论文笔记:Two-level attention model for fine-grained Image classification
The Application of Two-level Attention Models in Deep Convolutional Neural Network for Fine-grained Image Classification(细粒度图像识别)
原文链接:paper
我先来总结一下这篇文章主要的思路:
主要就是利用region proposal,寻找对于最后分类结果有积极影响的proposal,去掉那些无用的噪声。论文提到了两个filter proposal的方法。第一个 利用image-level训练好的model,和设定的阈值,直接对selective search产生的proposal,进行第一次去燥,主要目的得到高查全率,准确率可以不高。第二次filter,就是利用第一次filter之后的数据重新训练网络,提取网络第四层卷积的特征,对其聚类,根据这个从第一次filter之后的proposal里面选择3个对于分类最有影响力的part-level proposal,最后利用SVM分类。
感觉整个过程就是想方设法,找到对结果最有影响力proposal,然后训练分类器,结果就不错。文章想法很不错,进行聚类。最值得表扬的是,不仅思路新,而且文章有理有据,把整个过程说的很明白,这点很欣赏。希望自己以后也能写出正常人都能看懂的paper。
摘要
fine-grained分类由于类别之间只有通过细微局部的差异才能够被区分出来,因此很有挑战性。位置,大小或者旋转都会使问题变得更加困难。很多这类问题的解决思路是where(object)和what(feature)式的。
这篇文章将视觉attention应用到fine-grained分类问题中使用DNN。我们整合了3中attention模型:bottom-up(提供候选者patch),object-level top-down(certain object相关patch),和part-level top-down (定位具有分辨能力的parts)。我们把这几个attentions结合起来训练domain-specific深度网络。不适用bounding box标注。利用了弱监督学习的知识来实现。
引言
fine-gained分类是在基础类别下的次分类问题,比如分类不同类型的鸟,狗,花的类别。正是一个具有广泛应用价值的重要问题。类间差异要比类内差异小很多,所以fine-gained分类是一个技术上的挑战问题。
特别的,fine-gained分类的困难来源于discriminal特征不仅仅是前景中的物体了,更加应该具有判别力的信息应该是物体的部分信息,比如说鸟的头部。因此很多fine-gained分类任务的方法一般都是:找到具有判别力的区域(物体本身或者物体的一部分)。
因此一个从底向上(bottom-up)的过程是不可避免的,我们需要提出很多图像区域作为物体候选者,或者这些区域包含那些具有判别力的部分。(这个相当于proposal regions,类似SIFT,selective search产生的候选者),这篇文章也利用selective research作为region提取器。
这个自底向上的霍城需要很高的召回率,准确率可以不用很高。(事实上,准确率相当低,因此好需要后续处理,只要召回率高,就说明物体在其中,在进行更为详细的方法,把它找到,从而提高准确率)。如果object很小,那么大多数的patches都是背景,对于分类物体一点用都没有,这就引出了top-down的方法来过滤掉这些噪声patches,选择出相关性比较高的patches。在fine-grained分类领域,找到前景物体和物体的部分被认为是两个过程,一个是object-level,一个是part-lecel。
许多已经存在的方法依赖强监督学习来解决attention问题。这就对人类标注产生了很大的依赖,比如使用bounding box或者landmarks。我们没有使用任何其中的核外标注。
由于标注很昂贵,并且不可伸缩,这个研究需要使用最弱监督来实现。
本片问孩子那个提出两个思路来解决这个问题,一个是object-level,一个是part-level。
这里是一个方法抽象总结:
- 把一个在ILSVRC2012上面预训练过的CNN转变成一个filterNet。FilterNet可以选择跟基准类别很相近的patches,因此可以处理object-level attention。这个选择到的patches用来训练另外一个CNN,训练成一个domain分类器,称DomainNet。
- 我们观察到了在DomainNet中隐藏的聚类模式,神经网络节点存在很高的敏感性对于具备判别力的部分。因此我们选择滤波器作为part-detector来实施part-level的实验。
在以上实验过程中,仅使用image-level 标注。
下一个部分就是提取具备判别力的特征,从整两个attention model里面选中的regions/patches中提取这些有判别力的特征。最近,很多论文传达出一种信息,就是从CNN中提取到的特征,比手工提取特征实验结果要好很多。
在object-level,DomainNet直接输出了多视角(multi-view)的预测根据一张图片中几个相关的patches。在part-level,CNN隐层中的激活函数是由检测到的区域产生另外的一个预测结果通过一个基于part-based的分类器 驱动的。最后的结果合并了这两种方法,结合了他们的优势。
我们初步实验结果证明了设计的有效性。使用最弱监督,我们提高了狗和鸟的分类效果的错误率从40.1%和21.1%降到了28.1%和11%。在CUB2002011数据集上,准确率达到了69.7%,如果使用VGGNet正确率能接近78%。
方法
我们的设计来自于一个非常简单的直觉:实现细粒度图像分类需要先看到物体,然后看到它最具有判别力的部分。从一张图片中找到吉娃娃(狗类型之一),需要先看到一只狗,然后根据具体的特征来判断是哪种类型的狗。
通过bottom-up生成候选patches,使用了selctive research方法。这个步骤会提供多尺度,多视角的原始图像。Top-dowm过程需要来实现,为了提取有效的有用的分类patches(FilterNet,过滤掉无用背景信息)。(由于bottom-up的高召回率和低正确率)
2.1 物体层面的 attention model

- patch selection using object-level attention
直接利用在目标数据集上预训练好的CNN模型作为filter。我们利用具体类别的父类别来作为判断依据,比如吉娃娃,是狗所以留下。根据是不是狗来判断要不要留下patches。这里会生成一个score表,我们设定一个阈值来决定是否要选择patches。通过这方法,多视角,多维度的特征得以保留,并且有效去除噪声。 - Training a DomainNet
用FilterNet选择出来的patches被用来训练新的CNN。
我们从一张图像中提取出很多的patch,相当于做的data augmentation,类似随机裁剪,但是我们的patch具有更高的confidence。有两个好处:1.DomainNet是一个号的细粒度的图像分类器;2. 它生成的内部特征允许我们构建部分检测器。 - Classification using object-level attention
在test阶段,也可以用上面的方法来提取confidence比较高的patches。为了预测test数据的label,我们把刚才生成的selected patches输入DomainNet进行前向计算,然后计算softmax输出分类分布的所有patches的均值。最后我们根据这个均值得到最后的预测结果。
这个方法包含一个超参数:confidence的阈值。这个会影响selected patches的质量和数量。在实验中,设置此值维0.9,因为这个数值能够提供最好的val准确率还有test时的表现。
2.2 部分层面上的attention model
Building the part detector
DPD和Part-RCNN研究表明特定的有判别力的局部特征对于细粒度的图片分类很有用。由于DomainNet的隐层包含了很多的特征信息,比如所有的神经网络节点能够反映鸟的头部特征,其他的反映身体特征。这些特征确实能够代表或者说为他们的类别站台。

看上图,这张图应该是论文的精髓了。我们对相似度矩阵S聚类成k类, S(i,j) 代表对于中间层滤波器 Fi 和 Fj (DomainNet中)的余弦值。在我们实验中,网络跟AlexNet是一样的,选择第四个卷集成聚类成3类,每个聚类看作是一个部分检测器。
当使用聚类滤波器来检测region proposal 中的parts时,步骤为:1. resize输入图片大小;2. 前向传递一次,生成每个filter的激活分数;3. 把同一类别的filter的激活分数相加;4. 对于每一聚类,选择生成score最高的patch,把这个patch当做part patch。每张图应该是有聚类个数3个part patch。(就相当于另外一次对原始selective search产生的region proposal进行删选,这次一张图片只保留3个最有影响力的patch,用来训练SVM分类器)Building the part-based classifier
经过part detector选择的patches,再次进入DomainNet来生成激活分数,我们把不同parts的激活分数连接起来,还有原始image,来训练SVM part-based分类器。
本方法包含几个超参数,比如检测滤波器层:第四层卷积;聚类别数:3.这些都是根据实验结果来断定的。这些东西可以根据不同的数据集做不同的修改。
2.3 完整过程
object-level和part-level方法各有千秋。他们的功能和优势是不同的,主要是因为他们的接受的patch不同。1.使用selective serch产生的patches,这些patch驱动了DomainNet。另一方面,part-level分类器专门对那些包含有判别力的局部特征进行处理。尽管有的patch被两个分类器同时使用,他们代表不同的特征,因此能够潜在的互补。最后我们利用下面的公式将两个模型的结果结合在一起。
finalscore=objectscore+α∗partscore(1)
object_score是一张图片多个patch的均值,part_score是是SVM产生的决策值。 α 使用验证的方法来确定,在实验中,我们设置其维0.5
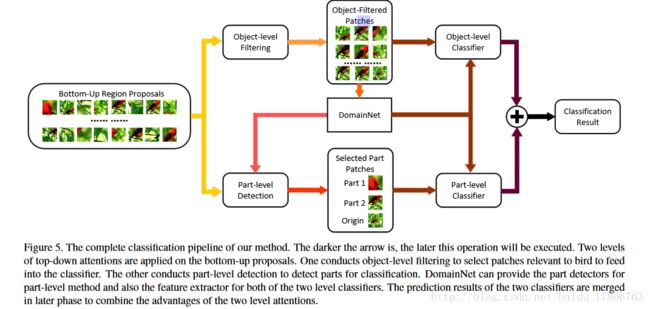
上图是整个实验流程框架。
EMMA
SIAT
2017.04.17