Structured Streaming + Kafka 统计模型(输入kafka,输出console)
环境
本次使用全部以单机环境运行,下面附上spark和kafka的主要配置。
spark
版本:spark-2.4.4-bin-hadoop2.7.tgz (https://www.apache.org/dyn/closer.lua/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz)
spark-env.sh
SPARK_LOCAL_IP=192.168.33.50
SPARK_MASTER_HOST=192.168.33.50
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1G
启动服务
$ ./sbin/start-all.sh
kafka
版本:kafka_2.11-2.3.0.tgz (https://www.apache.org/dyn/closer.cgi?path=/kafka/2.3.0/kafka_2.11-2.3.0.tgz)
server.properties
listeners=PLAINTEXT://192.168.33.50:9092
启动服务
$ ./bin/zookeeper-server-start.sh config/zookeeper.properties &
$ ./bin/kafka-server-start.sh config/server.properties &
# topic相关
$ ./bin/kafka-topics.sh --list --zookeeper localhost:2181
$ ./bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
$ ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.33.50:9092 --topic test
spark streaming + kafka
spark-sql-kafka-0-10_2.11:2.4.4 ===> 2.11代表scala版本,2.4.4代表spark版本
Kafka脚本 发送字符串数据
kf_producer1.py
from kafka import KafkaProducer
import time
producer = KafkaProducer(bootstrap_servers='192.168.33.50:9092')
topic = 'test'
i = 0
while True:
i += 1
msg = "my kafka {}".format(i)
producer.send(topic, msg.encode())
print('producer - {0}'.format(msg))
time.sleep(8)
流计算 处理字符串数据
对发送的kafka字符串数据进行统计计算。
sp_test6_1.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split
spark = SparkSession.builder.master(
"spark://192.168.33.50:7077"
).getOrCreate()
stream_data = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "192.168.33.50:9092") \
.option("subscribe", "test") \
.load()
stream_data.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
stream_data.printSchema()
word_df = stream_data.select(
explode(split(stream_data.value, " ")).alias('word')
)
word_df.printSchema()
wordCounts = word_df.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.trigger(processingTime='10 seconds') \
.outputMode("complete") \
.format("console") \
.start() \
.awaitTermination()
运行
$ python3 kf_producer1.py
$ ./bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.4 /test/sp_test6_1.py
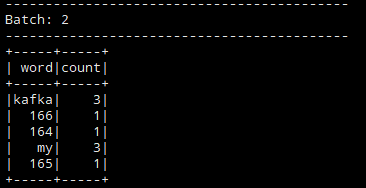
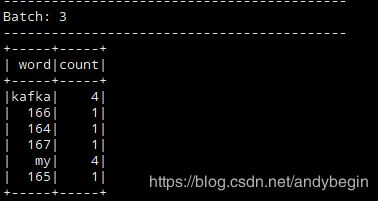
会不断输出

Kafka脚本 发生json数据
kf_producer2.py
from kafka import KafkaProducer
import time
import json
producer = KafkaProducer(bootstrap_servers='192.168.33.50:9092')
topic = 'test'
i = 0
while True:
i += 1
json_data = {
"msg": "my kafka {}".format(i),
"count": i
}
post_data = json.dumps(json_data).encode()
producer.send(topic, post_data)
print('producer - {0}'.format(post_data))
time.sleep(8)
流计算 处理json数据
对发送的kafka json数据进行统计计算。
sp_test6_2.py
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode, split, from_json
from pyspark.sql.types import StructType, IntegerType, StringType
spark = SparkSession.builder.master(
"spark://192.168.33.50:7077"
).getOrCreate()
stream_data = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "192.168.33.50:9092") \
.option("subscribe", "test") \
.load()
stream_data.printSchema()
# kafka json数据解析
data_schema = StructType().add("msg", StringType()).add("count", IntegerType())
new_stream_data = stream_data.select(
stream_data.key.cast("string"),
from_json(stream_data.value.cast("string"), data_schema).alias('json_data')
)
new_stream_data.printSchema()
# msg按空格分隔
word_df = new_stream_data.select(
explode(split(new_stream_data.json_data.msg, " ")).alias('word')
)
word_df.printSchema()
# 聚合
wordCounts = word_df.groupBy("word").count()
# Start running the query that prints the running counts to the console
query = wordCounts \
.writeStream \
.trigger(processingTime='10 seconds') \
.outputMode("complete") \
.format("console") \
.start() \
.awaitTermination()
运行
$ python3 kf_producer2.py
$ ./bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.4 /test/sp_test6_2.py
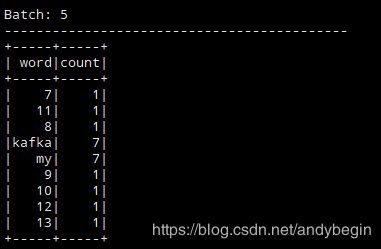
输出