SpringBoot2集成Druid配置多数据数据源及SQL监控
记录一下近期练习搭建项目Spingboot集成druid配置多数据源过程,本人也是小白,我会尽量描述的详细,希望能帮助到你,也为自己之后温习做下准备。
1.开发环境
IntelliJ IDEA 2018.3.6 x64
jdk1.8
mysql 5.7
2.项目目录结构
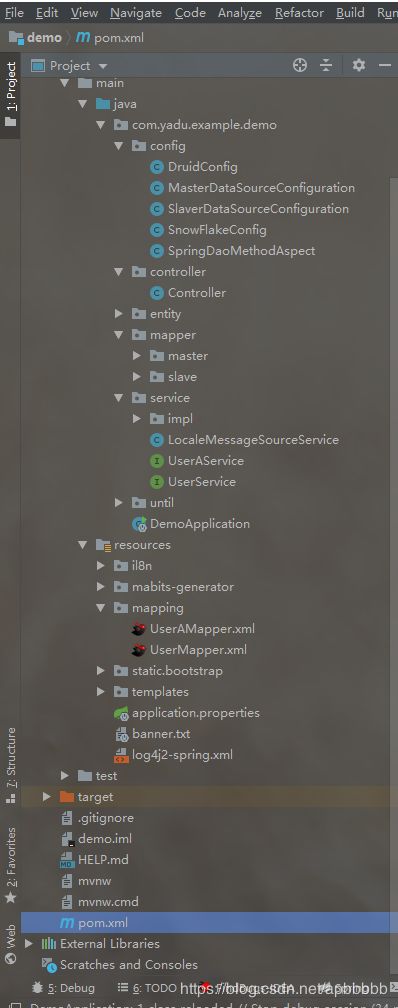
3.导入jar包
org.slf4j
jcl-over-slf4j
org.projectlombok
lombok
1.16.10
com.alibaba
fastjson
1.2.59
com.alibaba
druid
1.1.19
com.github.pagehelper
pagehelper
4.0.0
junit
junit
4.12
org.aspectj
aspectjrt
1.9.1
org.aspectj
aspectjweaver
1.9.1
4.application.properties配置多个jdbc链接
我这里没有使用yml,其实都是差不多,yml复制粘贴名称不太方便
################## JDBC 配置 ################
#数据库一配置
spring.datasource.druid.master.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.druid.master.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.druid.master.url=jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC
spring.datasource.druid.master.username=root
spring.datasource.druid.master.password=123456
########################## druid配置 ##########################
# 下面为连接池的补充设置,应用到上面所有数据源中# 初始化大小,最小,最大
################## 连接池配置 ################
#连接池建立时创建的初始化连接数
spring.datasource.druid.master.initial-size=5
#连接池中最大的活跃连接数
spring.datasource.druid.master.max-active=20
#连接池中最小的活跃连接数
spring.datasource.druid.master.min-idle=5
# 配置获取连接等待超时的时间
spring.datasource.druid.master.max-wait=60000
# 打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.druid.master.pool-prepared-statements=true
spring.datasource.druid.master.max-pool-prepared-statement-per-connection-size=20
#spring.datasource.druid.max-open-prepared-statements= #和上面的等价
spring.datasource.druid.master.validation-query=SELECT 1 FROM DUAL
spring.datasource.druid.master.validation-query-timeout=30000
#是否在获得连接后检测其可用性
spring.datasource.druid.master.test-on-borrow=false
#是否在连接放回连接池后检测其可用性
spring.datasource.druid.master.test-on-return=false
#是否在连接空闲一段时间后检测其可用性
spring.datasource.druid.master.test-while-idle=true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙,log4j2为你自己使用的日志,如果是log4j就写log4j,我这里用的log4j2
spring.datasource.druid.master.filters=stat,wall,log4j2
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.druid.master.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
#spring.datasource.druid.master.useGlobalDataSourceStat=true
#数据库二配置
spring.datasource.druid.slave.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.druid.slave.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.druid.slave.url=jdbc:mysql://10.0.0.1:3306/mysql3235?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=UTC //根据自己需要修改第二个jdbc链接
spring.datasource.druid.slave.username=root
spring.datasource.druid.slave.password=121111
########################## druid配置 ##########################
# 下面为连接池的补充设置,应用到上面所有数据源中# 初始化大小,最小,最大
################## 连接池配置 ################
#连接池建立时创建的初始化连接数
spring.datasource.druid.slave.initial-size=5
#连接池中最大的活跃连接数
spring.datasource.druid.slave.max-active=20
#连接池中最小的活跃连接数
spring.datasource.druid.slave.min-idle=5
# 配置获取连接等待超时的时间
spring.datasource.druid.slave.max-wait=60000
# 打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.druid.slave.pool-prepared-statements=true
spring.datasource.druid.slave.max-pool-prepared-statement-per-connection-size=20
#spring.datasource.druid.max-open-prepared-statements= #和上面的等价
spring.datasource.druid.slave.validation-query=SELECT 1 FROM DUAL
spring.datasource.druid.slave.validation-query-timeout=30000
#是否在获得连接后检测其可用性
spring.datasource.druid.slave.test-on-borrow=false
#是否在连接放回连接池后检测其可用性
spring.datasource.druid.slave.test-on-return=false
#是否在连接空闲一段时间后检测其可用性
spring.datasource.druid.slave.test-while-idle=true
# 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙
spring.datasource.druid.slave.filters=stat,wall,log4j2
# 通过connectProperties属性来打开mergeSql功能;慢SQL记录
spring.datasource.druid.slave.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
# 合并多个DruidDataSource的监控数据
#spring.datasource.druid.slave.useGlobalDataSourceStat=true5.druid 配置(基于java版)
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
/**
* 配置Druid监控
* 后台管理Servlet
* @return
*/
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
Map initParams = new HashMap<>();//这是配置的druid监控的登录密码
initParams.put("loginUsername","admin");
initParams.put("loginPassword","admin");
//默认就是允许所有访问
initParams.put("allow","");
//黑名单的IP
initParams.put("deny","192.168.15.21");
bean.setInitParameters(initParams);
return bean;
}
/**
* 配置web监控的filter
* @return
*/
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean = new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
Map initParams = new HashMap<>();
initParams.put("exclusions","/static/*,*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");//过滤掉需要监控的文件
bean.setInitParameters(initParams);
bean.setUrlPatterns(Arrays.asList("/*"));
return bean;
}
}
6.绑定数据源(有几个数据源就需要写几个java文件)
mport com.alibaba.druid.pool.DruidDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
@Configuration
@MapperScan(basePackages = "com.yadu.example.demo.mapper.master", sqlSessionTemplateRef = "masterSqlSessionTemplate")
public class MasterDataSourceConfiguration {
@Bean(name = "masterDataSource")
@Primary //配置默认数据源
@ConfigurationProperties(prefix = "spring.datasource.druid.master")
public DataSource dataSource() {
return new DruidDataSource();
}
@Bean(name = "masterSqlSessionFactory")
public SqlSessionFactory sqlSessionFactory(@Qualifier("masterDataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapping/*.xml"));
return bean.getObject();
}
@Bean(name = "masterTransactionManager")
public DataSourceTransactionManager transactionManager(@Qualifier("masterDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "masterSqlSessionTemplate")
public SqlSessionTemplate sqlSessionTemplate(@Qualifier("masterSqlSessionFactory") SqlSessionFactory sqlSessionFactory)
throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}import com.alibaba.druid.pool.DruidDataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import javax.sql.DataSource;
@Configuration
@MapperScan(basePackages = "com.yadu.example.demo.mapper.slave", sqlSessionTemplateRef = "slaveSqlSessionTemplate")
public class SlaverDataSourceConfiguration {
@Bean(name = "slaveDataSource")
@ConfigurationProperties(prefix = "spring.datasource.druid.slave")
public DataSource dataSource() {
return new DruidDataSource();
}
@Bean(name = "slaveSqlSessionFactory")
@Primary
public SqlSessionFactory sqlSessionFactory(@Qualifier("slaveDataSource") DataSource dataSource) throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapping/*.xml"));
return bean.getObject();
}
@Bean(name = "slaveTransactionManager")
@Primary
public DataSourceTransactionManager transactionManager(@Qualifier("slaveDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean(name = "slaveSqlSessionTemplate")
@Primary
public SqlSessionTemplate sqlSessionTemplate(@Qualifier("slaveSqlSessionFactory") SqlSessionFactory sqlSessionFactory)
throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
7.配置spring监控(如果你访问方法之后spring监控没有数据)

import com.alibaba.druid.support.spring.stat.DruidStatInterceptor;
import org.springframework.aop.support.DefaultPointcutAdvisor;
import org.springframework.aop.support.JdkRegexpMethodPointcut;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Scope;
/**
* spring监控配置
* @author
*/
@Configuration
public class SpringDaoMethodAspect {
@Bean
public DruidStatInterceptor druidStatInterceptor() {
DruidStatInterceptor dsInterceptor = new DruidStatInterceptor();
return dsInterceptor;
}
@Bean
@Scope("prototype")
public JdkRegexpMethodPointcut druidStatPointcut() {
JdkRegexpMethodPointcut pointcut = new JdkRegexpMethodPointcut();
pointcut.setPattern("com.yadu.example.demo.mapper.*");
return pointcut;
}
@Bean
public DefaultPointcutAdvisor druidStatAdvisor(DruidStatInterceptor druidStatInterceptor, JdkRegexpMethodPointcut druidStatPointcut) {
DefaultPointcutAdvisor defaultPointAdvisor = new DefaultPointcutAdvisor();
defaultPointAdvisor.setPointcut(druidStatPointcut);
defaultPointAdvisor.setAdvice(druidStatInterceptor);
return defaultPointAdvisor;
}
}8.springboot启动类
注意看下注解,这点容易出错,一开始我加了@MapperScan和@ComponentScan,导致tomcat启动中断,也不报错,然后我还在main方法里面加了try catch,错误信息才出来,是这两个注解引起了,导致我一个包扫描了两次,我网上查了资料,可以同时使用,咱也不知道为啥出错。。。
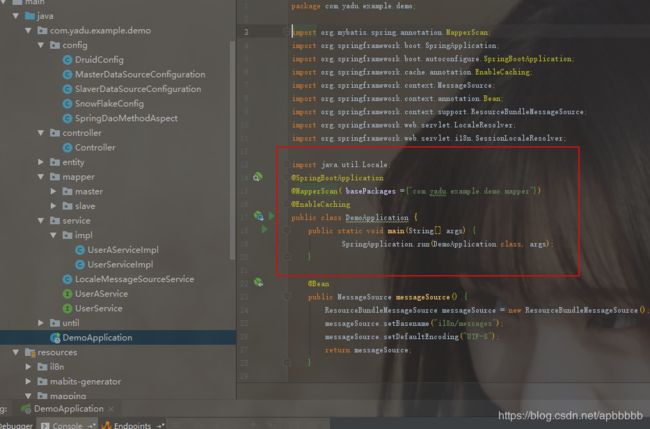
9.编写方法,验证效果
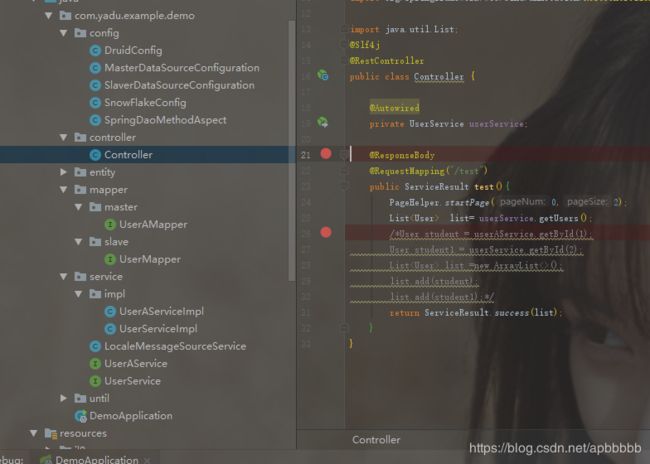
http://localhost:8079/test 端口号我这里在application.properties 中修改了,改成你对应的端口号就好

sql监控访问
http://localhost:8079/druid/index.html


10.作为补充
访问sql监控的时候,你可能会看到阿里巴巴的广告,如果想去掉,有两种方式
1.修改druid中的js源码,可参考
https://blog.csdn.net/haveqing/article/details/86524672
2.增加配置文件
https://blog.csdn.net/qq_33229669/article/details/87459781
亲测两种方式都可以,我使用的是第一种,从根源解决
如果你第一次使用,可能会遇到各种各样问题,可以留言一起研究
使用心得,其实搭建完我才知道,springboot2有自己默认的连接池HikariCP,具体链接可参考https://www.jianshu.com/p/7e4c0e9ad49a,哪个比较好,请根据自己项目选择