《Ceph源码分析》——第1章,第5节RADOS
本节书摘来自华章出版社《Ceph源码分析》一书中的第1章,第1.5节RADOS,作者常涛,更多章节内容可以访问云栖社区“华章计算机”公众号查看
1.5 RADOS
RADOS是Ceph存储系统的基石,是一个可扩展的、稳定的、自我管理的、自我修复的对象存储系统,是Ceph存储系统的核心。它完成了一个存储系统的核心功能,包括:Monitor模块为整个存储集群提供全局的配置和系统信息;通过CRUSH算法实现对象的寻址过程;完成对象的读写以及其他数据功能;提供了数据均衡功能;通过Peering过程完成一个PG内存达成数据一致性的过程;提供数据自动恢复的功能;提供克隆和快照功能;实现了对象分层存储的功能;实现了数据一致性检查工具Scrub。下面分别对上述基本功能做简要的介绍。
1.5.1 Monitor
Monitor是一个独立部署的daemon进程。通过组成Monitor集群来保证自己的高可用。Monitor集群通过Paxos算法实现了自己数据的一致性。它提供了整个存储系统的节点信息等全局的配置信息。
Cluster Map保存了系统的全局信息,主要包括:
Monitor Map
包括集群的fsid
所有Monitor的地址和端口
current epoch
OSD Map:所有OSD的列表,和OSD的状态等。
MDS Map:所有的MDS的列表和状态。
1.5.2 对象存储
这里所说的对象是指RADOS对象,要和RadosGW的S3或者Swift接口的对象存储区分开来。对象是数据存储的基本单元,一般默认4MB大小。图1-5就是一个对象的示意图。
图1-5 对象示意图

一个对象由三个部分组成:
对象标志(ID),唯一标识一个对象。
对象的数据,其在本地文件系统中对应一个文件,对象的数据就保存在文件中。
对象的元数据,以Key-Value(键值对)的形式,可以保存在文件对应的扩展属性中。由于本地文件系统的扩展属性能保存的数据量有限制,RADOS增加了另一种方式:以Leveldb等的本地KV存储系统来保存对象的元数据。
1.5.3 pool和PG的概念
pool是一个抽象的存储池。它规定了数据冗余的类型以及对应的副本分布策略。目前实现了两种pool类型:replicated类型和Erasure Code类型。一个pool由多个PG构成。
PG(placement group)从名字可理解为一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略:对象的副本都分布在相同的OSD列表上。一个对象只能属于一个PG,一个PG对应于放置在其上的OSD列表。一个OSD上可以分布多个PG。
图1-6 PG的概念示意图

PG的概念如图1-6所示,其中:
PG1和PG2都属于同一个pool,所以都是副本类型,并且都是两副本。
PG1和PG2里都包含许多对象,PG1上的所有对象,主从副本分布在OSD1和OSD2上,PG2上的所有对象的主从副本分布在OSD2和OSD3上。
一个对象只能属于一个PG,一个PG包含多个对象。
一个PG的副本分布在对应的OSD列表中。在一个OSD上可以分布多个PG。示例中PG1和PG2的从副本都分布在OSD2上。
1.5.4 对象寻址过程
对象寻址过程指的是查找对象在集群中分布的位置信息,过程分为两步:
1)对象到PG的映射。这个过程是静态hash映射(加入pg split后实际变成了动态hash映射方式),通过对object_id,计算出hash值,用该pool的PG的总数量pg_num对hash值取模,就可以获得该对象所在的PG的id号:
pg_id = hash( object_id ) % pg_num
2)PG到OSD列表映射。这是指PG上对象的副本如何分布在OSD上。它使用Ceph自己创新的CRUSH算法来实现,本质上是一个伪随机分布算法。
图1-7 对象寻址过程

如图1-7所示的对象寻址过程:
1)通过hash取模后计算,前三个对象分布在PG1上,后两个对象分布在PG2上。
2)PG1通过CRUSH算法,计算出PG1分布在OSD1、OSD3上;PG2通过CRUSH算法分布在OSD2和OSD4上。
1.5.5 数据读写过程
Ceph的数据写操作如图1-8所示,其过程如下:
图1-8 读写过程

1)Client向该PG所在的主OSD发送写请求。
2)主OSD接收到写请求后,同时向两个从OSD发送写副本的请求,并同时写入主OSD的本地存储中。
3)主OSD接收到两个从OSD发送写成功的ACK应答,同时确认自己写成功,就向客户端返回写成功的ACK应答。
在写操作的过程中,主OSD必须等待所有的从OSD返回正确应答,才能向客户端返回写操作成功的应答。由于读操作比较简单,这里就不介绍了。
1.5.6 数据均衡
当在集群中新添加一个OSD存储设备时,整个集群会发生数据的迁移,使得数据分布达到均衡。Ceph数据迁移的基本单位是PG,即数据迁移是将PG中的所有对象作为一个整体来迁移。
迁移触发的流程为:当新加入一个OSD时,会改变系统的CRUSH Map,从而引起对象寻址过程中的第二步,PG到OSD列表的映射发生了变化,从而引发数据的迁移。
举例来说明数据迁移过程,表1-1是数据迁移前的PG分布,表1-2是数据迁移后的PG分布。
表1-1 数据迁移前的PG分布
` OSD1 OSD2 OSD3
PGa PGa1 PGa2 PGa3
PGb PGb3 PGb1 PGb2
PGc PGc2 PGc3 PGc1
PGd PGd1 PGd2 PGd3
`
表1-2 数据迁移后的PG分布
` OSD1 OSD2 OSD3 OSD4
PGa PGa1 PGa2 PGa3 PGa1
PGb PGb3 PGb1 PGb2 PGb2
PGc PGc2 PGc3 PGc1 PGc3
PGd PGd1 PGd2 PGd3
`
当前系统有3个OSD,分布为OSD1、OSD2、OSD3;系统有4个PG,分布为PGa、PGb、PGc、PGd;PG设置为三副本:PGa1、PGa2、PGa3分别为PGa的三个副本。PG的所有分布如表1-1所示,每一行代表PG分布的OSD列表。
当添加一个新的OSD4时,CRUSH Map变化导致通过CRUSH算法来计算PG到OSD的分布发生了变化。如表1-2所示:PGa的映射到了列表[OSD4,OSD2,OSD3]上,导致PGa1从OSD1上迁移到了OSD4上。同理,PGb2从OSD3上迁移到OSD4,PGc3从OSD2上迁移到OSD4上,最终数据达到了基本平衡。
1.5.7 Peering
当OSD启动,或者某个OSD失效时,该OSD上的主PG会发起一个Peering的过程。Ceph的Peering过程是指一个PG内的所有副本通过PG日志来达成数据一致的过程。当Peering完成之后,该PG就可以对外提供读写服务了。此时PG的某些对象可能处于数据不一致的状态,其被标记出来,需要恢复。在写操作的过程中,遇到处于不一致的数据对象需要恢复的话,则需要等待,系统优先恢复该对象后,才能继续完成写操作。
1.5.8 Recovery和Backfill
Ceph的Recovery过程是根据在Peering的过程中产生的、依据PG日志推算出的不一致对象列表来修复其他副本上的数据。
Recovery过程的依据是根据PG日志来推测出不一致的对象加以修复。当某个OSD长时间失效后重新加入集群,它已经无法根据PG日志来修复,就需要执行Backfill(回填)过程。Backfill过程是通过逐一对比两个PG的对象列表来修复。当新加入一个OSD产生了数据迁移,也需要通过Backfill过程来完成。
1.5.9 纠删码
纠删码(Erasure Code)的概念早在20世纪60年代就提出来了,最近几年被广泛应用在存储领域。它的原理比较简单:将写入的数据分成N份原始数据块,通过这N份原始数据块计算出M份效验数据块,N+M份数据块可以分别保存在不同的设备或者节点中。可以允许最多M个数据块失效,通过N+M份中的任意N份数据,就还原出其他数据块。
目前Ceph对纠删码(EC)的支持还比较有限。RBD目前不能直接支持纠删码(EC)模式。其或者应用在对象存储radosgw中,或者作为Cache Tier的二层存储。其中的原因和具体实现都将在后面的章节详细介绍。
1.5.10 快照和克隆
快照(snapshot)就是一个存储设备在某一时刻的全部只读镜像。克隆(clone)是在某一时刻的全部可写镜像。快照和克隆的区别在于快照只能读,而克隆可写。
RADOS对象存储系统本身支持Copy-on-Write方式的快照机制。基于这个机制,Ceph可以实现两种类型的快照,一种是pool级别的快照,给整个pool中的所有对象统一做快照操作。另一种就是用户自己定义的快照实现,这需要客户端配合实现一些快照机制。RBD的快照实现就属于后者。
RBD的克隆实现是在基于RBD的快照基础上,在客户端librbd上实现了Copy-on-Write(cow)克隆机制。
1.5.11 Cache Tier
RADOS实现了以pool为基础的自动分层存储机制。它在第一层可以设置cache pool,其为高速存储设备(例如SSD设备)。第二层为data pool,使用大容量低速存储设备(如HDD设备)可以使用EC模式来降低存储空间。通过Cache Tier,可以提高关键数据或者热点数据的性能,同时降低存储开销。
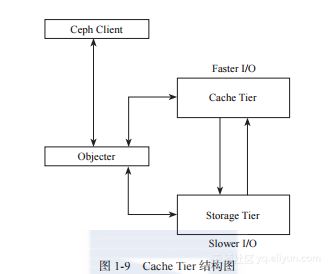
Cache Tier的结构如图1-9所示,说明如下:
Ceph Client对于Cache层是透明的。
类Objecter负责请求是发给Cache Tier层,还是发给Storage Tier层。
Cache Tier层为高速I/O层,保存热点数据,或称为活跃的数据。
Storage Tier层为慢速层,保存非活跃的数据。
在Cache Tier层和Storage Tier层之间,数据根据活跃度自动地迁移。
图1-9 Cache Tier结构图
1.5.12 Scrub
Scrub机制用于系统检查数据的一致性。它通过在后台定期(默认每天一次)扫描,比较一个PG内的对象分别在其他OSD上的各个副本的元数据和数据来检查是否一致。根据扫描的内容分为两种,第一种是只比较对象各个副本的元数据,它代价比较小,扫描比较高效,对系统影响比较小。另一种扫描称为deep scrub,它需要进一步比较副本的数据内容检查数据是否一致。