饿了么多活高可用思想
饿了么业务快速发展,给技术带来了海量请求和高并发、微服务的挑战,同时开发团队快节奏的版本迭代和服务快速上线的要求也驱动运维团队提供稳定、高效的运维服务。

2017 年 12 月 01 日-02 日,由 51CTO 主办的 WOTD 全球软件开发技术峰会在深圳中州万豪酒店隆重举行。
饿了么技术运营负责人程炎岭在创新运维探索专场与来宾分享了"跨越篱笆-饿了么多活运维上下求索"的主题演讲,从业务发展和多活后的技术运营保障,结合具体案例,分享饿了么在运维方面的探索以及实践经验。
我是饿了么的技术运营负责人,见证了饿了么业务的飞速发展。记得 2015 年加入饿了么的时候,我们的日订单量只有 30 万笔;而到了 2017 年,我们的日订单量已经超过 1000 万笔。
考虑到我们在整个市场的体量和单个机房至多只能处理 2000 万笔订单的上限,我们逐步推进了面向百分之百冗余多活的新规划。
今天的分享主要分为三个部分:
- 多活场景及业务形态
- 饿了么多活运维挑战
- 饿了么运营体系探索
多活场景及业务形态
饿了么多活的现状

首先介绍一下饿了么整个多活的现状:我们在北京和上海共有两个机房提供生产服务。机房和 ezone 是两个不同的概念,一个机房可以扩展多个 ezone,目前是一对一关系。
我们还有两个部署在公有云的接入点,作为全国流量请求入口。它们分别受理南北方的部分流量请求,接入点都部署在阿里云上面,同时从运维容灾角度出发。
我们考虑到两个云入口同时“宕掉”的可能性,正在筹建 IDC 内的备用接入点,作为灾备的方案。
多活从 2017 年 5 月份的第一次演练成功到现在,我们经历过 16 次整体性的多活切换。
这 16 次切换既包含正常的演练,也包含由于发生故障而进行的真实切换。其中,最近的一次切换是因为我们上海机房的公网出口发生了故障,我们将其所有流量都切换到了北京。
实现多活的背景
下面我从五方面介绍实施多活之前的一些背景状况:
- 业务特点
- 技术复杂
- 运维兜底
- 故障频发
- 机房容量
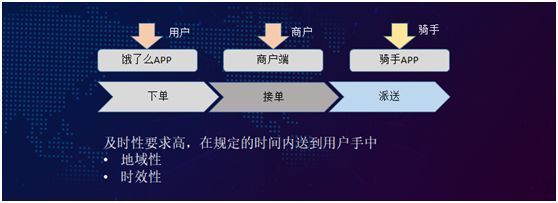
业务特点:我们有三大流量入口,分别是用户端、商户端以及骑手端。
一个典型的下单流程是:用户打开 App 产生一个订单,店家在商户端进行接单,然后生成一个物流派送服务的运单。
而该流程与传统电商订单的区别在于:如果在商城生成一个订单,后台商户端可以到第二天才收到,这种延时并无大碍。
但是对于饿了么就不行,外卖的时效性要求很高,如果在 10 分钟之内商户还未接单的话,用户要么会去投诉,要么可能就会取消订单,更换美团、百度外卖,从而会造成用户的流失。
另外,我们也有很强的地域性。比如说在上海生成的订单,一般只适用于上海本地区,而不会需要送到其他地方。
同时,我们的业务也有着明显的峰值,上午的高峰,一般在 11 点;而下午则会是在 5 点到 6 点之间。
我们通过整个监控曲线便可对全链路的请求一目了然。这就是我们公司乃至整个外卖行业的业务特点。
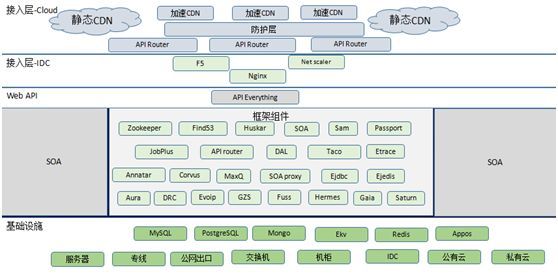
技术复杂:上图是流量请求从进入到底层的整个技术架构。
SOA(面向服务的体系结构)系统架构本身并不复杂,其实大部分互联网公司的技术架构演进到最后都是类似的。
我们真正的复杂之处在于:各种组件、基础设施以及整个的接入层存在多语言的问题。
在 2015 年之前,我们的前端是用 PHP 写的,而后端则是 Python 写的。在经历了两年的演进之后,我们现在已把所有由 PHP 语言写的部分都替换掉了。而为了适用多种语言,我们的组件不得不为某一种语言多做一次适配。
比如说:我们要跟踪(trace)整个链路,而且用到了多种语言,那么我们就要为之研发出多种 SDK,并需要花大量的成本去维护这些 SDK。
可见,复杂性往往不在于我们有多少组件,而是我们要为每一种组件所提供的维护上。
我们当前的整个 SOA 框架体系主要面向两种语言:Python 和 Java,逐渐改造成更多地面向 Java。
中间的 API Everything 包含了许多为不同的应用场景而开发的各种 API 项目。而我们基础设施方面,主要包括了整个存储与缓存,以及公有云和私有云。
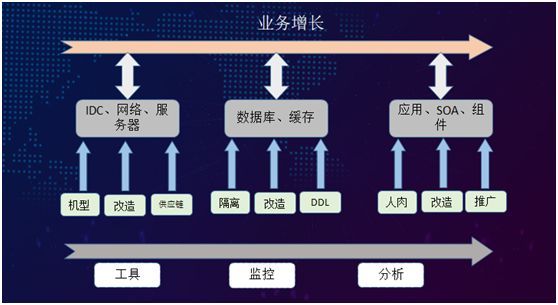
运维兜底:在业务飞速发展的过程当中,我们的运维团队做得更多的还是“兜底”工作。
最新的统计,我们现在有将近 16000 台服务器、1600 个应用、1000 名开发人员、4 个物理 IDC、以及部署了防护层的两朵云。也有一些非常小的第三方云服务平台,包括 AWS 和阿里聚石塔等。
在业务增长过程当中,基于整个 IDC 的基础设施环境,我们对交付的机型统一定制,并且改进了采购的供应链,包括:标准化的整机柜交付和数据清洗等。
对于应用使用的数据库与缓存,我们也做了大量的资源拆分与改造工作,比如数据库,改造关键路径隔离,垂直拆分,sharding,SQL 审核,接入数据库中间件dal,对缓存 redis 使用治理,迁移自研的 redis cluster 代理 corvus,联合框架实现存储使用的规范化,服务化。
曾经面临比较大的挑战是数据库 DDL,表设计在每家公司都有一些自己的特点,例如阿里、百度他们每周 DDL 次数很少。
但是我们每周则会有将近三位数的 DDL 变更,这和项目文化以及业务交付有关。
DBA 团队以及 DAL 团队为此做了几件事情:表数据量红线,基于 Gh-OST 改进 online schema change 工具,Edb 自助发布。这样大大减少了数据库 DDL 事故率以及变更效率。
在多活改造过程中,工具的研发速度相对落后,我们在运维部署服务,组件的推广和治理过程中,大部分都还是人工推广、治理。
我们还负责全网的稳定性,以及故障管理,包括预案演练、故障发现、应急响应、事故复盘等,以及对事故定损定级。
故障管理并不是为了追责,而是通过记录去分析每一次故障发生的原因,以及跟进改进措施,避免故障再次发生。
我们还定义了一个全网稳定性计数器,记录未发生重大事故的累计时间,当故障定级应达到 P2 以上时清零重新开始。
历史上我们保持最长的全网稳定性纪录是 135 天,而美团已经超过了 180 天,还有一些差距。
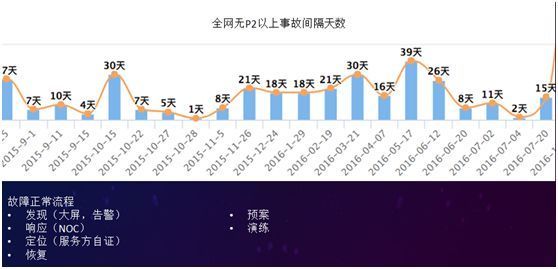
故障频发:根据上图“故障频发”所反映的数据,大家可以看到,2015 年和 2016 年的数据惨不忍睹。
按天计算,我们经常会出现 P2 级别以上的事故,最短的是隔 1 天就出现 1 个 P2 以上事故。
我们不得不进行改进,于是我们组建了一个叫 NOC(Notification Operation Center)的团队。
这个是参照 Google SRE 所建立的负责 7*24 应急响应团队,以及初步原因判断,执行常规的演练,组织复盘,跟进复盘改进落地情况。
NOC 定义公司通用故障定级定损/定责的标准:P0—P5 的事故等级,其参照的标准来自于业务特性的四个维度,它们分别是:
- 在高峰期/非高峰期的严重影响,包括受损时间段和受损时长。
- 对全网业务订单的损失比。
- 损失金额。
- 舆情的影响。包括与美团、百度外卖、其他平台的竞争。不过区别于外卖食材的本身品质,我们这里讨论的是技术上的故障。 比如商家无缘无故取消了客户的订单,或是由于其他各种原因导致客户在微博、或向客服部门投诉的数量上升。
上述这些不同的维度,结合高峰期与低峰期的不同,都是我们定级的标准。
根据各种事故运营定级/定责的规范,我们建立了响应的排障 SOP(标准操作流程),进而我们用报表来进行统计。
除了故障的次数之外,MTTR(平均恢复时间)也是一个重要的指标。通过响应的 SOP,我们可以去分析某次故障的本身原因,是因为发现的时间较长,还是响应的时间较长,亦或排障的时间比较长。
通过落地的标准化流程,并且根据报表中的 MTTR,我们就可以分析出在发生故障之后,到底是哪个环节花费了较长的时间。
提到“故障频发”,我们认为所有的故障,包括组件上的故障和底层服务器的故障,都会最终反映到业务曲线之上。
因此我们 NOC 办公室有一个大屏幕来显示重要业务曲线,当曲线的走势发生异常的时候,我们就能及时响应通知到对应的人员。
在订单的高峰期,我们更讲求时效性。即发生了故障之后,我们要做的第一件事,或者说我们的目标是快速地止损,而不是去花时间定位问题。
这就是我们去实现多活的目的,而多活正是为我们的兜底工作进行“续命”。原来我只有一个机房,如果该机房的设施发生了故障,而正值业务高峰期的时候,后果是不堪设想的。
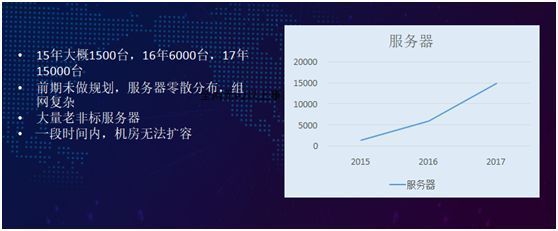
机房容量:我们再来看看整个机房的容量,在 2015 年之前,当时订单量很少,我们的服务器散落在机房里,机型也比较随意。
而到了 2015 年,我们大概有了 1500 台服务器;在 2016 年间,我们增长到了 6000 台;2017 年,我们则拥有将近 16000 台。这些还不包括在云上的 ECS 数量。
有过 IDC 相关工作经历的同学可能都知道:对于大型公司的交付,往往都是以模块签的合同。
但初期我们并不知道业务发展会这么快,服务器是和其他公司公用模块和机架,服务器也是老旧而且非标准化,同时组网的环境也非常复杂。甚至有一段时期,我们就算有钱去购买服务器,机房里也没有扩容的空间。
为什么要做多活
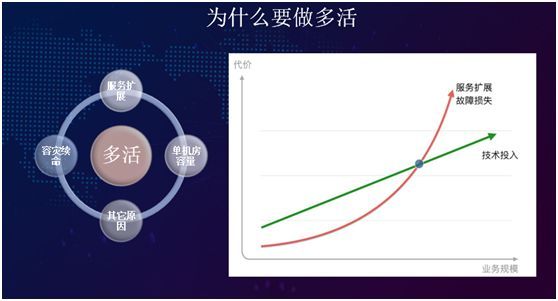
为什么要做多活,总结一下有四个方面:容灾续命、服务扩展、单机房容量、和其他的一些原因。
如上图右侧所示,我们通过一个类似 X/Y 轴的曲线进行评估。随着业务规模的增长,技术投入,服务扩展,故障损失已不是一种并行增长的关系了。
饿了么多活运维挑战
下面分享一下我们当时做了哪些运维的规划,主要分为五个部分:
- 多活技术架构
- IDC 规划
- SOA 服务改造
- 数据库改造
- 容灾保障
多活技术架构
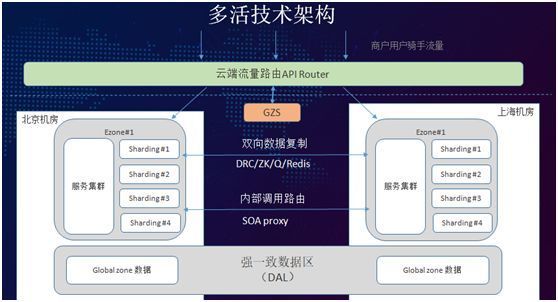
我们通过设置既可把昆山划分到上海,又可以划到苏州(这与行政区无关、仅关系到外卖的递送半径)。因此我们提出了地理围栏的概念,研发了 GZS 组件。
我们把全国省市在 GZS(globalzone service)服务上区分地理围栏,将全国分成了 32 个 Shard,来自每个 Shard 的请求进入系统之后,通过 GZS 判断请求应该路由到所属的机房。
如图最下方所示,对于一些有强一致性需求的数据要求,我们提出了 Global zone 的概念。属于 Global zone 的数据库,写操作仅限于在一个机房,读的操作可以在不同 zone 内的 local slave 上。
多活技术架构五大核心组件:
- API Router:流量入口 API Router,这是我们的第一个核心的组件,提供请求代理及路由功能。
- GZS:管理地理围栏数据及 Shard 分配规则。
- DRC:DRC(Data replication center)数据库跨机房同步工具,同时支持数据变更订阅,用于缓存同步。
- SOA proxy:多活非多活之间调用。
- DAL:原本是数据库中间件,为了防止数据被路由到错误的机房,造成数据不一致的情况,多活项目中配合做了一些改造。
整个多活技术架构的核心目标在于:始终保证在一个机房内完成整个订单的流程。
为了实现这个目标,研发了 5 大功能组件,还调研识别有着强一致性的数据需求,一起从整体上做了规划和改造。
IDC 规划
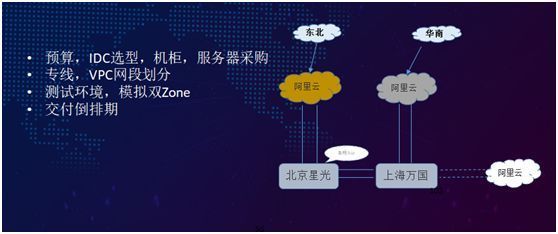
在 2016 年底启动多活项目,确定了南北两个机房,以及流量入口,开始进行 IDC 选型,实地考察了几家上海的 IDC 公司,最终选择了万国数据机房。同时结合做抗 100% 流量服务器预算、提交采购部门采购需求。
规划多活联调测试环境,模拟生产双 ezone、划分 vpc,以及最后的业务同期改造。
如上图右侧所示,以两处不同的流量为例,不同区域通过接入层进来的流量,分别对应北京和上海不同的机房,在正常情况下整个订单的流程也都会在本区域的机房被处理,同时在必要时能够相互分流。
SOA 服务改造
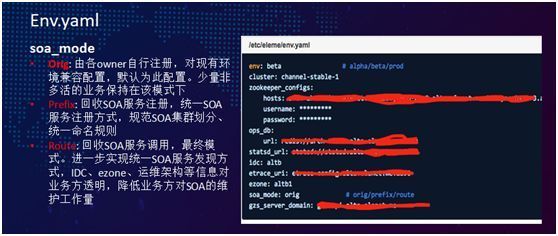
我们对 SOA 服务注册发现也做了一些改造工作。先说下多活以前是什么情况,某一个应用服务 AppId要上线,物理集群环境准备好,在 SOA 注册时对应了一个 SOA cluster 集群。
另外一些大的集群,对不同的业务调用划分不同的泳道,并将这些泳道在应用发布的时候,定义到不同的应用集群上,这就是整个 AppId部署的逻辑。
这对于单机房来说是很简单的,但是在双机房场景中,需要改造成同一个 AppId,只调用本机房的 SOA cluster,我们在甬道和分布集群的基础上引入了一个类似于单元的 ezone 概念。
SOA Mode 的改造方案,其中包括如下三种模式:
- Orig:兼容模式,默认的服务注册发现方式。
- Prefix:收回服务注册、统一 SOA 服务注册的方式。此模式主要针对的是我们许多新上线的多活应用。对于一些老的业务,默认还是沿用 Orig 模式。
- Route:这是回收 SOA 服务调用的最终模式,进一步实现了统一 SOA 的服务注册发现。整个 IDC、ezone、运维架构等信息对于业务方都是透明,从而降低了业务方对于 SOA 所产生的维护工作量。
数据库改造

按照前面对整个应用部署的划分,即多活、非多活以及强一致性的 Global zone,对数据库也进行了相应的规划。
我们先后进行了业务数据一致性的调研,复制一致性的规划,多活的集群改造成通过 DRC 来双向复制,Global zone 则采用原生的 Replication。
具体改造可分为三部分:
- 数据库集群改造,根据倒排期的时间点,分派专门的团队去跟进,将整个过程拆分出详细的操作计划。
- 数据库中间件 DAL 改造,增加校验功能,保证 SQL 不会写入错误的机房。实现了写入错误的数据保护,增加一道兜底防护。
- DRC 改造,多活两地实例间改造程 DRC 复制。
容灾保障

容灾保障,区分了三个不同的等级:
- 流量入口故障,常见的有 DNS 解析变更,网络出口故障,某省市骨干线路故障,以及 AR 故障。
- IDC 内故障,常见的有变更发布故障,历史 Bug 触发,错误配置,硬件故障,网络故障,容量问题等。
- 单机房完全不可用。目前尚未完全实现,但是我们如今正在进行断网演练。模拟某个机房里的所有 zone 都因为不可抗力宕掉了,也要保证该机房的所有应用能够被切换到另一个机房,继续保障服务可用。
当然这没能从根本上解决双机房同时发生故障的情况。当双机房同时发生问题时,目前还是要依赖于有经验的工程师,以及我们自动化的故障定位服务。
饿了么运营体系探索
在整个饿了么运维转型的过程中,我们如何将组织能力转型成为运营能力?下面是我们的五个思路:
- 应用发布
- 监控体系
- 预案和演练
- 容量规划
- 单机房成本分析
应用发布
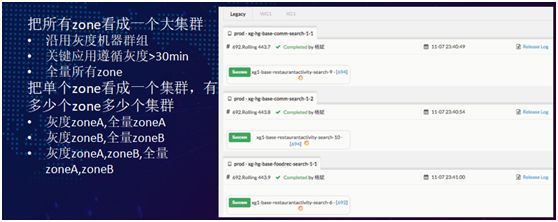
首先来看应用发布。在单机房的时候,我们一个 AppId 对应一个或多个 SOA cluster 集群,同时运维会配置灰度机器群组,并要求关键应用需要灰度 30 分钟。
那么在多活情况下,应用如何实现发布呢?我们在规划中采用了两种方式可选:
- 把所有 zone 看成一个大型的“集群”,沿用灰度机器群体的发布策略。我们先在单个机房里做一次灰度,然后延伸到所有的 zone,保证每个关键应用都遵循灰度大于 30 分钟的规则,最后再全量到所有的 zone 上。
- 把单个 zone 看成一个“集群”,有多少个 zone 就有多少个“集群”。首先灰度 zoneA、并全量 zoneA,然后灰度 zoneB、并全量 zoneB。 或者您也可以先灰度 zoneA、并灰度 zoneB,然后同时观察、并验证发布的状态,最后再全量 zoneA、并全量 zoneB。您可以根据自身情况自行选择和实现。
监控体系
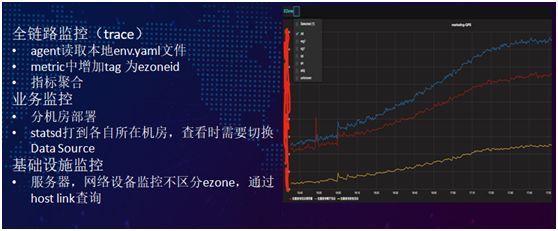
饿了么目前有三大监控体系:
- 全链路监控。在 Agent 启动时读取一个文件,以获知当前处于哪个 zone,然后会在 metric 中为 ezoneid 增加一个 tag,并且进行指标聚合。默认在一个机房里可有多个 zone。
- 业务监控。进行分机房的部署,将 statsd 打到各自所在机房,而在查看时则需要切换 Data Source。
- 基础设施监控。而对于服务器、网络设备监控则不必区分 ezone,通过 host link 来进行查询。
预案和演练

对于常见的故障做了预案,制定常规演练计划,并且定期演练。目前我们也正在做一套演练编排系统,上线之后应该会有更好的效果。
容量规划
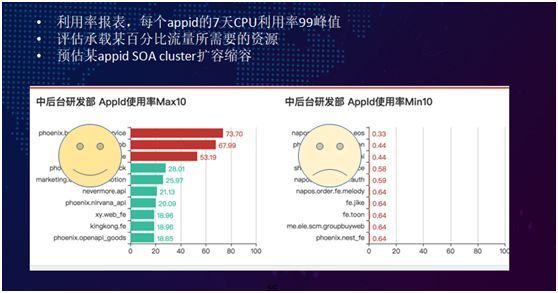
至于容量规划(Capacity planning),我们目前只是采集到 AppId 的服务器 CPU 利用率。
结合现有两地机房的常态化负载应该是:北京的 zone 承载 52% 的流量;而上海机房分摊 48%。
常规情况每周三会进行全链路压力测试。通过评估,我们能获知整个关键路径的容量。
未来我们也会假设倘若再增加了 15% 的流量,那么在现有的 AppId 基础上,我们还需要增加的服务器台数。
同时,在承载了现有订单数量的基础上,我们要估算现有的单个 SOA cluster 所能承载的订单请求极限。
如上图所示,通过获取 AppId 利用率统计列表,我们能够发现:由于前期业务的爆炸式增长,我们在不计成本的情况下所购置的服务器机,其利用率实际上是比较低下的。
单机房成本分析
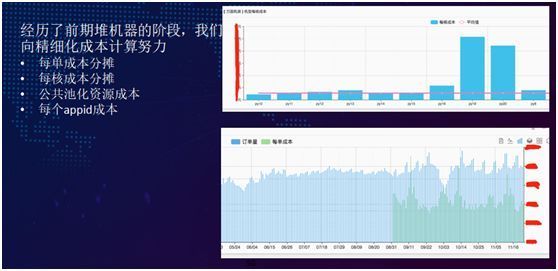
对于现有 IDC 成本核算,是按照一定的折旧标准将它们分摊到每个月,并与业务上单月的总体完成订单量进行对比,最终计算出每笔订单的 IT 成本,以及计算出每核成本。
另外,我们还可以与租用云服务的成本相比较,从而得出成本优劣。
对于一些公共池化资源,把池化的各种组件服务分摊到各个部门和每个 AppId 之上。
这样就能指导每个 AppId 使用了多少台服务器,IT 成本是多少,我们便可以进一步开展成本分析。