长是2.5min,如果数据量大时效性提升更加明显。可以成倍提高效率。
用hive执行 /*+ BROADCAST(test) */ 替换成:/*+ MAPJOIN(child) */ 执行效率和不加是一样的,猜测hive的MR引擎本身做了优化。
SELECT /*+ BROADCAST(test) */
base.id,
base.create_time,
base.update_time,
FROM_UNIXTIME(base.create_time,'yyyyMMdd') as dt
FROM binlogdb.testdb_test_detail base
left semi join (
select FROM_UNIXTIME(child.create_time,'yyyyMMdd') as dt
from binlogdb.testdb_test_detail child
where (
child.create_time >= UNIX_TIMESTAMP(concat('2019-08-06',' 00:00:00'))
and child.create_time < UNIX_TIMESTAMP(concat('2019-08-07',' 00:00:00')))
or (
child.update_time >= UNIX_TIMESTAMP(concat('2019-08-06',' 00:00:00'))
and child.update_time < UNIX_TIMESTAMP(concat('2019-08-07',' 00:00:00'))
)
group by FROM_UNIXTIME(child.create_time,'yyyyMMdd')
)test
on FROM_UNIXTIME(base.create_time,'yyyyMMdd') = test.dt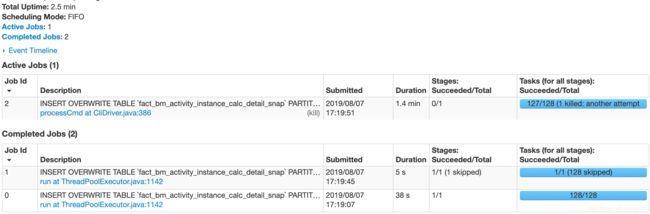

四、用Join替换in的坑
in写法的模拟SQL
select base.id
from (
select 'A' as id
union all select 'b' as id
union all select 'b' as id
)base
where base.id in ('A','b','b')执行结果:
| id |
| A |
| b |
| b |
join on 和 left semi on 的区别:
1)left semi join 是只传递表的 join key 给 map 阶段,因此left semi join 中最后 select 的结果只许出现左表。
这样的写法是错误的,不能出现child表的数据。
select base.id as id,
child.name as name
from (
select 'A' as id
union all select 'b' as id
union all select 'b' as id
)base
left semi join (
select 'A' as id,
'A_name' as name
union all select 'b' as id,
'B_name' as name
)child
on base.id=child.id这样的写法才是正确的,模拟SQL如下
用真实表,base表大概1亿条数据测试,如果child的数据量很少,base表数据量比较大
select id
from (
select 'A' as id
union all select 'b' as id
union all select 'b' as id
)base
left semi join (
select 'A' as id,
'A_name' as name
union all select 'b' as id,
'B_name' as name
union all select 'b' as id,
'B_name' as name
)child
on base.id=child.id
如何提高效率
用真实表,base表大概1亿条数据测试,如果child的数据量很少,base表数据量比较大,
用sparkSQL,采用如下方式优化能避免sortMergeJoin,进行BroadCastHashJoin
select
/*+ MAPJOIN(b) */
id
from (
select 'A' as id
union all select 'b' as id
union all select 'b' as id
)base
left semi join (
select 'A' as id,
'A_name' as name
union all select 'b' as id,
'B_name' as name
union all select 'b' as id,
'B_name' as name
)child
on base.id=child.id执行结果:
| id |
| A |
| b |
| b |
2) left semi join 是 in(keySet) 的关系,遇到右表重复记录,左表会跳过,而 join 则会一直遍历。这就导致右表有重复值得情况下 left semi join 只产生一条,join 会产生多条,也会导致 left semi join 的性能更高。
如果把left semi join 改成 left outer join 关联的结果就会变,要注意写法
select base.id as id
from (
select 'A' as id
union all select 'b' as id
union all select 'b' as id
)base
left outer join (
select 'A' as id,
'A_name' as name
union all select 'b' as id,
'B_name' as name
union all select 'b' as id,
'B_name' as name
)child
on base.id=child.id
注意用left outer join 代替in 就要保证原来in子查询的部分去重。
应该按照如下写法:
select base.id as id
from (
select 'A' as id
union all select 'b' as id
union all select 'b' as id
)base
left outer join (
select test.id
from (
select 'A' as id,
'A_name' as name
union all select 'b' as id,
'B_name' as name
union all select 'b' as id,
'B_name' as name
)test
group by test.id
)child
on base.id=child.id
同时用left outer join 的时候 就能使用child表(关联表)的name字段了,注意left semi join 不能用子查询的字段,因为其相当于in
select base.id as id,
child.name as name
from (
select 'A' as id
union all select 'b' as id
union all select 'b' as id
)base
left outer join (
select test.id,
test.name
from (
select 'A' as id,
'A_name' as name
union all select 'b' as id,
'B_name' as name
union all select 'b' as id,
'B_name' as name
)test
group by test.id,
test.name
)child
on base.id=child.id
3)如上分析,left semi join 是受限制, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。