Ubuntu Server安装Apache Hadoop
“千里之行,始于足下。”学习任何东西都是这样。本文所需环境:Linx(Ubuntu server15.04),Hadoop(hadoop-2.7.2),OS(windows amd 64)
1.安装Java JDK
Hadoop运行依赖环境,安装JDK6及以上版本。首先检查是否存在JDK.
java -version下面表示已经安装了:

root@ubuntu:~# java -version
java version "1.7.0_95"
OpenJDK Runtime Environment (IcedTea 2.6.4) (7u95-2.6.4-0ubuntu0.15.04.1)
OpenJDK 64-Bit Server VM (build 24.95-b01, mixed mode)如果没有安装,可以使用以下命令来安装:
#首先更新apt-get命令
apt-get update
#安装jdk:你可以使用jps命令查看是否安装支持jps的jdk版本,jps命令Java1.5以上版本支持
jps
#如果不存在会提示jdk的版本,输入如下命令进行安装
apt-get install openjdk-7-jdk
2.安装Apache Hadoop需要做的准备工作
2.1创建专用用户
Hadoop需要一个单独的专用用户来执行。 具有对Hadoop可执行文件和数据文件夹的完全控制。要创建新用户,请在终端中使用以下命令。
#create a user group for hadoop
sudo addgroup hadoop
#create user hduser and add it to the hadoop usergroup
sudo adduser --ingroup hadoop hduser 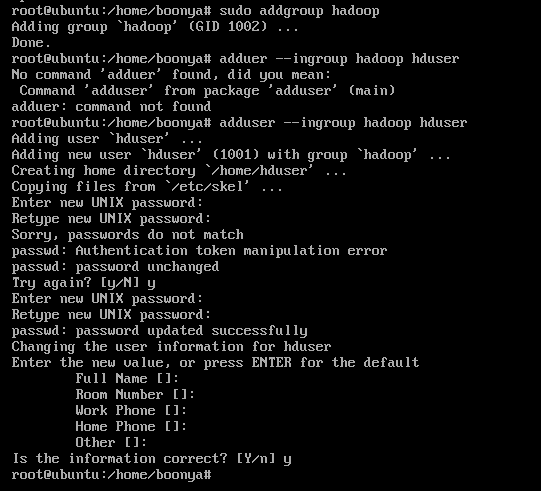
直接默认按Enter即可。
2.3禁用ipv6
下一步是在所有机器上禁用ipv6。 Hadoop设置为使用ipv4,这就是为什么我们需要在创建hadoop集群之前禁用ipv6。使用vi(或您选择的任何其他编辑器,如:nano)以root身份打开/etc/sysctl.conf:
vi /etc/sysctl.conf并在文件末尾添加以下行:
#commands to disable ipv6
net.ipv6.conf.all.disable-ipv6=1
net.ipv6.conf.default.disable-ipv6=1
net.ipv6.conf.lo.disable-ipv6=1 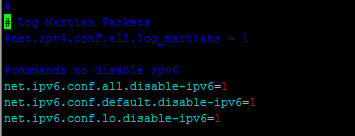
vi命令——i:进行编辑 ;ESC :wq 保存退出
要检查ipv6是否正确禁用,我们可以使用以下命令:
cat /proc/sys/net/ipv6/conf/all/disable-ipv6
2.4安装SSH和设置证书
Hadoop需要SSH访问来管理其远程节点以及本地机器上的节点。对于此示例,我们需要配置SSH访问localhost。
因此,我们将确保我们已经启动并运行SSH并设置公钥访问权限,以允许它在没有密码的情况下登录。 我们将设置SSH证书以允许密码较少的身份验证。使用以下命令执行所需的步骤。
ssh有两个主要组件:
- ssh:我们用来连接远程机器的命令 - 客户端
- sshd:在服务器上运行并允许客户端连接到服务器的守护程序
SSH在Ubuntu上预先启用,但为了确保sshd启用,我们需要使用以下命令首先安装ssh。
#installing ssh
sudo apt-get install ssh 要确保一切都正确设置,请使用以下命令:
root@ubuntu:~# which ssh
/usr/local/ssh
root@ubuntu:~# which sshd
/usr/local/sshd现在,为了生成ssh证书,我们将切换到hduser用户。在以下命令中,我们保持密码为空,同时生成ssh的密钥,如果您愿意,可以给它一些密码。
#change to user hduser
su hduser
#generate ssh key
ssh-keygen -t rsa -P "" 
第二个命令将为机器创建一个RSA密钥对。 此键的密码将为空,如命令中所述。它将要求存储密钥的路径,默认路径为$ HOME / .ssh / id-rsa.pub,当提示保持同一路径时,按Enter键。如果您计划更改路径,请记住它,因为它将在下一步中需要。
使用上一步中创建的密钥启用对机器的SSH访问。为此,我们必须将密钥添加到机器的授权密钥列表。
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys 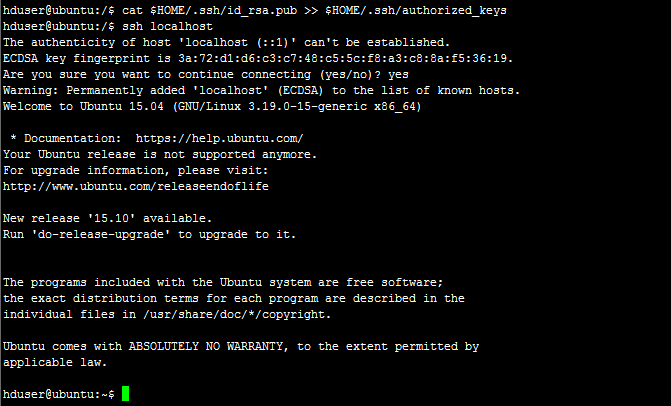
我们可以检查ssh是否工作如下,是ssh到localhost成功没有密码提示,然后证书正确启用。
ssh localhost到目前为止,我们已经完成了Apache Hadoop的所有先决条件。我们将在下一节中检查如何设置Hadoop。
3.安装Apache Hadoop
3.1 wget下载Hadoop
wget http://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
3.2解压并修改用户分组权限
1.创建usr/local/hadoop文件夹
mk /usr/local/hadoop2.将./路径下的hadoop-2.7.2.tar.gz的文件拷贝到usr/local/hadoop文件夹
cp hadoop-2.7.2.tar.gz /usr/local/hadoop/hadoop-2.7.2.tar.gz3.解压 hadoop-2.7.2.tar.gz
tar -zxf /usr/local/hadoop/hadoop-2.7.2.tar.gz4. 更改文件夹的所有者为hduser和hadoop组
chown -R hduser:hadoop /usr/local/hadoop3.2更新bash
1.更新用户hduser的bashrc文件。
su hduser
vi $HOME/.bashrc 2. 在文件末尾,添加以下行。
export HADOOP_HOME=/usr/local/hadoop
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
#Some convenient aliases
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
export PATH=$PATH:$HADOOP_HOME/bin 方便别名的块是可选的,可以省略。 JAVA_HOME,HADOOP_HOME和PATH是唯一的强制要求。
3.3配置Hadoop
在这一步中,我们将配置Hadoop。
1.在/ usr / local / hadoop / etc / hadoop中打开hadoop-env.sh并设置JAVA_HOME变量,如下所示:
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64 注意:到java的路径应该是java在系统中存在的路径。默认情况下,它应该在/ usr / lib/jvm文件夹中,但确保它是根据您的系统的正确路径。此外,确保您要使用的java版本是正确的。下面的截图显示了需要在hadoop-env.sh中修改它的位置。
2.接下来,我们将在/ usr / local / hadoop / etc / hadoop /文件夹中配置core-site.xml,并添加以下属性
fs.defaultFS
hdfs://localhost:54310
3.接下来,我们需要更新hdfs-site.xml。此文件用于指定将用作namenode和datanode的目录。
dfs.replication
2
dfs.namenode.name.dir
/usr/local/hadoop/hdfs/namenode
dfs.datanode.data.dir
/usr/local/hadoop/hdfs/datanode
4.现在,我们将更新mapred-site.xml文件。文件夹/ usr / local / hadoop / etc / hadoop /包含文件mapred-site.xml.template。在修改之前将此文件重命名为mapred-site.xml。
mapreduce.jobtracker.address
localhost:54311
3.4格式化Apache Hadoop文件系统
我们现在完成所有的配置,所以在启动集群之前,我们需要格式化namenode。为此,请在终端上使用以下命令。
hdfs namenode -format此命令应该在控制台输出上没有任何错误的情况下执行。如果它没有任何错误地执行,我们很好在我们的Ubuntu系统上启动Apache Hadoop实例。
3.5启动Apache Hadoop
现在是开始Hadoop的时候了。以下是这样做的命令:
/usr/local/hadoop/sbin/start-dfs.sh注:可能会遇到执行文件Permission Denied,只需要对hduser 相关路径和类型的文件权限就可以了。
chmod 777 /usr/local/hadoop/sbin/start-dfs.sh
一旦dfs启动没有任何错误,我们可以使用命令jps检查一切是否正常工作
cd /usr/local/hadoop/sbin
#Checking the status of the Hadoop components
jps 
用http://192.168.234.128:50070上的Namenode的Web界面检查Apache Hadoop的状态。

3.5停止Apache Hadoop
现在是开始Hadoop的时候了。以下是这样做的命令:
/usr/local/hadoop/sbin/stop-dfs.sh至此Ubuntu Server安装Apache Hadoop结束!