IR常用评价指标计算方式(AUC,MAP,NDCG,MRR,Precision、Recall、F-score)
AUC,MAP,NDCG,MRR,Precision、Recall、F-score
1.AUC(Area Under Curve)
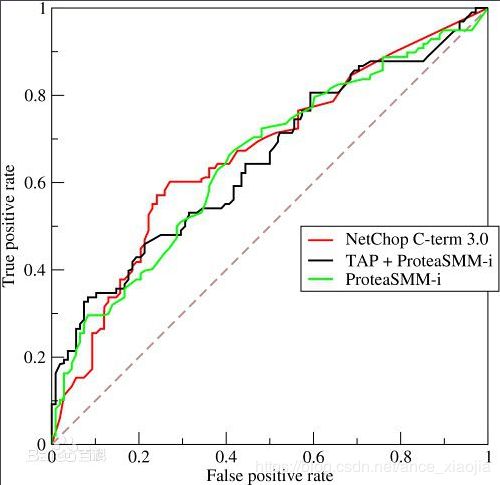
ROC曲线下方的面积大小,由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
首先AUC值是一个概率值,当你随机挑选一个正样本以及一个负样本,当前的分类算法根据计算得到的Score值将这个正样本排在负样本前面的概率就是AUC值。当然,AUC值越大,当前的分类算法越有可能将正样本排在负样本前面,即能够更好的分类。
2.MAP(Mean Average Precision)
MAP:单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。

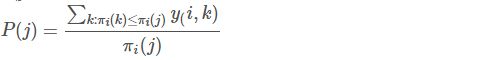
MAP是为解决Precision、Recall、F-score的单点值局限性的,同时考虑检索效果的排名情况。计算如下:假设有两个主题,主题1有4个相关网页,主题2有5个相关网页。某系统对于主题1检索出4个相关网页,其rank分别为1,2,4,7;对于主题2检索出3个相关网页,其rank分别为1,3,5。对于主题1,平均准确率为(1/1+2/2+3/4+4/7) / 4 = 0.83。对于主题2,平均准确率为(1/1+2/3+3/5+0+0) / 5 = 2.45。则MAP=(0.83+0.45) / 2 = 0.64。
3.NDCG(Normalized Discounted Cumulative Gain)


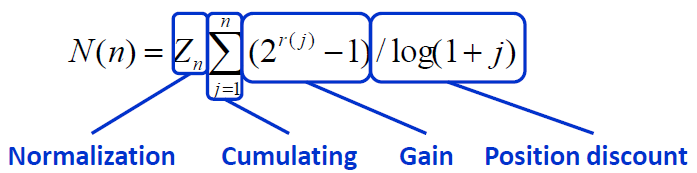
NDCG(Normalized Discounted Cumulative Gain):计算相对复杂。对于排在结位置n处的NDCG的计算公式如下图所示:
在MAP中,四个文档和query要么相关,要么不相关,也就是相关度非0即1。NDCG中改进了下,相关度分成从0到r的r+1的等级(r可设定)。当取r=5时,等级设定如下图所示:
 (应该还有r=1那一级,原文档有误,不过这里不影响理解)
(应该还有r=1那一级,原文档有误,不过这里不影响理解)
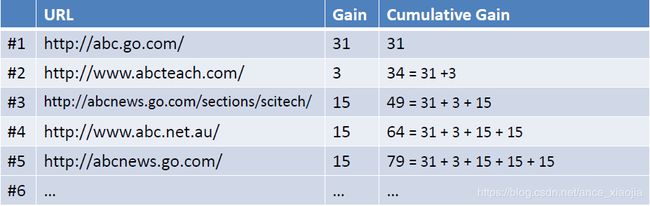
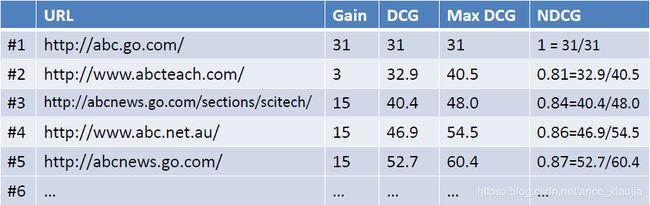
例如现在有一个query={abc},返回下图左列的Ranked List(URL),当假设用户的选择与排序结果无关(即每一级都等概率被选中),则生成的累计增益值如下图最右列所示:
考虑到一般情况下用户会优先点选排在前面的搜索结果,所以应该引入一个折算因子(discounting factor): log(2)/log(1+rank)。这时将获得DCG值(Discounted Cumulative Gain)如下如所示:

最后,为了使不同等级上的搜索结果的得分值容易比较,需要将DCG值归一化的到NDCG值。操作如下图所示,首先计算理想返回结果List的DCG值:

然后用DCG/MaxDCG就得到NDCG值,如下图所示:
4.MRR(Mean Reciprocal Rank)

其中|Q|是查询个数,ranki是第i个查询,第一个相关的结果所在的排列位置。
即把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。
5.Precision、Recall、F-score
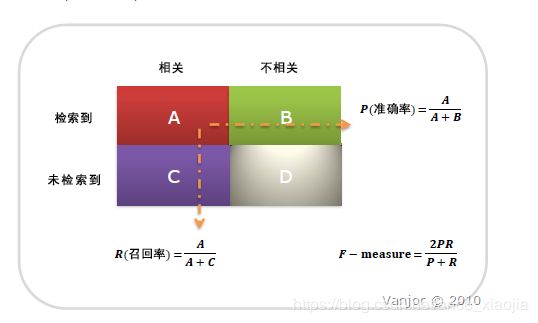
信息检索、分类、识别、翻译等领域两个最基本指标是召回率(Recall Rate)和准确率(Precision Rate——注意统计学习方法中precision称为精确率,而准确率accuracy是分类正确的样本除以总样本的个数),召回率也叫查全率,准确率也叫查准率。
公式如下:
召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数。亦即,预测为真实正例 / 所有真实正例样本的个数。
准确率(Precision) = 系统检索到的相关文件 / 系统所有检索到的文件总数。亦即,预测为真实正例 / 所有被预测为正例样本的个数。
注意:准确率和召回率是相互影响的,理想情况下肯定是做到两者都高,但是一般情况下,准确率高、召回率就低;召回率低、准确率高。当然如果两者都低,那是什么地方出问题了。一般情况,用不同的阈值,统计出一组不同阈值下的精确率和召回率,如下图:

如果是做搜索,那就是保证召回率的情况下提升准确率;如果做疾病检测、反垃圾,则是保证准确率的条件下,提升召回率。所以,在两者都要求高的情况下,可以用F1(或者称为F-score)来衡量。计算公式如下:F1 = (2 × P × R) / (P + R)。
转载自:
https://blog.csdn.net/weixin_38405636/article/details/80675312
https://blog.csdn.net/lightty/article/details/47079017
https://blog.csdn.net/universe_ant/article/details/70090026
https://blog.csdn.net/Allenalex/article/details/78161915
https://www.cnblogs.com/eyeszjwang/articles/2368087.html