初试 Ceph 存储之块设备、文件系统、对象存储
目录
- Ceph 存储介绍
- 环境、软件准备
- Ceph 块设备
- Ceph 文件系统
- Ceph 对象存储
1、Ceph 存储介绍
Ceph 是一个开源的分布式存储系统,包括对象存储、块设备、文件系统。它可靠性高、管理方便、伸缩性强,能够轻松应对PB、EB级别数据。Ceph 存储体系中,核心为 RADOS,它是一个高可用分布式对象存储,该模块负责对集群众多 OSD 的运行,保证存储系统的可用性。同时该模块通过 LIBRADOS 的公共库对外提供存储服务,如对象存储、块设备存储。
通过官网文档 Ceph 体系结构 中的图片可以很清楚的了解 Ceph 存储体系。这里就不一一阐述各个组件了。
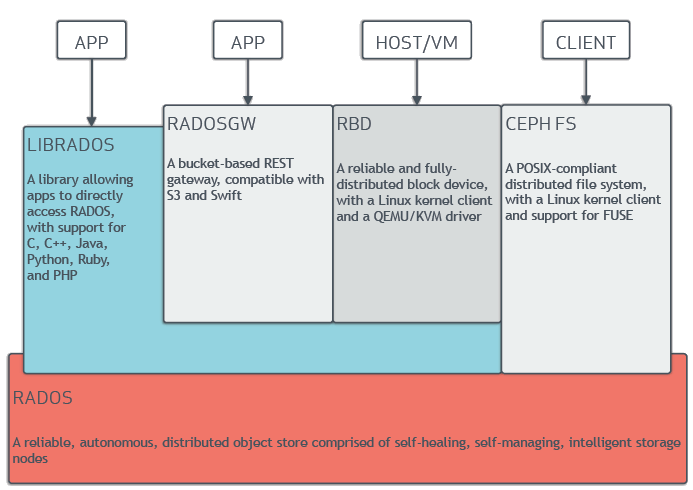
2、环境、软件准备
要使用 Ceph 存储体系中的块设备、文件系统以及对象存储,必须保证已完成 Ceph 存储集群的搭建,并且保证 Ceph 存储集群处于 active + clean 状态。这里搭建过程可以参考上一篇 初试 Centos7 上 Ceph 存储集群搭建 文章,讲解的很详细,这里就忽略搭建过程。顺便在提一下本次演示的存储集群架构图,方便下边使用时更清晰一些。
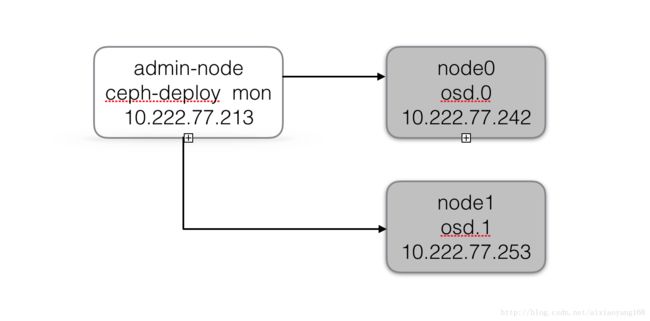
3、Ceph 块设备
Ceph 块设备也可以简称为 RBD 或 RADOS 块设备,不过我们还是习惯叫 RBD,官网文档中指出不能在与 Ceph 存储集群(除非它们也用 VM )相同的物理节点上执行使用 RBD,不过这里我们都是使用的虚拟机,所以暂时可以不用另起一个机器测试,可以直接在 admin-node 节点上执行。当然,另起一个虚拟机或者机器更好一些。
如果另起一个节点的话,那么就得安装 Ceph 到该节点上并配置。注意:以下操作是基于上一篇文章已搭建好的集群结构及目录的,使用 cephd 账号。
1、在管理节点(admin-node)上,通过 ceph-deply 将 Ceph 安装到该节点 node2(假设将新节点 hostname 设置为 node2)。
$ ceph-deploy install node22、在管理节点(admin-node)上,通过 ceph-deploy admin 将 Ceph 配置文件和 ceph.client.admin.keyring 密钥同步到该节点 node2。
# 切换到 Ceph 配置文件和密钥所在目录,同上一篇。
$ cd ~/ceph-cluster
$ ceph-deploy admin node2ceph-deploy 部署工具将密钥信息复制到 node2 的 /etc/ceph 目录,要确保该密钥环文件有读权限,若没有,到 node2 节点上执行 sudo chmod +r /etc/ceph/ceph.client.admin.keyring 命令。
本次演示,我们不增加新节点,直接在 admin-node 节点上操作,在集群搭建时已经完成上述操作,这里就不用再安装配置 Ceph 了。接下来需要配置 RBD。
1、首先在 admin-node 节点上创建一个块设备镜像 image。
# 创建一个大小为 1024M 的 ceph image
$ rbd create foo --size 1024
# 查看已创建的 rbd 列表
$ rbd list
foo2、创建成功后,在 admin-node 节点上,把 foo image 映射到内核,并格式化为块设备。
$ rbd map foo --name client.admin
modprobe: ERROR: could not insert 'rbd': Operation not permitted
rbd: failed to load rbd kernel module (1)
rbd: sysfs write failed
In some cases useful info is found in syslog - try "dmesg | tail" or so.
rbd: map failed: (2) No such file or directory报错了,这个原因是没有权限执行,sudo 执行一下。
$ sudo rbd map foo --name client.admin
modprobe: ERROR: could not insert 'rbd':: Cannot allocate memory
...又报错了,看显示没内存了。。。好吧,给虚拟机增加 1G 内存试试。
$ sudo rbd map foo --name client.admin
RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable".
In some cases useful info is found in syslog - try "dmesg | tail" or so.
rbd: map failed: (6) No such device or address又报错了,看日志 RBD image feature set mismatch,看样子是 feature 不匹配啊!那我们先看一下 foo 都有那些 feature.
$ rbd info foo
rbd image 'foo':
size 1024 MB in 256 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.10222ae8944a
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags: 我们可以看到 rbd image foo 支持匹配的 feature 为:layering, exclusive-lock, object-map, fast-diff, deep-flatten。查看资料后,通过 uname -r 发现我们安装的 Ceontos7 内核版本为 3.10.0-693.5.2.el7.x86_64 只能支持 layering。。。 好吧,那么只能手动去掉那些不支持的 feature。有两种方式可以修改:
方式一:通过 rbd feature disable ... 命令临时关闭不支持的 feature 类型。注意:这种方式设置是临时性,一旦 image 删除或者创建新的 image 时,还会恢复默认值。
$ rbd feature disable foo exclusive-lock, object-map, fast-diff, deep-flatten
$ rbd image 'foo':
size 1024 MB in 256 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.37132ae8944a
format: 2
features: layering
flags: 方式二:通过设置 /etc/ceph/ceph.conf 配置文件,增加 rbd_default_features 配置可以永久的改变默认值。注意:这种方式设置是永久性的,要注意在集群各个 node 上都要修改。
$ vim /etc/ceph/ceph.conf
rbd_default_features = 1 # 增加配置默认 feature 为 layering 对应的bit码整数值 1配置完毕,再次执行 map 命令。
$ sudo rbd map foo --name client.admin
/dev/rbd0终于 map 成功了。
3、创建文件系统,将 foo image 格式化为 ext4 格式的文件系统,就可以使用块设备了。
$ sudo mkfs.ext4 -m0 /dev/rbd/rbd/foo
# 注意这里上边 map 时返回的路径为 /dev/rbd0,这里格式化路径为 /dev/rbd/rbd/foo,其实是同一个地址。
$ ls -al /dev/rbd/rbd/foo
lrwxrwxrwx 1 root root 10 12 7 18:10 /dev/rbd/rbd/foo -> ../../rbd0稍等片刻之后,就格式化成功了。
4、在管理节点(admin-node)上挂载该块设备就可以测试使用了。
$ sudo mkdir /mnt/rbd
$ sudo mount /dev/rbd/rbd/foo /mnt/rbd
# 查看挂载情况
$ df -h
...
/dev/rbd0 976M 2.6M 958M 1% /mnt/rbd5、最后,我们测试一下生成一个 500M 大文件,看是否自动同步到 node0 和 node1 吧!
$ cd /mnt/rbd
$ sudo dd if=/dev/zero of=testrbd bs=500M count=1
记录了1+0 的读入
记录了1+0 的写出
524288000字节(524 MB)已复制,1.99325 秒,263 MB/秒
# 查看挂载磁盘信息
$ df -h
...
/dev/rbd0 976M 503M 458M 53% /mnt/rbd
# 查看 node0 磁盘空间大小
$ ssh node0
$ df -h我们会发现,node0 和 node1 节点上可用磁盘空间减少了大概 500M,说明自动同步成功。
3、Ceph 文件系统
Ceph 文件系统,我们一般称为 cephfs。接下来我们演示一下如何创建一个 cephfs 文件系统。注意:如果在新的节点上使用 cephfs 的话,需要通过 ceph-deploy 安装 ceph 到该节点上,这里就不在描述了,参照上边块设备第一部分安装即可。这里我还是在 admin-node 上创建文件系统。一个 Ceph 文件系统需要至少两个 RADOS 存储池,一个用于数据、一个用于元数据。接下来,我们先创建两个存储池。
$ ceph osd pool create cephfs_data 64
pool 'cephfs_data' created
$ ceph osd pool create cephfs_metadata 64
pool 'cephfs_metadata' created创建完毕,就可以用 fs new ... 命令创建文件系统了。
$ ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 11 and data pool 10
$ ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]OK,cephfs 文件系统已经创建完毕,接下来我们看下元数据 MDS 的状态,看看是否为 active 状态。
$ ceph mds stat
e2: 0/0/1 up看样子,好像没有达到 active 状态。先卖个关子,这里先不管,直接继续下边的操作,看下会出现什么问题。
接下来,我们要挂载创建好的文件系统。有两种方式挂载,一种是使用内核驱动挂载,一种是用户空间挂载。
3.1 内核驱动挂载
Ceph v0.55 及后续版本默认开启了 cephx 认证,所以在挂载时,需要指明其密钥,以便通过认证。这里的密钥环就是之前提到的 ceph.client.admin.keyring 文件。
# 复制密钥 key
$ cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQD/6ShariweMRAAkc1xN/H0ocAlpjp09z5blw==
caps mds = "allow *"
caps mon = "allow *"
caps osd = "allow *"
# 创建挂载目录
$ sudo mkdir /mnt/cephfs
# 挂载 cephfs 到该目录,并指明用户名和密钥
$ sudo mount -t ceph 10.222.77.213:6789:/ /mnt/cephfs -o name=admin,secret=AQD/6ShariweMRAAkc1xN/H0ocAlpjp09z5blw==不过这种方式,会把密钥显示留在了 Bash 命令里面,我们可以更安全的方式从文件读取。
# 将密钥 key 保存到文件中
$ sudo vim /etc/ceph/admin.secret
AQD/6ShariweMRAAkc1xN/H0ocAlpjp09z5blw==
$ sudo mount -t ceph 10.222.77.213:6789:/ /mnt/cephfs -o name=admin,secretfile=/etc/ceph/admin.secret不过很遗憾,执行报错 mount error 5 = Input/output error。这就是上边元数据 MDS 的状态那里出的问题。因为我们必须部署至少一个元数据服务器才能使用 CephFS 文件系统。接下来,我们就部署一个元数据服务器 MDS。
# 在 ceph-deploy (admin-node) 节点上执行
$ ceph-deploy mds create admin node0 node1
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephd/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /bin/ceph-deploy --overwrite-conf mds create admin node0 node1
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : True
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : deploy.conf.cephdeploy.Conf instance at 0x2396170>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function mds at 0x237fc80>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] mds : [('admin', 'admin'), ('node0', 'node0'), ('node1', 'node1')]
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.mds][DEBUG ] Deploying mds, cluster ceph hosts admin:admin node0:node0 node1:node1
[admin][DEBUG ] connection detected need for sudo
[admin][DEBUG ] connected to host: admin
[admin][DEBUG ] detect platform information from remote host
[admin][DEBUG ] detect machine type
[ceph_deploy.mds][INFO ] Distro info: CentOS Linux 7.4.1708 Core
[ceph_deploy.mds][DEBUG ] remote host will use systemd
[ceph_deploy.mds][DEBUG ] deploying mds bootstrap to admin
...
[node1][INFO ] Running command: sudo ceph --cluster ceph --name client.bootstrap-mds --keyring /var/lib/ceph/bootstrap-mds/ceph.keyring auth get-or-create mds.node1 osd allow rwx mds allow mon allow profile mds -o /var/lib/ceph/mds/ceph-node1/keyring
[node1][INFO ] Running command: sudo systemctl enable ceph-mds@node1
[node1][WARNIN] Created symlink from /etc/systemd/system/ceph-mds.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
[node1][INFO ] Running command: sudo systemctl start ceph-mds@node1
[node1][INFO ] Running command: sudo systemctl enable ceph.target 创建成功,我们在看一下当前集群 MDS 状态。
$ ceph mds stat
e6: 1/1/1 up {0=node0=up:active}, 1 up:standby这次状态是 active 状态,没有问题。再次执行上述操作,妥妥没问题了。
$ df -h
...
10.222.77.213:6789:/ 66G 33G 33G 50% /mnt/cephfs这里可以看到 cephfs 将两个节点 node0 和 node1 容量合并了。(我的虚拟机 node0、node1 / 根目录容量为 33 G,每个节点使用了 16G 左右。)
最后,我们在测试一下生成一个 1G 大文件,看是否自动同步到 node0 和 node1 吧!
$ sudo dd if=/dev/zero of=testfs bs=1G count=1
记录了1+0 的读入
记录了1+0 的写出
1073741824字节(1.1 GB)已复制,9.0857 秒,118 MB/秒
$ df -h
...
10.222.77.213:6789:/ 66G 36G 30G 55% /mnt/cephfs注意: 如需卸载 cephfs 文件系统,可以使用 sudo umount /mnt/cephfs 即可。
3.2 用户空间文件系统(FUSE)
将 Ceph FS 挂载为用户空间文件系统,非常简单,需要使用 FUSE 工具。
# 安装 fuse
$ yum install -y ceph-fuse
# 创建目录
$ sudo mkdir ~/cephfs
# 密钥文件已存在 /etc/ceph 目录下时
$ sudo ceph-fuse -m 10.222.77.213:6789 ~/cephfs如果密钥文件不在 /etc/ceph 目录,二是在其他目录的话,需要指定密钥文件.
$ sudo ceph-fuse -k /ceph.client.admin.keyring -m 10.222.77.213:6789 ~/cephfs 4、对象存储方式
Ceph 对象存储可以简称为 RGW,Ceph RGW 是基于 librados,为应用提供 RESTful 类型的对象存储接口,其接口方式支持 S3(兼容 Amazon S3 RESTful API) 和 Swift(兼容 OpenStack Swift API) 两种类型。接下来就分别演示通过这两种方式使用 Ceph RGW。
1、首先需要安装 Ceph 对象网关。
Ceph 从 v0.80 开始,使用内嵌 Civetweb 作为 Web Server,无需额外安装 web 服务器或配置 FastCGI,其默认端口为 7480。在 admin-node 管理节点目录通过 ceph-deploy 安装 Ceph RGW。这里我们还是使用 admin-node 节点做测试。
$ cd ~/ceph-cluster
$ ceph-deploy install --rgw admin注意: 在新节点或者没有安装 rgw 的节点上执行,这里我们 admin-node 节点初次安装 ceph 的时候,已经安装上了 rgw。
2、新建 Ceph 对象网关实例
在 admin-node 管理节点工作目录创建一个 Ceph rgw 实例,一旦对象网关开始运行,我们就可以通过 http://admin:7480 地址访问啦。
$ cd ~/ceph-cluster
$ ceph-deploy --overwrite-conf rgw create admin
[ceph_deploy.conf][DEBUG ] found configuration file at: /home/cephd/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /bin/ceph-deploy --overwrite-conf rgw create admin
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] rgw : [('admin', 'rgw.admin')]
[ceph_deploy.cli][INFO ] overwrite_conf : True
[ceph_deploy.cli][INFO ] subcommand : create
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : deploy.conf.cephdeploy.Conf instance at 0x2088a28>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function rgw at 0x1ff1b18>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.rgw][DEBUG ] Deploying rgw, cluster ceph hosts admin:rgw.admin
[admin][DEBUG ] connection detected need for sudo
[admin][DEBUG ] connected to host: admin
[admin][DEBUG ] detect platform information from remote host
[admin][DEBUG ] detect machine type
[ceph_deploy.rgw][INFO ] Distro info: CentOS Linux 7.4.1708 Core
[ceph_deploy.rgw][DEBUG ] remote host will use systemd
[ceph_deploy.rgw][DEBUG ] deploying rgw bootstrap to admin
[admin][DEBUG ] write cluster configuration to /etc/ceph/{cluster}.conf
[admin][DEBUG ] create path recursively if it doesn't exist
[admin][INFO ] Running command: sudo ceph --cluster ceph --name client.bootstrap-rgw --keyring /var/lib/ceph/bootstrap-rgw/ceph.keyring auth get-or-create client.rgw.admin osd allow rwx mon allow rw -o /var/lib/ceph/radosgw/ceph-rgw.admin/keyring
[admin][INFO ] Running command: sudo systemctl enable [email protected]
[admin][WARNIN] Created symlink from /etc/systemd/system/ceph-radosgw.target.wants/[email protected] to /usr/lib/systemd/system/[email protected].
[admin][INFO ] Running command: sudo systemctl start [email protected]
[admin][INFO ] Running command: sudo systemctl enable ceph.target
[ceph_deploy.rgw][INFO ] The Ceph Object Gateway (RGW) is now running on host admin and default port 7480 从日志中可以看到 RGW 已经运行起来了,我们来访问以下试下。
$ curl http://admin:7480
<ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/">
<Owner>
<ID>anonymousID>
<DisplayName>DisplayName>
Owner>
<Buckets>Buckets>
ListAllMyBucketsResult>OK 也没有问题。如果我们想修改 7480 端口为其他值时,ceph 也是支持的,通过修改 Ceph 配置文件更改默认端口,然后重启 Ceph 对象网关即可。例如我们修改端口为 80。
# 修改 Ceph 配置文件
$ sudo vim /etc/ceph/ceph.conf
# 在 [global] 节点下增加
[client.rgw.admin]
rgw_frontends = "civetweb port=80"
# 重启 Ceph 对象网关
$ sudo systemctl restart ceph-radosgw.service注意:如果开启了防火墙,需要将新的端口号设置为例外,或者关闭防火墙。
3、使用 Ceph 对象网关
为了使用 Ceph SGW REST 接口, 我们需要为 S3 接口初始化一个 Ceph 对象网关用户. 然后为 Swift 接口新建一个子用户,最后就可以通过创建的用户访问对象网关验证了。
创建 S3 网关用户
我们需要创建一个 RADOSGW 用户并且赋予访问权限,才可以正常访问 RGW,Ceph 提供了 radosgw-admin 命令行很方便完成。
$ sudo radosgw-admin user create --uid="rgwuser" --display-name="This is first rgw test user"
{
"user_id": "rgwuser",
"display_name": "This is first rgw test user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [],
"keys": [
{
"user": "rgwuser",
"access_key": "I67VLSVU40IE84EFLJX4",
"secret_key": "yijKT83RUXRZSOVfwXCQtB2MPnzA7subdQbBPOya"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"temp_url_keys": []
}注意:返回的 Json 值中,我们要记住两个 access_key 和 secret_key 值,因为下边我们测试访问 S3 接口时需要使用。
测试访问 S3 接口
参照官方文档,我们需要编写一个 Python 测试脚本,该脚本将会连接 radosgw,然后新建一个新的 bucket 再列出所有的 buckets。脚本变量 aws_access_key_id 和 aws_secret_access_key 的值就是上边返回值中的 access_key 和 secret_key。
首先,我们需要安装 python-boto 包,用于测试连接 S3。
$ sudo yum install python-boto然后,编写 python 测试脚本。
$ vim s3.py
import boto
import boto.s3.connection
access_key = 'I67VLSVU40IE84EFLJX4'
secret_key = 'yijKT83RUXRZSOVfwXCQtB2MPnzA7subdQbBPOya'
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = 'admin', port=7480,
is_secure=False,
calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('my-first-s3-bucket')
for bucket in conn.get_all_buckets():
print "{name}\t{created}".format(
name = bucket.name,
created = bucket.creation_date,
)注意:这里使用了python-boto 包,使用认证信息连接 S3,然后创建了一个 my-first-s3-bucket 的 bucket,最后列出所有已创建的 bucket,打印名称和创建时间。
最后,执行脚本,看下结果是否正确。
$ python s3.py
my-first-s3-bucket 2017-12-11T13:43:21.962Z测试通过。
创建 Swift 用户
要通过 Swift 访问对象网关,需要 Swift 用户是作为子用户 subuser 被创建的。
$ sudo radosgw-admin subuser create --uid=rgwuser --subuser=rgwuser:swift --access=full
{
"user_id": "rgwuser",
"display_name": "This is first rgw test user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"auid": 0,
"subusers": [
{
"id": "rgwuser:swift",
"permissions": "full-control"
}
],
"keys": [
{
"user": "rgwuser",
"access_key": "I67VLSVU40IE84EFLJX4",
"secret_key": "yijKT83RUXRZSOVfwXCQtB2MPnzA7subdQbBPOya"
}
],
"swift_keys": [
{
"user": "rgwuser:swift",
"secret_key": "sBqvF0PXsVZ8U0g99QB2SX3OZR98BOX67zam9qIy"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"max_size_kb": -1,
"max_objects": -1
},
"temp_url_keys": []
}注意:返回的 Json 值中,我们要记住两个 secret_key 因为下边我们测试访问 Swift 接口时需要使用。
测试访问 Swift 接口
访问 Swift 接口可以通过 swift 命令行客户端来完成,然后通过客户端命令访问 Swift 接口。
# 安装 Swift 命令行客户端
$ sudo apt-get install python-setuptools
$ sudo easy_install pip
$ sudo pip install --upgrade setuptools
$ sudo pip install --upgrade python-swiftclient
# 访问 Swift 接口
$ swift -A http://10.222.77.213:7480/auth/1.0 -U rgwuser:swift -K 'sBqvF0PXsVZ8U0g99QB2SX3OZR98BOX67zam9qIy' list
my-first-s3-bucket注意:10.222.77.213:7480 为网关服务器的外网访问 IP 地址,这里为 admin-node 节点 IP,端口默认 7480,若已修改端口号,这里也需要对应修改一下。密钥 Key 为上边返回值中的 secret_key。
同样,测试通过。
参考资料
- CEPH 块设备
- rbd 介绍
- CEPH 文件系统
- cephfs 介绍
- CEPH 对象存储
- 配置 rgw