Python爬取CSDN,获取个人博客信息
最近自己空余时间在学习CPDA相关的知识,不过不打算考证,毕竟报名费用要8800(此处吐血三升)。不过相关资料倒是挺多的,感觉很有意思,也很适合自己,就拿来学学了。
但是作为数据分析师,前提肯定是需要能得到大量数据。现在获取数据的最快方法就是在网络上爬取,所以自己就学习了下如何使用Python在网络上爬取数据。既然常常在CSDN上混,那就先从爬取CSDN的数据开始吧。
代码和思路上参考了:https://blog.csdn.net/xingjiarong/article/details/50659381。特表示感谢!
Python爬取信息的基本原理就是访问相关网址,将获取到的信息(主要是html源码)的内容进行筛选整理。所以爬取信息首先是要看所要访问网页的源码。比如下图是我的博客主页:
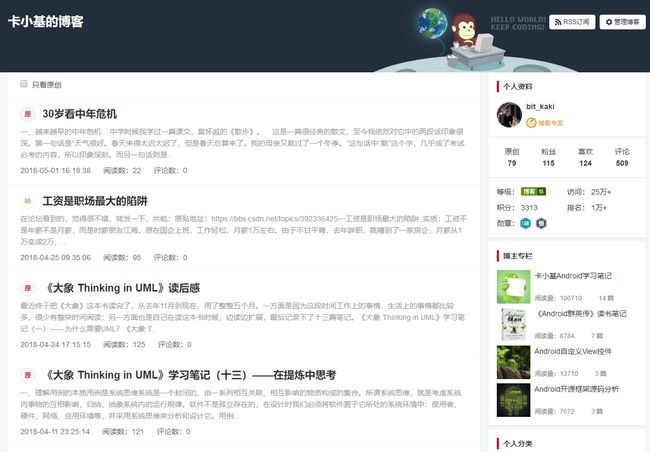
邮件点击空白地方,选择查看源代码,就可以看到该页面的html源码。如下所示:

接下来我就思考我要来爬取一些什么内容。首先就是我的总体信息,包括总的访问量,粉丝,排名等等。于是我们在源代码里找到相关的代码:

以及我每篇博客的访问量,评论数等情况,源码如下:

除了爬取的数据以外,其他还需要注意的有以下几点:
1.需要伪装成浏览器访问,直接访问的话csdn会拒绝;
2.在页面中查找最后一页,这里我没想到更好的方法,用了我博客的最后一页的一个标签。
附上源代码:
#!usr/bin/python
#coding: utf-8
'''
Created on 2018年5月9日
@author: kaki
使用python爬取csdn个人博客信息
'''
import urllib2
import re
import sys
#当前的博客列表页号
page_num = 1
#不是最后列表的一页
notLast = []
account = str(raw_input('print csdn id:'))
#首页地址
baseUrl = 'http://blog.csdn.net/'+account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+'/article/list/'+str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent}
#构造请求
req = urllib2.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
type=sys.getfilesystemencoding()
myPage = myPage.decode("UTF-8").encode(type)
#获取总体信息
#利用正则表达式来获取博客的标题
title = re.findall('(.*?) ',myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items).lstrip().rstrip())
print '%s %s' % ('标题'.decode('utf8').encode('gbk'),titleList[0])
#利用正则表达式来获取博客的数量
num = re.findall('(.*?) ',myPage,re.S)
numList=[]
for items in num:
numList.append(str(items).lstrip().rstrip())
#利用正则表达式来获取粉丝的数量
fan = re.findall('(.*?) ',myPage,re.S)
fanList=[]
for items in fan:
fanList.append(str(items).lstrip().rstrip())
#输出原创、粉丝、喜欢、评论数
print '%s %s %s %s %s %s %s %s' % ('原创'.decode('utf8').encode('gbk'),numList[0],'粉丝'.decode('utf8').encode('gbk'),fanList[0],'喜欢'.decode('utf8').encode('gbk'),numList[1],'评论'.decode('utf8').encode('gbk'),numList[2])
#利用正则表达式来获取访问量
fangwen = re.findall('',myPage,re.S)
fangwenList=[]
for items in fangwen:
fangwenList.append(str(items).lstrip().rstrip())
#利用正则表达式来获取排名
paiming = re.findall('',myPage,re.S)
paimingList=[]
for items in paiming:
paimingList.append(str(items).lstrip().rstrip())
#输出总访问量、积分、排名
print '%s %s %s %s %s %s' % ('总访问量'.decode('utf8').encode('gbk'),fangwenList[0],'积分'.decode('utf8').encode('gbk'),fangwenList[1],'排名'.decode('utf8').encode('gbk'),paimingList[0])
#获取每一页的信息
while not notLast:
#首页地址
baseUrl = 'http://blog.csdn.net/'+account
#连接页号,组成爬取的页面网址
myUrl = baseUrl+'/article/list/'+str(page_num)
#伪装成浏览器访问,直接访问的话csdn会拒绝
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = {'User-Agent':user_agent}
#构造请求
req = urllib2.Request(myUrl,headers=headers)
#访问页面
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
type=sys.getfilesystemencoding()
myPage = myPage.decode("UTF-8").encode(type)
#在页面中查找最后一页,这里我用了我博客的最后一页的一个标签
notLast = re.findall('android.media.projection',myPage,re.S)
print '-----------------------------the %d page---------------------------------' % (page_num,)
#利用正则表达式来获取博客的标题
title = re.findall('(.*?)',myPage,re.S)
titleList=[]
for items in title:
titleList.append(str(items)[32:].lstrip().rstrip())
#利用正则表达式获取博客的访问量
view = re.findall('(.*?)',myPage,re.S)
viewList=[]
for items in view:
viewList.append(str(items).lstrip().rstrip())
#将结果输出
for n in range(len(titleList)):
print '%s %s %s' % (viewList[n*2-2],viewList[n*2-1],titleList[n])
#页号加1
page_num = page_num + 1fushang
附上部分结果图:
