机器学习(十三)——机器学习中的矩阵方法(3)病态矩阵、协同过滤的ALS算法(1)
http://antkillerfarm.github.io/
向量的范数(续)
范数可用符号 ∥x∥λ 表示。常用的有:
这里不做解释的给出如下示意图:

其中,0范数表示向量中非0元素的个数。上图中的图形被称为 lp ball。表征在同一范数条件下,具有相同距离的点的集合。
范数满足如下不等式:
向量范数推广可得到矩阵范数。某些矩阵范数满足如下公式:
这种范数被称为相容范数。
注:矩阵范数要比向量范数复杂的多,还包含一些不可以由向量范数来诱导的范数,如Frobenius范数。而且只有极少数矩阵范数,可由简单表达式来表达。这里篇幅有限,不再赘述。
病态矩阵
现在有线性系统 Ax=b :
很容易得到解为:
则得到一个截然不同的解: x1=40000,x2=79800 。
当解集x对A和b的系数高度敏感,那么这样的方程组就是病态的 (ill-conditioned/ill-posed)。
从上例的情况来看,矩阵的行向量 [400−201] 和 [−800401] 实际上是过于线性相关了,从而导致矩阵已经接近奇异矩阵(near singular matrix)。
病态矩阵实际上就是奇异矩阵和近奇异矩阵的另一个说法。
参见:
http://www.cnblogs.com/daniel-D/p/3219802.html
矩阵的条件数
我们首先假设向量b受到扰动,导致解集x产生偏差,即:
也就是:
因此,由矩阵相容性可得:
同时,由于:
所以:
即:
我们定义矩阵的条件数
同样的,我们针对A的扰动,所导致的x的偏差,也可得到类似的结论:
可见,矩阵的条件数是描述输入扰动对输出结果影响的量度。显然,条件数越大,矩阵越病态。
然而这个定义,在病态矩阵的条件下,并不能直接用于数值计算。因为浮点数所引入的微小的量化误差,也会导致求逆结果的很大误差。所以通常情况下,一般使用矩阵的特征值或奇异值来计算条件数。
假设A是2阶方阵,它有两个单位特征向量 x1,x2 和相应的特征值 λ1,λ2 。
由之前的讨论可知, x1,x2 是相互正交的。因此,向量b能够被 x1,x2 的线性组合所表示,即:
从这里可以看出,b在 x1,x2 上的扰动,所带来的影响,和特征值 λ1,λ2 有很密切的关系。奇异值实际上也有类似的特点。
因此,一般情况下,条件数也可以由最大奇异值与最小奇异值之间的比值,或者最大特征值和最小特征值之间的比值来表示。这里的最大和最小,都是针对绝对值而言的。
参见:
https://en.wikipedia.org/wiki/Condition_number
矩阵规则化
病态矩阵处理方法有很多,这里只介绍矩阵规则化(regularization)方法。
机器学习领域,经常用到各种损失函数(loss function),也称花费函数(cost function)。这里我们用:
表示损失函数。
当样本数远小于特征向量维数时,损失函数所表示的矩阵是一个稀疏矩阵,而且往往还是一个病态矩阵。这时,就需要引入规则化因子用以改善损失函数的稳定性:
其中的 λ 表示规则化因子的权重。
注:稀疏矩阵并不一定是病态矩阵,比如单位阵就不是病态的。但是从系统论的角度,高维空间中样本量的稀疏,的确会带来很大的不确定性。
函数V(又叫做Fit measure)和R(又叫做Entropy measure),在不同的算法中,有不同的取值。
比如,在Ridge regression问题中:
Ridge regression问题中规则化方法,又被称为 L2 regularization,或Tikhonov regularization。
注:Andrey Nikolayevich Tikhonov,1906~1993,苏联数学家和地球物理学家。大地电磁学的发明人之一。苏联科学院院士。著有《Solutions of Ill-posed problems》一书。
更多的V和R取值参见:
https://en.wikipedia.org/wiki/Regularization_(mathematics)
从形式上来看,对比之前提到的拉格朗日函数,我们可以发现规则化因子,实际上就是给损失函数增加了一个约束条件。它的好处是增加了解向量的稳定度,缺点是增加了数值解和真实解之间的误差。
为了更便于理解规则化,这里以二维向量空间为例,给出了规则化因子对损失函数的约束效应。
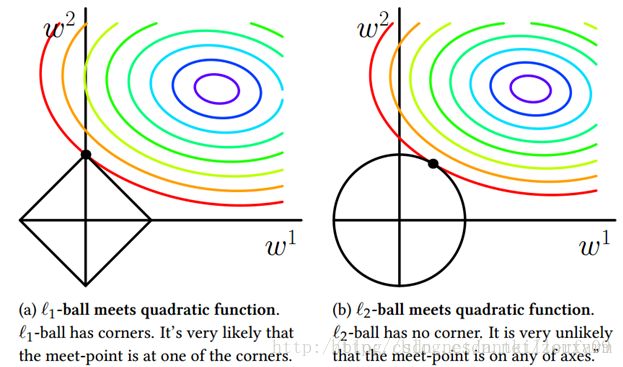
上图中的圆圈是损失函数的等高线,坐标原点是规则化因子的约束中心,左图的方形和右图的圆形是 lp ball。图中的黑点是等高线和 lp ball的焦点,实际上也就是这个带约束的优化问题的解。
可以看出 L1 regularization的解一般出现在坐标轴上,因而其他坐标上的值就是0,因此, L1 regularization会导致矩阵的稀疏。
参见:
https://en.wikipedia.org/wiki/Tikhonov_regularization
http://www.mit.edu/~cuongng/Site/Publication_files/Tikhonov06.pdf
http://blog.csdn.net/zouxy09/article/details/24971995
协同过滤的ALS算法
协同过滤概述
注:最近研究商品推荐系统的算法,因此,Andrew Ng讲义的内容,后续再写。
协同过滤是目前很多电商、社交网站的用户推荐系统的算法基础,也是目前工业界应用最广泛的机器学习领域。
协同过滤是利用集体智慧的一个典型方法。要理解什么是协同过滤 (Collaborative Filtering,简称CF),首先想一个简单的问题,如果你现在想看个电影,但你不知道具体看哪部,你会怎么做?大部分的人会问问周围的朋友,看看最近有什么好看的电影推荐,而我们一般更倾向于从口味比较类似的朋友那里得到推荐。这就是协同过滤的核心思想。
如何找到相似的用户和物品呢?其实就是计算用户间以及物品间的相似度。以下是几种计算相似度的方法:
欧氏距离
Cosine相似度
皮尔逊相关系数(Pearson product-moment correlation coefficient,PPMCC or PCC):
该系数由Karl Pearson发明。参见《机器学习(二)》中对Karl Pearson的简介。Fisher对该系数也有研究和贡献。
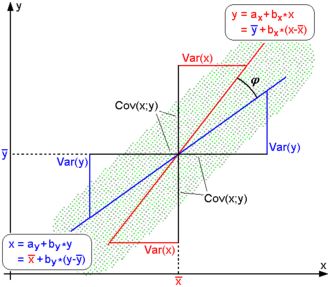
如上图所示,Cosine相似度计算的是两个样本点和坐标原点之间的直线的夹角,而PCC计算的是两个样本点和数学期望点之间的直线的夹角。
PCC能够有效解决,在协同过滤数据集中,不同用户评分尺度不一的问题。
参见:
https://en.wikipedia.org/wiki/Pearson_product-moment_correlation_coefficient
Spearman秩相关系数(Spearman’s rank correlation coefficient)
对秩变量(ranked variables)套用PCC公式,即可得Spearman秩相关系数。
秩变量是一类不在乎值的具体大小,而只关心值的大小关系的统计量。
| Xi | Yi | xi | yi | di | d2i |
|---|---|---|---|---|---|
| 86 | 0 | 1 | 1 | 0 | 0 |
| 97 | 20 | 2 | 6 | −4 | 16 |
| 99 | 28 | 3 | 8 | −5 | 25 |
| 100 | 27 | 4 | 7 | −3 | 9 |
| 101 | 50 | 5 | 10 | −5 | 25 |
| 103 | 29 | 6 | 9 | −3 | 9 |
| 106 | 7 | 7 | 3 | 4 | 16 |
| 110 | 17 | 8 | 5 | 3 | 9 |
| 112 | 6 | 9 | 2 | 7 | 49 |
| 113 | 12 | 10 | 4 | 6 | 36 |
如上表所示, Xi 和 Yi 是原始的变量值, xi 和 yi 是rank之后的值, di=xi−yi 。
当 Xi 和 Yi 没有重复值的时候,也可用如下公式计算相关系数:
注:Charles Spearman,1863~1945,英国心理学家。这个人的经历比较独特,20岁从军,15年之后退役。然后,进入德国莱比锡大学读博,中间又被军队征召,参加了第二次布尔战争,因此,直到1906年才拿到博士学位。伦敦大学学院心理学教授。
尽管他的学历和教职,都是心理学方面的。但他最大的贡献,却是在统计学领域。他也是因为在统计学方面的成就,得以当选皇家学会会员。
话说那个时代的统计学大牛,除了Fisher之外,基本都是副业比主业强。只有Fisher,主业方面也是那么牛逼,不服不行啊。
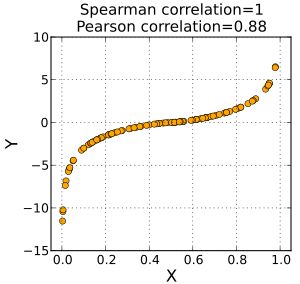
由上图可见,Pearson系数关注的是两个变量之间的线性相关度,而Spearman系数可以应用到非线性或者难以量化的领域。
参见:
https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient