利用进程信息追查内存泄漏
一、问题现象
Bigpipe是Baidu公司内部的分布式传输系统,其服务器模块Broker采用异步编程框架来实现,并大量使用了引用计数来管理对象资源的生命周期和释放时机。在对Broker模块进行压力测试过程中,发现Broker长时间运行后,内存占用逐步变大,出现了内存泄漏问题。
二、初步分析
针对近期Broker的升级改造点,确定Broker中可能出现内存泄漏的对象。Broker新增了监控功能,其中一项是对服务器各个参数的监控统计,这必然对参数对象有读取操作,每次操作都将引用计数“加一”,并在完成操作后“减一”。当前,参数对象有数个,需要确定是哪个参数对象泄漏了。
三、代码&业务分析
1. 为证明之前的初步分析的结果,可能的方法有是:使用Valgrind运行Broker并启动压力程序复现可能的内存泄漏。但是,使用这种方法:
1) 由于内存泄漏的触发条件并不简单,可能导致复现周期很长,甚至无法复现同样的内存泄漏;
2) 内存泄漏的对象放置在容器中,valgrind正常退出后不报告相关的内存泄漏;
经过另外的测试集群短时间的运行尝试进行复现,果然Valgrind报告未出现异常。
2. 分析现有拥有的条件:幸好,出现“内存泄漏”问题的Broker进程仍然在运行中,真相就在这个进程内部。应该充分利用已有的现场,完成问题的定位。初步希望使用GDB调试。
3. 挑战:使用GDB attach pid的方法将会导致进程挂起,按Broker的设计,一当配对另一个主/从Broker不互相发送心跳, Broker也将自动退出程序,退出后现场就无法保存,这意味着使用GDB的机会只有一次。
4. 方案:利用gdb打印内存信息并从信息中观察可能的内存泄漏点。
5. 步骤一:pmap -x {PID}查看内存信息(如:pmap -x 24671);得到类似如下信息,注意标记为anon的位置:

6. 步骤二:启动gdb ./bin/broker并使用 attach {PID}命令加载现有进程;例如上述进程号为24671,则使用:attach 24671;
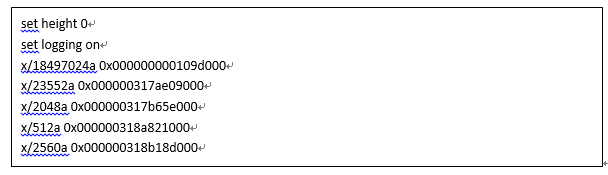
7. 步骤三:使用setheight 0和 setlogging on开启gdb日志,日志将存储于gdb.txt文件中;
8. 步骤四:使用x/{内存字节数}a {内存地址} 打印出一段内存信息,例如上述的anon为堆头地址,占用了144508kb内存,则使用:x/18497024a0x000000000109d000;若命令行较多,可以在外围编辑好命令行直接张贴至gdb命令行提示符中运行,或者将命令行写到一个文本文件中,例如command.txt中,然后再gdb命令行提示符中使用 sourcecommand.txt来执行文件中的命令集合,下面是command.txt文件的内容;
9. 步骤五:分析gdb.txt文件中的信息,gdb.txt中的内容如下:
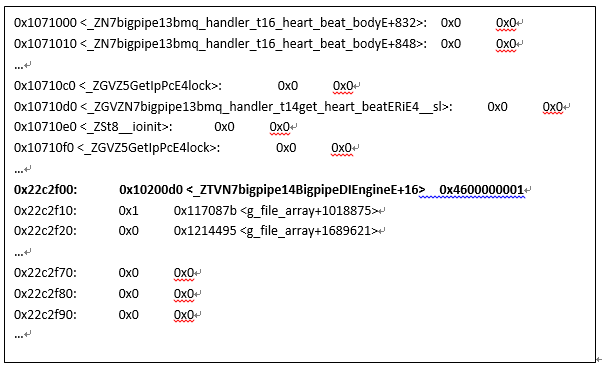
Gdb.txt中内容的说明和分析:第一列为当前内存地址,如0x22c2f00;第二、三、四列分别为当前内存地址对应所存储的值(使用十六进制表示),以及gdb的debug的符号信息,例如:0x10200d0<_ZTVN7bigpipe15BigpipeDIEngineE+16> 0x4600000001,分别表示:“前16字节”、“符号信息(注意有+16的偏移)”、“后16字节”,但不是所有地址都会打印gdb的debug符号信息,有时符号信息显示在第三列,有时显示在第二列。上述这行内存地址0x22c2f00 存储了bigpipe::BigpipeDiEngine 类的生成的其中一个对象的虚析构函数的函数指针,即虚函数表指针(vptr),其中地址0x10200d0附近内存存储的应该是BigpipeDiEngine类的虚函数表(vtbl),如下所示:

地址0x10200d0中的值是指向BigpipeDiEngine类的析构函数的地址,即真正的析构函数代码段头地址0x53e2c6。可以从上述执行结果看到,地址0x53e2c6的“符号信息”是析构函数名
因此,对gdb.txt排序并做适当处理获得符号(类名/函数名称)出现的次数的列表。例如将上述内容过滤出带尖括号的“符号信息”部分并按出现次数排序,可以使用类似如下命令,catgdb.txt |grep "<"|awk -F '<' '{print $2}' |awk -F '>''{print $1}' |sort |uniq -c|sort -rn > result.txt,过滤出项目相关的变量前缀(如bmq、Bigpipe、bmeta等)cat result.txt|grep -P"bmq|Bigpipe|bigpipe|bmeta"|grep "_ZTV" > result2.txt,获得类似如下的列表:

10. 然后找出和本工程项目相关的且出现次数最多的为CConnect对象;判断出可能泄漏的对象后,还需要定位在异步框架下,哪个引用计数出现了问题导致CConnect对象无法正常减一并得到释放。
11. 经过追查新增的“监控”功能与CConnect相关的代码,如下。

四、真相大白
查看atomic_add函数的实现(如下),可以得知,返回值是自增(减)之前的值,而由于函数名称atomic_add并未特别的表现出这样的含义,导致调用者误用了这个函数,认为是自增之后的值,最终引用计数误认为不为0,导致未执行_free操作,进而导致内存泄漏。通常,和__sync_fetch_and_add对应的函数还有__sync_add _and_fetch,这两者的区别在于“先获得值再加”还是“先加值在获取”。

五、解决方案
因此,程序的改进如下:

六、总结
1. 由于异步框架实现的程序对问题定位跟踪难度较高,需要综合:日志,gdb,pmap等手段完成问题复现和定位;
2. Valgrind检测内存泄漏并不是唯一的方法,且具有一定的局限性;
3. 函数名称定义尽量直观表明函数功能,能够避免调用方的一部分错误;
4. 应当仔细阅读库函数的说明文档,了解使用方法;
5. 本方法运用的场景和局限:1)使用gdb打印内存信息中,必须符合实例数和内存信息符号有一对一关系的情形,上述实践中CConnect类有虚析构函数,因此在内存信息中能查看到虚函数表指针,且和出现的符号有一一对应的关系,由此能作为内存泄漏存在于此类的推测条件;若泄漏的内存在内存信息中没有留下“痕迹”则无法获得内存泄漏的有效信息;2)在线下尝试内存泄漏复现失败后,但有内存泄漏的进程(现场)在线上仍然存在,可以尝试使用上述方法,从已有的进程(现场)中更多获取内存泄漏信息;3)此方法可以利用现有的已经产生内存泄漏的进程(现场)进行分析,充分利用了已有的问题进程;4)上述方法作为其他内存泄漏调试方法的一种补充,一种值得尝试的方法,可以作为参考。