python-Scrapy爬取unsplash美图(壁纸)
环境: Scrapy1.5.1, Python3.6
一. 分析网站
1. 高清图片网站https://unsplash.com/, 能展示超过7w+张高清图片. 浏览时, 其通过API返回图片的URl
2. 在chrome浏览器中有此插件unsplash, 在插件文件中找到对应JS, 再找出api地址
根据插件安装的时间找到对应的chrome插件目录
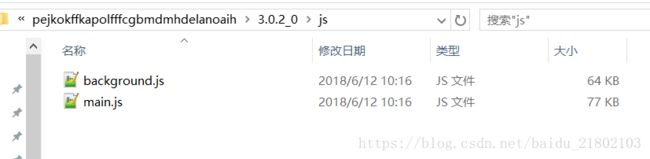
找到对应JS
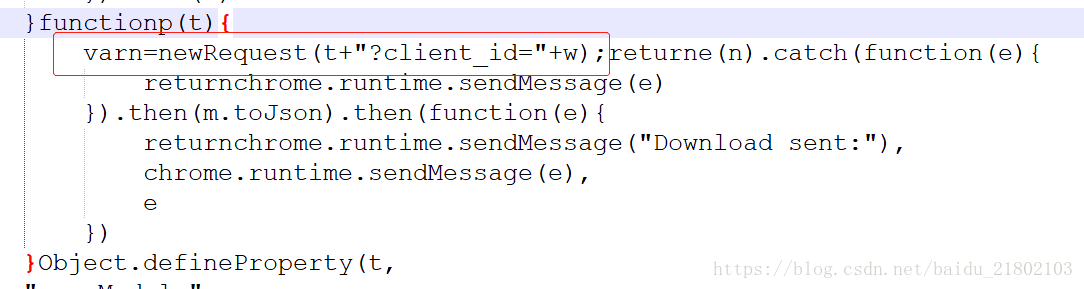
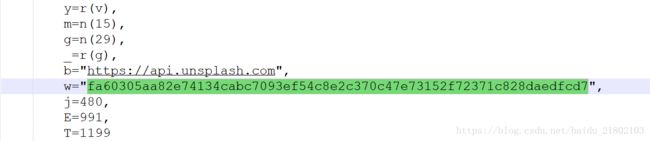
最终得到网站api为:
https://api.unsplash.com/photos/?client_id=fa60305aa82e74134cabc7093ef54c8e2c370c47e73152f72371c828daedfcd7&page=1&per_page=30
其中page, per_page在爬取时修改
访问api地址,可得到包含图片url的json , 包括种类raw, full, regular, small, thumb. 最终取raw

二. 爬取图片URL
1. 安装Scrapy, pip install Scrapy
2. 在工程目录中创建项目scrapy startproject scrapy_unsplash E:\wendi1\pyplace\scrapy_unsplash
3. 进入项目目录, 创建爬虫scrapy genspider unsplash api.unsplash.com --template=crawl
此时在./scrapy_unsplash/spiders目录中生成unsplash.py文件.
配置settings.py , 并发连接数CONCURRENT_REQUESTS = 100 , 下载延迟DOWNLOAD_DELAY = 1.6
4. 首先需要爬取网站, 然后将raw种类的图片URL存入sqlite, unsplash.py代码:
# -*- coding: utf-8 -*-
import json
import sqlite3
import threading
import scrapy
from scrapy.spiders import CrawlSpider
class UnsplashSpider(CrawlSpider):
name = 'unsplash'
allowed_domains = ['api.unsplash.com']
def start_requests(self):
createDB() # 创建数据库
start, page = 1, 2000, # 要爬的页面数
for i in range(start, page + 1): # 从第一页开始
url = 'https://api.unsplash.com/photos/?client_id=fa60305aa82e74134cabc7093ef54c8e2c370c47e73152f72371c828daedfcd7&page=' + str(
i) + '&per_page=30'
yield scrapy.Request(url=url, callback=self.parse_item)
def parse_item(self, response):
conn = sqlite3.connect("E:\\wendi1\\pyplace\\scrapy_unsplash\\database\\link.db") # 连接数据库
print('-------------------')
js = json.loads(str(response.body_as_unicode()), 'utf-8') # 读取响应body,并转化成可读取的json
for j in js:
link = j["urls"]["raw"]
sql = "INSERT INTO LINK(LINK) VALUES ('%s');" % link # 将link插入数据库
conn.execute(sql)
semaphore = threading.Semaphore(1) # 引入线程信号量,避免写入数据库时死锁
semaphore.acquire() # P操作
conn.commit() # 写入数据库,此时数据库文件独占
semaphore.release() # V操作
def createDB(): # 创建数据库
conn = sqlite3.connect("E:\\wendi1\\pyplace\\scrapy_unsplash\\database\\link.db") # Sqlite是一个轻量数据库,不占端口,够用
conn.execute("DROP TABLE IF EXISTS LINK;") # 重新运行删掉数据库
conn.execute("CREATE TABLE LINK (" # 创建属性ID:主键自增;属性LINK:存放图片链接
"ID INTEGER PRIMARY KEY AUTOINCREMENT,"
"LINK VARCHAR(255));")
5. 执行scrapy crawl unsplash . 在第16行可修改爬取的页面总数
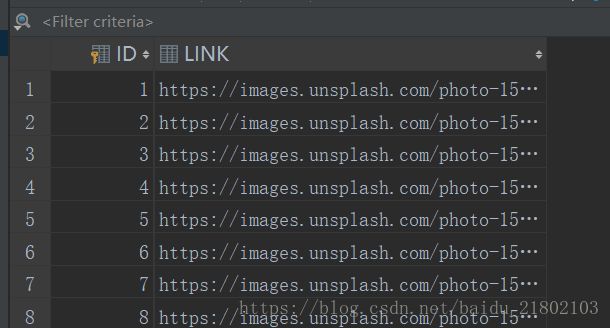
url已存入sqlite中 :
三. 下载图片
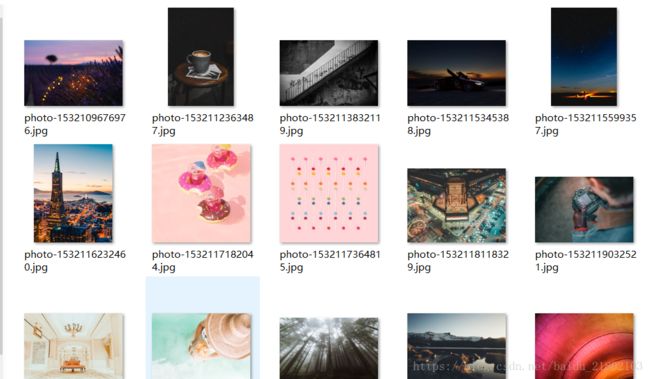
网站中共2500页, 每页30条数据, 共75000张图, 每张图片较小的5兆 --> 360G + . 我下载了4000张, 30G
1.读取sqlite, 使用threadpool多线程和urllib下载图片到本地 :
Downloader.py文件
# -*- encoding:utf-8 -*-
import sqlite3, urllib.request, threadpool # sqlite3:管理数据库;urllib:下载文件;threadpool:线程池
class Downloader:
def __init__(self, urls, folder, threads=10): # 初始化函数
self.urls = urls # 需要下载的网址list
self.folder = folder # 保存的文件目录
self.threads = threads # 并发线程数
def run(self):
pool = threadpool.ThreadPool(self.threads) # 新建线程池
requests = threadpool.makeRequests(self.downloader, self.urls) # 新建请求
[pool.putRequest(i) for i in requests] # 将请求装入线程池
pool.wait() # 等待运行完成
def downloader(self, url):
pre = url.split('/')[-1]
# name = pre if pre.split(".")[-1] in ["jpg", "png", "bmp"] else pre + ".jpg" # 文件名
name = pre[:19] + ".jpg" # 文件名
print(self.folder + "/" + name)
self.auto_down(url, self.folder + "/" + name) # 下载
def auto_down(self, url, filename): # 处理出现网络不好的问题,重新下载
try:
urllib.request.urlretrieve(url, filename)
except urllib.request.URLError as e:
print(str(e) + 'Network Error,redoing download :' + url)
self.auto_down(url, filename) # 递归
if __name__ == "__main__":
urls = []
conn = sqlite3.connect("e:/wendi1/pyplace/scrapy_unsplash/database/link.db") # 连接数据库
cursor = conn.execute("SELECT LINK FROM LINK WHERE ID <= 4000") # 选择总数
for row in cursor:
urls.append(row[0])
pd = Downloader(urls, "e:/wendi1/pyplace/scrapy_unsplash/files", threads=50) # 新建下载器
pd.run()
结果 :
源码 : https://github.com/00wendi00/Scrapy-Unsplash