oracle 11g中的备份-------逻辑备份
备份 : 是数据库中数据的副本,它可以保护数据在出现意外损失时最大限度的恢复。(现有备份才能恢复)
Oracle数据库的备份包括以下两种类型:
-
①物理备份是对数据库的操作系统物理文件(如数据文件、控制文件和在线日志文件等)的备份
- 在oracle 11g的体系结构中,我们知道物理文件分为关键物理文件和非关键物理文件,上说所说的物理文件为关键物理文件,非关键物理文件有参数文件、密码文件、日志文件等。
-
②逻辑备份是对数据库逻辑组件(如表、视图和存储过程,触发器等数据库对象)的备份
备份为了防止系统出现异常和故障,在oracle中故障可以分为:
1、故障及其类型(4种):
- ①语句故障:在执行 SQL 语句无效可导致语句故障。
例:select * from aa; --假设此时aa表并不存在,所以引起语句故障
-- 不需要处理,oracle自动会进行处理与分析。
- ②用户进程故障:当用户程序出错而无法访问数据库时发生用户进程故障。导致用户进程故障的原因是异常断开连接或异常终止进程
例:用户与服务器相连接,由于用户死机,用户进程消失,用户与服务器的连接断开,
那么同时与之对应的服务器进程也会终止(由pmon来实现)。
-- oracle会自动帮我们完成
- ③实例故障:当 Oracle 的数据库实例由于硬件或软件问题而无法继续运行时,就会发生实例故障
实例包括内存和后台进程,实例故障即就是内存崩溃/泄露等 或 后台进程坏掉等,
通过重启oracle就可以解决实例故障。
--- 同样也不需要我们过多的处理。
- ④介质故障:在数据库无法正确读取或写入某个数据库文件时,会发生介质故障
如:硬盘坏掉了,导致数据文件不能读取了/不能用了。
--需要DBA进行相关处理
2、传统的导入导出:
(oracle 9i中)传统的导出exp导入imp程序用于实施数据库的逻辑备份和恢复,传统的导出导入程序是客户端工具。
-
导出程序 将数据库中的对象定义和数据备份到一个操作系统二进制文件中,该二进制文件位于客户端。
-
导入程序 读取二进制导出文件并将对象和数据载入数据库中
过程解释: 将数据库1中的表等导出为一个dmp文件拷贝给优盘,通过imp导入给数据库2
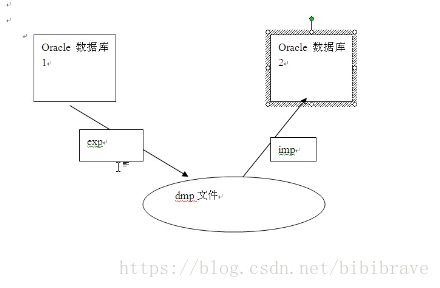
导出和导入实用程序的特点有:
- 可以按时间保存表结构和数据
- 允许导出指定的表,并重新导入到新的数据库中
- 可以把数据库迁移到另外一台异构服务器上
- 在两个不同版本的Oracle数据库之间传输数据
- 在联机状态下进行备份和恢复
- 可以重新组织表的存储结构,减少链接及磁盘碎片(降低高水位线HWM)
导出和导入数据库对象的四种模式是:(一次只能使用一种模式)
1,数据库模式 full:导出和导入整个数据库中的所有对象
2,表空间模式tablespace:导出和导入一个或多个指定的表空间中的所有对象
3,用户模式owner:导出和导入一个或多个用户模式中的所有对象
4,表模式table:导出和导入一个或多个指定的表或表分区
使用以下三种方法调用导出和导入实用程序:
1,交互提示符:以交互的方式提示用户逐个输入参数的值。
2,命令行参数:在命令行指定执行程序的参数和参数值。
3,参数文件:允许用户将运行参数和参数值存储在参数文件中,以便重复
导入导出相关参数:
①使用exp事务的部分参数与其功能:

上述表格中的参数需要通过命令窗口来使用:
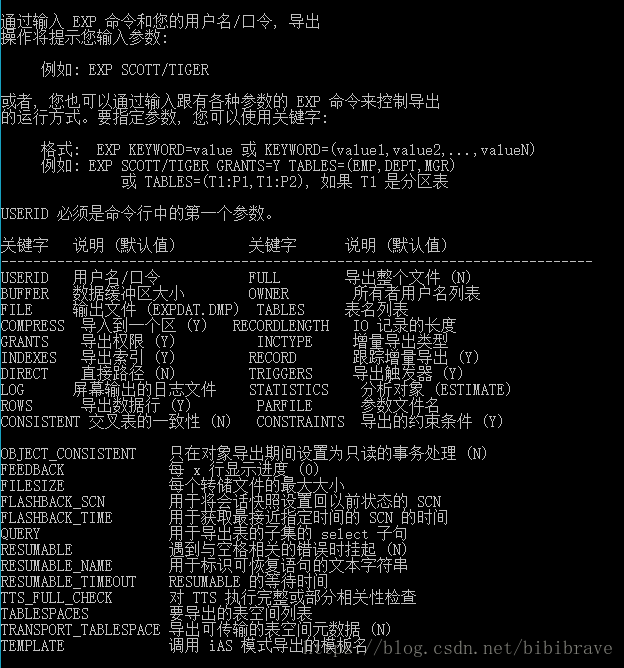
输入 exp help=y 就可以查看exp的所有参数,如下图:
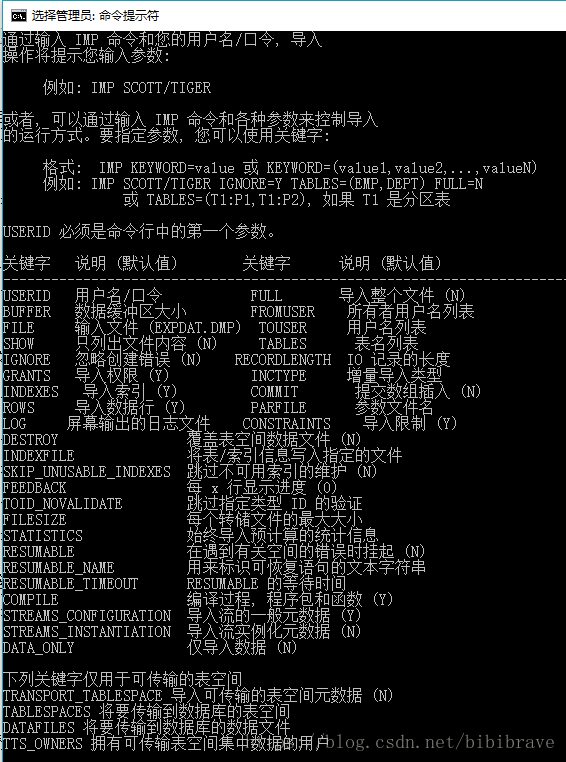
②使用imp事务的部分参数与其功能:
imp help=y
详细介绍导出导入的三种方式:
举例: 以scott用户登录数据库,其下包含表student 和表 address:
工具:命令窗口
①导出—交互提示符

导入—交互提示符
imp 同上述过程一样
②导出—命令行参数法
表模式导出:
exp scott/scott@orcl
tables=(student,address) -- 按表方式导出指定tables
file=f:\scott1.dmp -- 导出的二进制参数文件路径和文件名
log = f:\scott1.log -- 日志信息保存到的日志文件路径和名称。
以该用户身份,导出其他用户名下的表,会产生警告,权限不足;
数据库管理员system可以
exp scott/scott@orcl tables=(user1.t) file=f:\userscott1.dmp
exp system/oracle@orcl tables=(user1.t) file=f:\userscott1.dmp
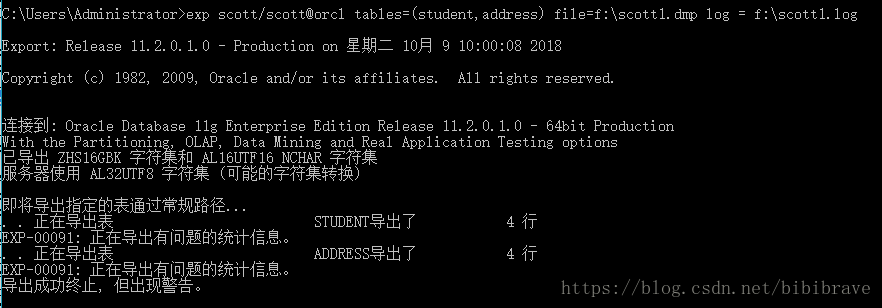
说明:此时导出成功终止,但出现警告,原因是在数据库的服务器端和客户端字符集不同,解决办法见后文。
用户模式:
导出该用户下的所有内容,用户模式:
exp scott/scott@orcl owner=scott file=f:\scott2.dmp log = f:\scott2.log
system的权限下可以导:(即就是非DBA不能导其他用户)
exp system/oracle@orcl
owner=scott
file=f:\system2.dmp
log = f:\system2.log
导入—命令行参数法
与导出相反,首先在SQL*PLUS下删除原有的student和address两张表。
drop table student purge;
drop table address purge;
在命令提示框下:
imp scott/scott@orcl file=f:\scott1.dmp
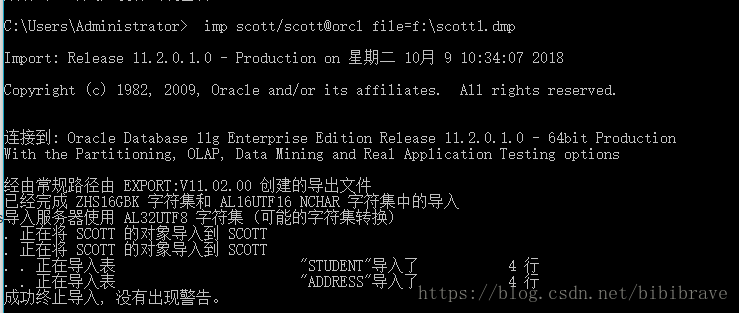
导入自己的表:
- 导入文件中所有内容: 该文件中含有导入的表的创建和插入语句。
imp scott/scott@orcl file=f:\scott1.dmp - 导入文件中指定内容:选择性的导入
imp scott/scott@orcl file=f:\scott1.dmp tables=student
导入别人的表:
-
把别人的文件导入给自己 可以执行
imp user1/user1@orcl file=f:\scott1.dmp fromuser =scott touser =user1 -
把自己的文件导入给别人
不可以执行
imp scott/scott@orcl file=f:\scott1.dmp fromuser=scott touser=user1 -
数据库管理员可以执行把用户1的文件导入给用户2 DBA
imp system/oracle@orcl file=f:\scott1.dmp fromuser=scott touser=user1 -
不可以重复导入,(通俗说在此创建一个已经存在的表并插入相同的数据是不能成功执行的)除非使用参数ignore=y 忽略创建错误 ,并且在没有唯一性的约束的条件下,student address 中的记录会出现两次。
imp user1/user1@orcl file=f:\scott1.dmp fromuser=scott touser=user1 ignore=y
③导出—参数文件 导入同
1)首先建立一个参数文件 例如par.txt 位置在c盘根目录
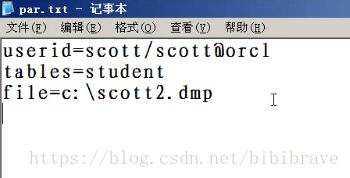
2)回到命令提示框,将路径改为c盘根目录执行文件

实际上就是把文件中所写的参数放到exp中继续运行了。
3、可传输表空间
如果迁移的数据量很大,可以使用可传输表空间:
举例 : 前提是有两个数据库,使用可传输表空间,将orcl数据库中的表空间t1传递给另一个数据库。
orcl system登陆创建表空间:
create tablespace tb1
datafile'D:\app\Administrator\oradata\orcl\tb101.dbf'
size 10m
scott用户在此表空间下写入内容:
create table t tablespace tb1
as select * from all_tables;
1,检查要传输的表空间是否是自包含的。
- 该表空间中的表,及其其中表上的相关内容(如索引)都属于该表空间,那么此表空间就是自包含的,如果表属于一个表表空间,表上索引属于另一个表空间,那么就是非自包含的。
- 检查表空间是否自包含 dbms_tts包中的存储过程可以检查。
2,将表空间设置成只读。(system用户下SQL*PLUS)
alter tablespace tb1 read only;
3,exp进行可传输表空间模式的导出。dos下
exp 'system/oracle@orcl as sysdba' -- 即就是sys用户
tablespaces=tb1
transport_tablespace=y -- y 使用可传输表空间的模式来传输。
file=f:\tb111.dmp
4,将导出文件和数据文件复制到目标数据库上。
- 注意两个文件,即就是刚刚导出的tb111.dmp和数据文件tb101.dbf
- 将这两文文件分别放在路径:e:\tb111.dmp和E:\app\Administrator\oradata\wang\tb101.dbf中
5,目标数据库上,imp进行可传输表空间模式的导入。
imp system/oracle@wang as sysdba ' --导入导出必须为同一个用户。
tablespaces=tb1
transport_tablespace=y
file='e:\tb111.dmp'
datafiles='E:\app\Administrator\oradata\wang\tb101.dbf'
6,目标数据库上,把表空间设置成读写状态。
alter tablespace tb1 read write;
4、数据泵、
exp/imp的缺点是速度太慢,在大型生产库中尤其明显。从10g开始,oracle设计了数据泵,这是一个服务器端的工具,它为Oracle数据提供高速并行及大数据的迁移。
imp/exp可以在客户端调用,但是expdp/impdp只能在服务端,因为在使用expdp/impdp以前需要在数据库中创建一个目录 Directory 。
expdp,impdp相关概念
- 在expdp进行导出时,oracle先自动创建了MT表(主表),并把对象的信息插入到MT表,之后进行导出动作;MT表只存在于导出过程中,过程结束就消失;
- 导出完成后,MT表也导出到转储文件中;
- 导出任务完成后、或者删除了导出任务后,MT表自动删除;如果导出任务异常终止,MT表仍然保留。
导出:
expdp scott/scott@orcl
direcory=MY_DIR
dumpfile=expdp_scott1.dmp
tables(student,address)
-- directory 指定目录 dumpfile 指定转储文件 tables表模式
导入:
impdp scott/scott@orcl
direcory=MY_DIR
dumpfile=expdp_scott1.dmp
数据泵也具有四种模式:表tables、用户schemas、可传输表空间tablespace、全库full。
数据泵的参数介绍
- expdp的参数: expdp help=y
1,部分的exp中的参数仍然可用,有的不能使用,如index。
2,directory:供转储文件和日志文件使用的目录对象。
create directory MY_DIR as 'c:\dir1 ';
grant read,write on directory MY_DIR to scott;
3,job_name:指定的任务的名称。
expdp system/oracle@orcl
direcory=MY_DIR
dumpfile=expdp_system1.dmp
schemas(scott,hr) -- schemas 用户
job_name=expdp1 --相当于给MT表命名,未指定则由oracle自己命名
4,content:指定要导出的数据, 其中有效关键字值为: (ALL), DATA_ONLY 和 METADATA_ONLY,当设置content为ALL 时,将导出对象定义及其所有数据; DATA_ONLY时,只导出对象数据;为METADATA_ONLY时,只导出对象定义 。
content = metadata_only -- 只导出表结构
5,reuse_dumpfiles:如果导出文件已经存在,是否覆盖。
该参数默认不覆盖,若要设置覆盖在语句中加入下述语句:
reuse_dumpfiles =y
6,compression:压缩导出文件。
7,estimate:指定估算被导出表所占用磁盘空间分方法.默认值是BLOCKS
8, estimate_only:是否只估算导出占用的磁盘空间,而不进行真正的导出,默认是N。
9,exclude:用于指定执行操作时要排除对象类型或相关对象,用法:
EXCLUDE=object_type[:name_clause] [,….]
# 例如 导出student表以及其上的约束,但是不导出索引
expdp scott/scott@orcl
direcory=MY_DIR
dumpfile=expdp_scott2.dmp
table=student exclude=index -- 或者使用indexes = N
# 导出scott用户下除student、address的表:
expdp scott/scott@orcl
direcory=MY_DIR
dumpfile=expdp_scott3.dmp
exclude=table:"in('STUDENT')"
exclude=table:"in('ADDRESS')"
10,include:用于指定执行操作时要包含的对象类型或相关对象,用法:
INCLUDE=object_type[:name_clause] [,….]
11,query:导出符合条件的行。
12,attch:连接到现有的作业,可以用在中断导出任务后重新启动导出任务。
- impdp的参数介绍: impdp help=y
1,content:指定要加载的数据, 其中有效关键字值为: (ALL), DATA_ONLY 和 METADATA_ONLY,当设置content为ALL 时,将加载对象定义及其所有数据; DATA_ONLY时,只加载对象数据;为METADATA_ONLY时,只加载对象定义 。
2,estimate:估算所占用磁盘空间分方法.默认值是BLOCKS
3,remap_schema:用于将对象从一个用户下导入到另一个用户下。
remap_schema= scott:hr
4,remap_tablespace:用于将对象从一个表空间下导入到另一个表空间下。
5,remap_datafile:用于在不同文件系统的平台间,切换数据文件路径。