百度语音合成与语音识别api使用(Java版本)
百度语音合成官方文档:https://ai.baidu.com/docs#/TTS-Online-Java-SDK/top
百度语音识别官方文档:https://ai.baidu.com/docs#/ASR-Online-Java-SDK/top
本文项目源码下载:https://github.com/Blankwhiter/SpeechSynthesizer
第一步 注册百度账号 以及 创建创建应用
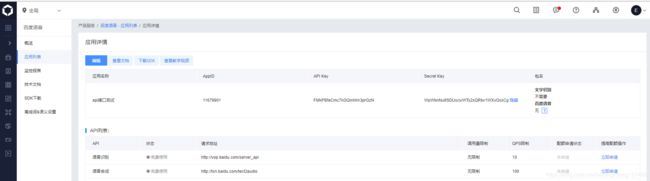
读者请自行注册,以及创建应用 并在创建应用过程中加入接口选择。创建完成后,可得到AppID,API Key,Secret Key。如果任何问题,请在评论留言。最终结果应用详情界面如下:
第二步 加入开发所需环境
在springboot的pom.xml中dependencies节点下 加入fastjson,百度aip的JavaSDK,以及mp3转pcm的mp3spi。
pom.xml 文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>com.examplegroupId>
<artifactId>speechsynthesizerartifactId>
<version>0.0.1-SNAPSHOTversion>
<packaging>jarpackaging>
<name>SpeechSynthesizername>
<description>Demo project for Spring Bootdescription>
<parent>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-parentartifactId>
<version>2.0.4.RELEASEversion>
<relativePath/>
parent>
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8project.reporting.outputEncoding>
<java.version>1.8java.version>
properties>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starterartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.47version>
dependency>
<dependency>
<groupId>com.baidu.aipgroupId>
<artifactId>java-sdkartifactId>
<version>4.1.1version>
dependency>
<dependency>
<groupId>com.googlecode.soundlibsgroupId>
<artifactId>mp3spiartifactId>
<version>1.9.5.4version>
dependency>
dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
plugin>
plugins>
build>
project>
第三步 编写语音合成代码
内容如下:
/**
* 单例 懒加载模式 返回实例
* @return
*/
public static AipSpeech getInstance(){
if (client==null){
synchronized (AipSpeech.class){
if (client==null) {
client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
}
}
}
return client;
}
/**
* 语音合成
* @param word 文字内容
* @param outputPath 合成语音生成路径
* @return
*/
public static boolean SpeechSynthesizer(String word, String outputPath) {
/*
最长的长度
*/
int maxLength = 1024;
if (word.getBytes().length >= maxLength) {
return false;
}
// 初始化一个AipSpeech
client = getInstance();
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 可选:设置代理服务器地址, http和socket二选一,或者均不设置
// client.setHttpProxy("proxy_host", proxy_port); // 设置http代理
// client.setSocketProxy("proxy_host", proxy_port); // 设置socket代理
// 调用接口
TtsResponse res = client.synthesis(word, "zh", 1, null);
byte[] data = res.getData();
org.json.JSONObject res1 = res.getResult();
if (data != null) {
try {
Util.writeBytesToFileSystem(data, outputPath);
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
if (res1 != null) {
log.info(" result : " + res1.toString());
}
return false;
}
使用示例:
SpeechSynthesizer("简单测试百度语音合成", "d:/SpeechSynthesizer.mp3");
注:语音合成文字是不能超过1024字节,读者可自行改装,将多次内容合成进行拼装。
第四步 编写语音识别代码
/**
* 语音识别
* @param videoPath
* @param videoType
* @return
*/
public static String SpeechRecognition(String videoPath, String videoType) {
// 初始化一个AipSpeech
client = getInstance();
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 可选:设置代理服务器地址, http和socket二选一,或者均不设置
// client.setHttpProxy("proxy_host", proxy_port); // 设置http代理
// client.setSocketProxy("proxy_host", proxy_port); // 设置socket代理
// 调用接口
JSONObject res = client.asr(videoPath, videoType, 16000, null);
log.info(" SpeechRecognition : " + res.toString());
return res.toString(2);
}
/**
* mp3转pcm
* @param mp3filepath MP3文件存放路径
* @param pcmfilepath pcm文件保存路径
* @return
*/
public static boolean convertMP32Pcm(String mp3filepath, String pcmfilepath){
try {
//获取文件的音频流,pcm的格式
AudioInputStream audioInputStream = getPcmAudioInputStream(mp3filepath);
//将音频转化为 pcm的格式保存下来
AudioSystem.write(audioInputStream, AudioFileFormat.Type.WAVE, new File(pcmfilepath));
return true;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
}
}
/**
* 获得pcm文件的音频流
* @param mp3filepath
* @return
*/
private static AudioInputStream getPcmAudioInputStream(String mp3filepath) {
File mp3 = new File(mp3filepath);
AudioInputStream audioInputStream = null;
AudioFormat targetFormat = null;
try {
AudioInputStream in = null;
MpegAudioFileReader mp = new MpegAudioFileReader();
in = mp.getAudioInputStream(mp3);
AudioFormat baseFormat = in.getFormat();
targetFormat = new AudioFormat(AudioFormat.Encoding.PCM_SIGNED, baseFormat.getSampleRate(), 16,
baseFormat.getChannels(), baseFormat.getChannels()*2, baseFormat.getSampleRate(), false);
audioInputStream = AudioSystem.getAudioInputStream(targetFormat, in);
} catch (Exception e) {
e.printStackTrace();
}
return audioInputStream;
}
使用示例:
convertMP32Pcm("d:/SpeechSynthesizer.mp3","d:/SpeechSynthesizer.pcm");
SpeechRecognition("d:/SpeechSynthesizer.pcm","pcm");
注:原始 PCM 的录音参数必须符合 8k/16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。语音时长上限为60s,请不要超过这个长度,否则会返回错误。
第五步 合成一个工具类
SpeechUtil.java 内容如下:
import com.baidu.aip.speech.AipSpeech;
import com.baidu.aip.speech.TtsResponse;
import com.baidu.aip.util.Util;
import javazoom.spi.mpeg.sampled.file.MpegAudioFileReader;
import lombok.extern.slf4j.Slf4j;
import org.json.JSONObject;
import javax.sound.sampled.AudioFileFormat;
import javax.sound.sampled.AudioFormat;
import javax.sound.sampled.AudioInputStream;
import javax.sound.sampled.AudioSystem;
import java.io.File;
import java.io.IOException;
/**
* 百度语音工具类
*/
@Slf4j
public class SpeechUtil {
public static final String APP_ID = "11679901";
public static final String API_KEY = "FMkPBfeCmc7kGQmhHr3prGzN";
public static final String SECRET_KEY = "WpWbnNu9SDUscwWTs2sQRtw1WXvGssCg";
private static AipSpeech client;
public static void main(String[] args) throws IOException {
// SpeechSynthesizer("简单测试百度语音合成", "d:/SpeechSynthesizer.mp3");
convertMP32Pcm("d:/SpeechSynthesizer.mp3","d:/SpeechSynthesizer.pcm");
SpeechRecognition("d:/SpeechSynthesizer.pcm","pcm");
}
/**
* 单例 懒加载模式 返回实例
* @return
*/
public static AipSpeech getInstance(){
if (client==null){
synchronized (AipSpeech.class){
if (client==null) {
client = new AipSpeech(APP_ID, API_KEY, SECRET_KEY);
}
}
}
return client;
}
/**
* 语音合成
* @param word 文字内容
* @param outputPath 合成语音生成路径
* @return
*/
public static boolean SpeechSynthesizer(String word, String outputPath) {
/*
最长的长度
*/
int maxLength = 1024;
if (word.getBytes().length >= maxLength) {
return false;
}
// 初始化一个AipSpeech
client = getInstance();
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 可选:设置代理服务器地址, http和socket二选一,或者均不设置
// client.setHttpProxy("proxy_host", proxy_port); // 设置http代理
// client.setSocketProxy("proxy_host", proxy_port); // 设置socket代理
// 调用接口
TtsResponse res = client.synthesis(word, "zh", 1, null);
byte[] data = res.getData();
org.json.JSONObject res1 = res.getResult();
if (data != null) {
try {
Util.writeBytesToFileSystem(data, outputPath);
} catch (IOException e) {
e.printStackTrace();
}
return true;
}
if (res1 != null) {
log.info(" result : " + res1.toString());
}
return false;
}
/**
* 语音识别
* @param videoPath
* @param videoType
* @return
*/
public static String SpeechRecognition(String videoPath, String videoType) {
// 初始化一个AipSpeech
client = getInstance();
// 可选:设置网络连接参数
client.setConnectionTimeoutInMillis(2000);
client.setSocketTimeoutInMillis(60000);
// 可选:设置代理服务器地址, http和socket二选一,或者均不设置
// client.setHttpProxy("proxy_host", proxy_port); // 设置http代理
// client.setSocketProxy("proxy_host", proxy_port); // 设置socket代理
// 调用接口
JSONObject res = client.asr(videoPath, videoType, 16000, null);
log.info(" SpeechRecognition : " + res.toString());
return res.toString(2);
}
/**
* mp3转pcm
* @param mp3filepath MP3文件存放路径
* @param pcmfilepath pcm文件保存路径
* @return
*/
public static boolean convertMP32Pcm(String mp3filepath, String pcmfilepath){
try {
//获取文件的音频流,pcm的格式
AudioInputStream audioInputStream = getPcmAudioInputStream(mp3filepath);
//将音频转化为 pcm的格式保存下来
AudioSystem.write(audioInputStream, AudioFileFormat.Type.WAVE, new File(pcmfilepath));
return true;
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
return false;
}
}
/**
* 获得pcm文件的音频流
* @param mp3filepath
* @return
*/
private static AudioInputStream getPcmAudioInputStream(String mp3filepath) {
File mp3 = new File(mp3filepath);
AudioInputStream audioInputStream = null;
AudioFormat targetFormat = null;
try {
AudioInputStream in = null;
MpegAudioFileReader mp = new MpegAudioFileReader();
in = mp.getAudioInputStream(mp3);
AudioFormat baseFormat = in.getFormat();
targetFormat = new AudioFormat(AudioFormat.Encoding.PCM_SIGNED, baseFormat.getSampleRate(), 16,
baseFormat.getChannels(), baseFormat.getChannels()*2, baseFormat.getSampleRate(), false);
audioInputStream = AudioSystem.getAudioInputStream(targetFormat, in);
} catch (Exception e) {
e.printStackTrace();
}
return audioInputStream;
}
}
注:开发工具需要安装lombok
写在最后,读者如需更多详情配置请移步到百度api官网进行查阅。
附录:
1.语音合成错误码对应表:
SDK本地检测参数返回的错误码:
| error_code | error_msg | 备注 |
|---|---|---|
| SDK108 | connection or read data time out | 连接超时或读取数据超时 |
服务端返回的错误码:
| 错误码 | 含义 |
|---|---|
| 500 | 不支持的输入 |
| 501 | 输入参数不正确 |
| 502 | token验证失败 |
| 503 | 合成后端错误 |
2.语音识别错误码对应表:
SDK本地检测参数返回的错误码:
| error_code | error_msg | 备注 |
|---|---|---|
| SDK108 | connection or read data time out | 连接超时或读取数据超时 |
服务端返回的错误码
| 错误码 | 用户输入/服务端 | 含义 | 一般解决方法 |
|---|---|---|---|
| 3300 | 用户输入错误 | 输入参数不正确 | 请仔细核对文档及参照demo,核对输入参数 |
| 3301 | 用户输入错误 | 音频质量过差 | 请上传清晰的音频 |
| 3302 | 用户输入错误 | 鉴权失败 | token字段校验失败。请使用正确的API_KEY 和 SECRET_KEY生成 |
| 3303 | 服务端问题 | 语音服务器后端问题 | 请将api返回结果反馈至论坛或者QQ群 |
| 3304 | 用户请求超限 | 用户的请求QPS超限 | 请降低识别api请求频率 (qps以appId计算,移动端如果共用则累计) |
| 3305 | 用户请求超限 | 用户的日pv(日请求量)超限 | 请“申请提高配额”,如果暂未通过,请降低日请求量 |
| 3307 | 服务端问题 | 语音服务器后端识别出错问题 | 目前请确保16000的采样率音频时长低于30s,8000的采样率音频时长低于60s。如果仍有问题,请将api返回结果反馈至论坛或者QQ群 |
| 3308 | 用户输入错误 | 音频过长 | 音频时长不超过60s,请将音频时长截取为60s以下 |
| 3309 | 用户输入错误 | 音频数据问题 | 服务端无法将音频转为pcm格式,可能是长度问题,音频格式问题等。 请将输入的音频时长截取为60s以下,并核对下音频的编码,是否是8K或者16K, 16bits,单声道。 |
| 3310 | 用户输入错误 | 输入的音频文件过大 | 语音文件共有3种输入方式: json 里的speech 参数(base64后); 直接post 二进制数据,及callback参数里url。 分别对应三种情况:json超过10M;直接post的语音文件超过10M;callback里回调url的音频文件超过10M |
| 3311 | 用户输入错误 | 采样率rate参数不在选项里 | 目前rate参数仅提供8000,16000两种,填写4000即会有此错误 |
| 3312 | 用户输入错误 | 音频格式format参数不在选项里 | 目前格式仅仅支持pcm,wav或amr,如填写mp3即会有此错误 |