Kafka生产者消费者模型
一、Kafka回顾
1、AMQP协议
消息队列中消息交互规范,多数分布式消息中间件基于该协议进行消息传输
2、Broker
对于kafka,将生产者发送的消息,动态的添加到磁盘,一个Broker等同于一个kafka应用实例,用于存放消息队列
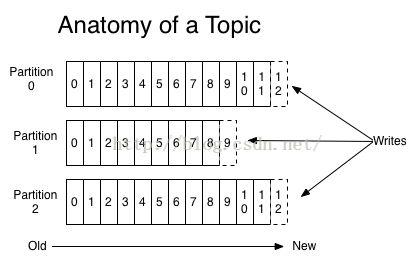
3、主题:分区:消息
一个分区(Patition)等同于一个消息队列,存放n条消息;一个主题(Topic)包括多个分区
二、常用分布式消息中间件特性对比

1、事务
在消息系统中,事务指多条消息一起发送时,要么全部发送成功,或全部回滚,不可能一部分成功,一部分失败
2、负载
大量的生产者和消费者向消息系统发送请求,消息系统必须能够均衡这些请求到n台服务器。
3、动态扩容
系统或服务不支持动态扩容,就意味着当访问量大于当前集群可处理数量时,不得不停止服务,反之,kafka支持zk管理集群,增加或减少一台服务器,并不影响生产环境的服务,从而达到扩容效果
高吞吐量、高水平扩展
三、Kafka消费者模型
Kafka消息系统基于发布-订阅模式,相对于ActiveMQ,没有点对点消息处理机制。
1、分区消费模型
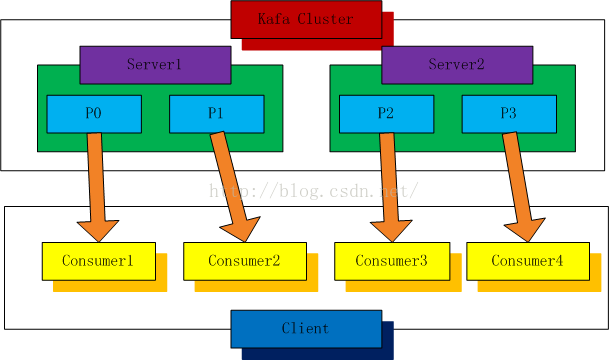
2个kafka 服务器,4个分区(P0-P3) ,分区消费模型即为:1个分区对应1个消费实例,如图4个分区,需要4个消费者实例从分区中取数据。
2、分区消费编码思路
(1)获取分区的size,一共多少个分区;
(2)针对每一个分区,分别创建一个线程,去消费该分区的数据
(3)每个线程即为一个消费者实例,通过连接;执行消费者构建;消费offset (偏移量);记录消息偏移量。
3、组消费模型

同样4个分区,P0-P3,这里使用GroupA,GroupB,GroupA可获取0,3,1,2分区的数据,GourpB也是。分组消费模型中,每个组都能拿到kafka集群当前全量数据。
4、组消费实现思路
(1)获取group里有多少个consumer实例
(2)根据实例个数,创建线程
(3)执行run方法,启动消费
四、Kafka生产者模型
1、同步生产模型
发送一条消息,如果没有收到kafka集群的确认收到的信号,则再次重发,直到发送次数超过设置的最大次数为止。其中有一次收到了确认,就接着发送下一条消息。
2、异步生产模型
消息发送到客户端的缓冲队列中,如果队列中条数到了设置的队列最大数或存放时间达到最大值,就把队列中的消息打包,一次性发送给kafka服务端。
3、同步、异步对比
同步生产模型:
(1)低消息丢失率;
(2)高消息重复率;
(3)高延迟,低吞吐量,每发一条,都要等着确认之后才继续发下一条
异步生产模型:
(1)低延迟;
(2)高发送性能;
(3)高消息丢失率(无确认机制,发送端队列满),不等待确认就直接发下一个,如果发送的队列已经满了,那接着发的消息就全丢失。另外队列满了发送给服务器,也无确认机制,整个队列就丢了。
4、应用场景
要求不能丢消息,对吞吐量没要求,使用同步
日志处理等,丢了几条也可接受,但对吞吐量要求极高,采用异步
Kafka producer的ack的3种机制:
通过初始化producer时的producerconfig可以通过配置request.required.acks不同的值来实现。
0:这意味着生产者producer不等待来自broker同步完成的确认就继续发送下一条(批)消息。
此选项提供最低的延迟但最弱的耐久性保证,因为其没有任何确认机制。
1:这意味着producer在leader已成功收到的数据并得到确认后发送下一条消息。
等待leader的确认后就返回,而不管partion的follower是否已经完成。
-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。
此选项提供最好的耐久性,我们保证没有信息将丢失,只要至少一个同步副本保持存活。
producer的同步异步机制:
通过配置producer.type的值来确定是异步还是同步,默认为同步。async/sync 默认是sync。
如果设置为异步,那么提供了批量发送的功能:
当满足以下其中一个条件的时候就触发发送
batch.num.messages 异步发送 每次批量发送的条目 ;
queue.buffering.max.ms 异步发送的时候 发送时间间隔 单位是毫秒。
其次,异步发送消息的实现很简单,客户端消息发送过来以后,先放入到一个队列中然后就返回了。Producer再开启一个线程(ProducerSendThread)不断从队列中取出消息,然后调用同步发送消息的接口将消息发送给Broker。
producer的分区partion发送:
为了负载均衡一个topic可能会有多个partition,不同的partition存在在不同的broker里面,因此可以设定一定的partition的规则来确定什么样的消息发送到那个partition当中,代码如下:
public class CustomizePartitioner implements Partitioner {
public CustomizePartitioner(VerifiableProperties props) {
}
/**
* 返回分区索引编号
* @param key sendMessage时,输出的partKey
* @param numPartitions topic中的分区总数
* @return
*/
@Override
public int partition(Object key, int numPartitions) {
System.out.println("key:" + key + " numPartitions:" + numPartitions);
String partKey = (String)key;
if ("part2".equals(partKey))
return 2;
return 0;
}
}
partition当中的metadata.broker.list:
该选项用于存放broker的元信息,官方翻译如下:
这个选项是用于一个producer启动的时候,在启动的时候producer会通过这个选项配置的broker的地址去获取元信息(topics, partitions and replicas)。她的格式如下,host1:port1,host2:port2。这个list可以是一个broker集合的子集。
需要注意的是producer是如何动态获取集群中的broker信息的变化呢,它又没有和zookeeper进行交互?
1,producer没有直接和zookeeper进行通信,但是broker集群会和zookeeper进行进行通信,然后broker集群会把元信息返回给producer;
2,producer在调用send方法的时候会去定时的刷新metadata信息(这自己又些以为,不太明白producer的定时刷新的机制)
3,由于在调用send之前可能会刷新metadata信息,因此可能会有一些延迟。如果不想要该延迟,把topic.metadata.refresh.interval.ms值改为-1,这样只有在发送失败时,才会重新刷新。Kafka的集群中如果某个partition所在的broker挂了,可以检查错误后重启重新加入集群,手动做rebalance,producer的连接会再次断掉,直到rebalance完成,那么刷新后取到的连接着中就会有这个新加入的broker。
除了上面说的之外,kafka还提供了新的producer写法,见http://kafka.apache.org/documentation.html#producerapi
参考
http://kafka.apache.org/08/configuration.html
http://www.oschina.net/translate/kafka-design?lang=chs&page=4#
http://blog.csdn.net/lizhitao/article/details/38438123
http://blog.csdn.net/jewes/article/details/42809641
http://blog.csdn.net/tzwjava/article/details/39930715
kafka consumer group总结
kafka消费者api分为high api和low api,目前上述demo是都是使用kafka high api,高级api不用关心维护消费状态信息和负载均衡,不用关心offset。高级api的一些注意事项:
1. 如果consumer group中的consumer线程数量比partition多,那么有的线程将永远不会收到消息。
因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数
2,如果consumer group中的consumer线程数量比partition少,那么有的线程将会收到多个消息。并且不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,
3,增减consumer,broker,partition会导致rebalance,所以rebalance后consumer对应的partition会发生变化
4,High-level接口中获取不到数据的时候是会block的
关于consumer group(high api)的几点总结:
1,以consumer group为单位订阅 topic,每个consumer一起去消费一个topic;
2,consumer group 通过zookeeper来消费kafka集群中的消息(这个过程由zookeeper进行管理);
相对于low api自己管理offset,high api把offset的管理交给了zookeeper,但是high api并不是消费一次就在zookeeper中更新一次,而是每间隔一个(默认1000ms)时间更新一次offset,可能在重启消费者时拿到重复的消息。此外,当分区leader发生变更时也可能拿到重复的消息。因此在关闭消费者时最好等待一定时间(10s)然后再shutdown。
3,consumer group 设计的目的之一也是为了应用多线程同时去消费一个topic中的数据。
例子:
import kafka.consumer.ConsumerIterator;
import kafka.consumer.KafkaStream;
public class ConsumerTest implements Runnable {
private KafkaStream m_stream;
private int m_threadNumber;
public ConsumerTest(KafkaStream a_stream, int a_threadNumber) {
m_threadNumber = a_threadNumber;
m_stream = a_stream;
}
public void run() {
ConsumerIterator it = m_stream.iterator();
while (it.hasNext())
System.out.println("Thread " + m_threadNumber + ": " + new String(it.next().message()));
System.out.println("Shutting down Thread: " + m_threadNumber);
}
}
//配置连接zookeeper的信息
private static ConsumerConfig createConsumerConfig(String a_zookeeper, String a_groupId) {
Properties props = new Properties();
props.put("zookeeper.connect", a_zookeeper); //zookeeper连接地址
props.put("group.id", a_groupId); //consumer group的id
props.put("zookeeper.session.timeout.ms", "400");
props.put("zookeeper.sync.time.ms", "200");
props.put("auto.commit.interval.ms", "1000");
return new ConsumerConfig(props);
}
//建立一个消费者线程池
public void run(int a_numThreads) {
Map topicCountMap = new HashMap();
topicCountMap.put(topic, new Integer(a_numThreads));
Map>> consumerMap = consumer.createMessageStreams(topicCountMap);
List> streams = consumerMap.get(topic);
// now launch all the threads
//
executor = Executors.newFixedThreadPool(a_numThreads);
// now create an object to consume the messages
//
int threadNumber = 0;
for (final KafkaStream stream : streams) {
executor.submit(new ConsumerTest(stream, threadNumber));
threadNumber++;
}
}
//经过一段时间后关闭
try {
Thread.sleep(10000);
} catch (InterruptedException ie) {
}
example.shutdown();