【自动驾驶】深度学习用于自动驾驶技术 DeepDriving(ICCV 2015)
无人驾驶技术在最近几年得到了迅猛发展,今天将分享 ICCV 2015 的一篇有关方面的论文:
DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving
有兴趣的读者可以参考其官网链接。本文并非完全翻译该论文,主要说明其思想和创新点。
1. 相关研究论述
目前相关研究主要集中于两种方法,第一种方法基于中间的检测方法,第二种方法基于直接映射法。本文作者提出了第三种方法,作者通过提出一组可用于自动驾驶的场景描述指标,通过精确的学习这些指标的值,最后完成决策。
1.1 基于中间检测的方法
这种方法需要通过计算机视觉中的检测方法检测与驾驶相关的各种目标,包括标志线,交通标志,信号灯,其他车辆,行人等等。将这些目标检测出来之后,通过一种方法将其合并到最终的决策。
这种方法的缺点在于,为了进行自动驾驶,算法必须将所有的信息考虑在内。实际上,无人车所处的环境中大部分信息都是无用信息,即对无人车的驾驶没有帮助,考虑全部的信息显然会增加算法的复杂程度。
无人车驾驶有一个鲜明的特点,就是其输出的信息维度很低。我们只需要速度和方向这两个指标就可以进行无人车驾驶。但是基于中间检测的方法提供了一个非常高维度的中间信息,因此含有很多冗余。
实际上,目前的目标检测方法一般都是将障碍物用矩形框框起来表示,实际上在无人驾驶中,我们更需要的是障碍物与无人车之间的距离,而并不需要知道障碍物的具体位置。因此,本文的方法中并没有直接套用传统的障碍物检测方法,而是直接学习障碍物与自身的距离。
另外,作者指出,这种系统仅靠视觉做决策在真实环境中效果不佳,往往需要依赖其他传感器的信息,包括激光、GPS、雷达等。
1.2 直接映射方法
这种方法的输入时当前无人车视场中的图像,输出是当前的转向角度,中间使用一个ConvNet进行学习。这种方法相对简单,其需要的训练数据是人驾驶车辆进行一段时间的图像采集,同时记录人为控制时转向的角度,即可作为训练数据进行学习。
这种方法的缺陷是其对无人车驾驶场景的抽象能力极为有限,在面对复杂的驾驶情况时难以做出决策:
- 不同的驾驶人在面对相同情况时可能做出不同的决策。因此,训练数据中很可能会存在冲突的现象发生,使得这一学习过程称为了一个病态问题。例如:当前方出现车辆时,有的人会选择超车,有的人会选择跟车。
- 将图像直接映射为转向角度的抽象程度太低,这种描述无法提供对当前环境的完整描述。例如:在这种方法中,超车这一完整动作将被视为先左转,然后直行,一段时间后再右转。仅此而已,缺乏更强的表达能力。
2.方法
2.1 数据来源
数据从无人驾驶仿真平台 TORCS(The Open Racing Car Simulator) 中采集。这其实是一个赛车游戏,通过人为进行赛车游戏,在游戏中记录作者定义的各种指标,完成数据采集。
2.2 将图像映射到自定义的affordance
本文使用了一个卷积神经网络(ConvNet)来讲原始的图像映射到定义的状态指示器(affordance indicators)。本文重点模拟高速公路的行驶场景,在高速公路上,需要无人车对当前车道和旁边两个车道的状况进行记录,根据这三个车道的信息进行决策。常见的情况如下图所示:

高速公路的驾驶状态可以被分类为两个类别:
- in lane system
- on marking system (遇到障碍物需要变道超车或跟车行驶)
为了支持这两种行为,我们定义了一个系统来表达这两种系统之间的协调关系。本文共定义了13个indicator来指示当前的驾驶环境,根据不同indicator的输出来最终决策。

这13个indicator在不同的驾驶状态下部分可能处于激活状态,而另一部分可能处于不活跃状态。
2.3 通过indicator来控制无人车
当计算出文中定义的13个indicator之后,可以将这些指标用于转向控制。
我们的目标是最小化无人车当前位置与当前车辆中心线的距离。用 discenter 表示当前无人车与中心线的距离。则转向角度为:
其中 C 是一个系数。当无人车变道时,目标道路也随之改变。
在每一帧中,系统将会计算理想的速度,通过理想速度与当前速度的关系来控制无人车当前需要加速或者减速。
文中定义了通过13个indicator到车辆动作的控制器:
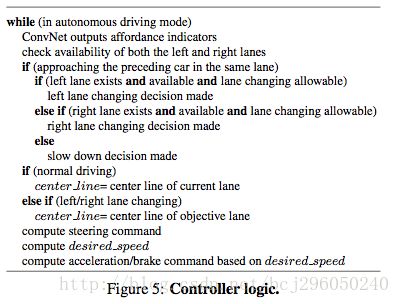
3.实现
卷积神经网络的实现基于Caffe,网络结构使用标准的 AlexNet。含有5个卷积层,其后含有4个全连接层。全连接层的维度分别为4096,4096,256和13。输出层为13分别表示13个indicator的值。损失函数使用欧几里得函数。因为这13个indicator的值有不同的取值范围,因此我们将其归一化到[0.1, 0.9]。
我们选择了 7 种车和 22 种地图,如下。

ConvNet 的输入图像是经过下采样的原始图像,大小为 280*210。同时训练数据中加入了极端的驾驶条件,如 off the road 以及 collide with other cars 等,通过这些使得神经网络更具鲁棒性。
共计采集了48W+图像,训练过程与AlexNet非常相似,不同之处在于训练样本并非方形而是长方形。同时,我们没有在原始数据样本中做任何形变处理。将数据打乱进行训练,初始的 learning rate=0.1,batch_size=64。经过了140000次迭代后停止。
在测试过程中遇到的问题: 当超车时,由于无人车无法感知到位于车辆后方的环境的信息,而仅通过正前方的信息进行决策,因此无无人车在超车时无法知道附近车道是否安全,后方是否会有速度更快的车。
4. 在Torcs虚拟环境中的测试和评价
在Torcs提供的虚拟环境中,ConvNet被用作车辆的控制器。为了评价我们的13个indicator的值是否能对外界环境有完整的描述能力,我们在测试时选用了训练数据中不存在的的样本。

在实验中做了如下假设:把当前车作为参考目标,其在垂直方向的位置是固定的,仅仅水平移动(根据算法提供的角度angle)。交通中的其他车辆仅仅垂直移动。
4.1 定性描述
经过测试,我们的系统可以在Torcs中完成各种地图并且没有任何碰撞发生,当处于变道超车操作时,车辆在变道时会发生稍微偏离道路中心线的情况,但是能够很快矫正过来。我们定义的模型在探测距离无人车周围30m内的其他车辆时非常精确,在30m-60m的范围内渐渐存在一些噪声。因为在280*210的图像中,处于30m之外的其他车辆在图像中会变成一个非常小的点,使得神经网络很难去估计距离。然而,由于无人车的速度不会超过72km/h,因此仅仅探测30m之内的其他车辆对于我们的系统来说已经足够。
为了平稳驾驶,我们的系统可以忍受indicator测量的适当的误差。无人车系统是一个连续的系统,即使偶尔某几次出现了测量错误,也不会影响其平稳驾驶。
整个系统架构如下所示:

4.2 与baseline进行比较
为了定量描述在Torcs测试中的效果,我们与其他baseline方法进行如下比较。
1. Behavior reflex ConvNet
这种方法将图像直接映射成转向角度,完全依靠一个神经网络进行学习。我们在Torcs中训练这个模型,基于如下假设:
(1) 训练样本全部在空的道路上采集,即没有其他车辆。无人车仅需要跟随标志线驾驶。
(2)训练样本在真是的交通环境中采集,无人车的任务是跟随标志线,同时完成超车动作。
在任务1的测试中,这种 behavior reflex 系统能够完成任务。在任务2中,系统表现出了一定的跟车和超车的能力,但是发生了碰撞,同时其驾驶行为是不稳定的。这种不稳定的驾驶决策不同于人在驾驶时的行为。
2. mediated perception(基于标志线检测)
我们根据【文末参考文献1】中的方法完成标志线检测。
(建议读者阅读这篇文献,否则可能无法理解该方法)
因为仅有左右两条标志线的检测比较可靠,因此我们通过SVC(支持向量分类)和SVR(支持向量回归)将标志点检测映射到我们定义的13个indicator中。
我们训练了一个系统,包括 8 个支持向量回归(SVR) 和 6 个支持向量分类器,使用libsvm工具完成。系统模型如下:

因为标志线检测的baseline在效果方面可能较弱,因此我们创建了训练数据和测试数据来使得这个任务更简单。所有训练数据(2430 samples)和测试数据(2533 samples)都通过同一辆车来收集。在实验中发现,即使训练数据和测试数据都出自于同一辆车,这种标志线检测方法仍然很容易发生错误,我们定义错误矩阵为平均绝对值误差(MAE),代表13个指标的检测结果与真实值的距离。下图是比较结果:

3. Direct Perception with GIST(略)
5. 在真实环境中测试
5.1 真实视频测试
在真实环境的测试中,我们选用了一段搜集拍摄的视频作为测试。虽然训练是在Torcs中,而测试是在真实环境中,但在测试中其表现也很好。尤其是关于标志线检测的几个indicator表现稳定,能够为无人车提供可靠的位置信息。车辆检测的几个indicator的表现稍微含有一些噪声,因为torcs中的车辆和真实环境中的车辆有些不同。
5.2 KITTI测试集中测试车辆距离
为了定性的描述我们的方法在真实数据集中对于车辆距离的检测是否准确,我们使用 KITTI 数据集进行测试,测试无人车在行进过程中与前方车辆的距离。
KITTI 数据集包括了超过 40000 个双目立体视觉图片,在欧洲的城市道路上拍摄,每一组图片都有点云文件,通过点云可以采集出于前方车辆的距离。
在KITTI数据集上测试时,我们搭建的神经网络不同于之前的神经网络,因为在大多数KITTI的图像中,并没有标志线的存在,因此我们无法通过检测标志线来定位车辆。 在每张图片中,我们定义了一个二维坐标系:坐标系的原点是无人车,y轴指向无人车的前方,x轴指向无人车的右侧方向。卷积神经网络的优化的目标是找到前方车辆在这个坐标系中的 (x,y) 坐标。坐标系的定义如下图所示:
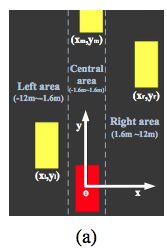
在原始的 KITTI 图像中有许多图片,但是仅仅部分情况下,即当前方车辆与无人车相距较近且位于同一车道时,对前方车辆的位置检测是必要的。因此我们根据坐标系的定义将无人车周围的车辆分为三种区域。
1)中心区域, xϵ[−1.6,1.6] ,前方车辆与无人车处于同一个车道上
2)左侧区域, xϵ[−12,1.6] ,前方车辆处于无人车的左侧
3)右侧区域, xϵ[1.6,12] ,前方车辆处于无人车的右侧
我们不考虑这三种区域之外的其他区域的车辆。我们训练了一个卷积神经网络来估计 (x,y) 坐标,因此神经网络有6个输出。
我们采用了两个卷积神经网络,近距离范围的卷积神经网络用于探测 2-25m 的距离内的车辆,选用图像分辨率为 497*150,远距离的神经网络用于探测 15-55m 的区域,其输入时经过剪裁后的图片,仅包括中心区域。最终的距离估计是这两个神经网络的输出的结合。
同时在训练时由于训练样本不足以训练一个网络,文章对训练数据进行了一些处理。
5.3 与基于 DPM 的目标检测方法相比较
我们比较了KITTI数据集上训练的卷积神经网络与基于DPM的车辆检测方法。我们在完整的分辨率图像上运行DPM算法,该算法可以产出图中每一个车辆的位置信息,用标志框表示。然后我们再通过投影中心店到无穷远处的方法将标志框的位置转换成与无人车的距离。这一过程使用了摄像机标定模型。这种投影方法在当参考平面是水平的时候非常准确。
DPM算法可以在图像中探测多个目标,同时在无人车的前方,左侧和右侧选择与无人车距离最近的目标,来计算误差。
由于我们的图片是在实际驾驶过程中拍摄的,因此与无人车相距最近的目标一般出现在图片的左下角或者右下角,DPM算法无法探测处于这些地方的无人车,但是卷积神经网络能够很好的解决这些情况。
两种方法的比较结果如下表:

在表中,我们观察到两种方法的表现类似。分析其原因,发现卷积神经网络比DPM算法有更多的假正(false positive)样本。根据我们的经验来看,假正样本的出现主要是由于没有更多的训练样本导致的。
另外,DPM在探测目标时,需要一个平坦的地面作为投影来计算距离,因此在不平坦的路面上,如山地等,这种方法表现糟糕。
6. 神经网络的可视化
为了理解卷积神经网络对于输入图像的反馈,我们可视化了激活的pattern,即卷积神经网络的特征。在21100的数据集中,为每一个全连接层的的神经元,我们选择了100个最能激活该神经元的样本,然后取平均值。通过这种方法,我们可以大略的认识到卷积神经网络学到了什么。
下图随机的展示了几个激活pattern,可以看到神经元会被无人车的方法、标志线的位置、交通中的其他目标所激活,因此我们相信,卷积神经网络已经学习到了能够用于自动驾驶的特征。
在卷积神经网络的每一层中,一个response map可以被表示成在所有filter对每一个输入像素激活值最高的值。我们选择了几张输入图片,第四个卷积层的response map如下图所示。可以看出卷积神经网络对附近的车辆有很高的激活值。同时对标志线的检测也有很高的激活值。

7. 结论
直接看原文吧
In this paper, we propose a novel autonomous driving paradigm based on direct perception. Our representation leverages a deep ConvNet architecture to estimate the affordance for driving actions instead of parsing entire scenes (mediated perception approaches), or blindly mapping an image directly to driving commands (behavior reflex ap- proaches). Experiments show that our approach can per- form well in both virtual and real environments.
结束