Airflow
Airflow
- 1 前言
- 2 概述
- 2.1 特性
- 2.2 与OOZIE比较
- 3 概念
- 3.1核心概念
- 3.1.1 DAG(Directed Acyclic Graph有向无环图)
- 3.1.2 作用域(scope)
- 3.1.3 默认参数(Default Arguments)
- 3.1.4 执行器(Operators)
- 3.1.5 任务(task)
- 3.2 附加功能
- 3.2.1 Hooks
- 3.2.2 Pools
- 3.2.3 Connections
- 3.2.4 Xcom
- 3.2.5 Variables
- 3.2.6 Branching
- 3.2.7 SubDAGs
- 3.2.8 SLAs
- 3.2.9 Trigger Rules
- 3.2.10 .airflowignore
- 4 命令行
- 5 下载、安装、启动
- 5.1 Python2.7
- 5.2 pip
- 5.3 setuptools
- 5.4 airflow
- 5.5 创建元数据库
- 5.6 配置文件
- 5.7 初始化
- 5.8 启动
- 6 教程
- 6.1 测试dag
- 7 调度与触发规则(Scheduling & Triggers)
- 7.1 DAG Runs
- 7.2 Backfill and Catchup
- 7.3 外部触发(External Triggers)
- 7.4 并行度(parallelism)
- 8 插件
- 9 安全性(Security)
- 9.1 flask-admin
- 9.2 RBAC
- 10 时区
- 10.1 Naive and aware datetime objects
- 10.2 Interpretation of naive datetime objects
- 11 operators
- 12 Celery分布式集群搭建
- 12.1 airflow安装
- 12.2 rabbitMQ
- 12.3 HAProxy
- 12.4 ASFC
- 12.5 airflow集群启动顺序
1 前言
本文只是对官网的部分翻译和使用过程中的一些体验,如若有误,还请赐教
2 概述
Airflow是一个描述,执行、调度和监控工作流的平台工具。
使用Airflow定义任务的DAG作为工作流。Airflow调度根据你定义的依赖关系执行你的任务。丰富的命令行可以在DAG上进行一系列复杂的操作,丰富的UI将使工作流pipeline更加可视化,更易监控,更易维护,快速定位问题。
2.1 特性
- 动态的:airflow pipeline通过python代码配置,允许动态的pipeline生成,这使得airflow可以通过写python代 码动态初始化pipeline。
- 优雅的:airflow简洁明晰,使用jinja模板语言使你的脚本参数化。
- 可伸缩:可以很容易的自定义operators,executors,扩展代码库来适应你的开发环境。
- 可扩展:airflow有一个模块化的架构,且可以使用消息队列来扩展任意多个workers。
2.2 与OOZIE比较
- 优点
| option | OOZIE | Airflow | Comment |
|---|---|---|---|
| 自定义 | 难 | 本质作为python的第三方模块,可以根据业务场景修改源码 | |
| 界面交互 | 无 | 有非常友好的WebUI,可以查看,重跑task,Graph和Tree可以直观的展示task的依赖关系等。还有简单的数据分析如Duration,Tries,Grantt。Chart组件支持自定义数据分析的sql | |
| 日志 | 需要点击很多层级才能看到,且日志有丢失现象 | 日志更直观,基本只需点一次就能看到。不会丢失,且可以选择存储在本地,Amazon,Google cloud | |
| 权限管理 | 针对每个workflow | 只针对WebUI,用户有5中角色,对应不同的权限。由于dag文件和业务代码放在本地,所以其权限管理依赖于linux | |
| 重启 | workflow和coordinate有更新必须重启 | 只有airflow.cfg配置文件更新需要重启服务 | |
| 触发规则 | 时间和数据 | 时间,目录,文件,hive分区,其他dag的task等,支持自定义 | |
| 组织形式 | workflow层级 | dag和subdag | |
| 并行度 | 不清楚 | 可以通过airflow.cfg设置,默认16(同一时间最多16个task) | |
| sla监控 | 只有启用开关 | 可以作为参数传入dag,设置task运行时长,超时会发邮件 | |
| 数据交互 | 只负责调度,数据库由业务决定 | Connection模块支持大部分主流数据库,且可以自定义hook |
- 缺点与问题
- 时区:虽然airflow支持配置默认时区,但WebUI的时间是UTC时间(+00:00,上海市+08:00),无法改变,会给用户造成凌乱的错觉
- weekly scheduler:airflow的周调度只能执行周期的开始日期。想要执行周期的结束日期要用必须execution_date+timedelta(7)
3 概念
3.1核心概念
3.1.1 DAG(Directed Acyclic Graph有向无环图)
在airfow里,一个dag表示所有task的集合,这些task之间存在单向依赖关系,不能闭环,如A->B->D,C->D。否则会报错(A->B->D->A)。
3.1.2 作用域(scope)
只有作用域是全局的DAG才能百airflow识别,如下:
dag_1 = DAG('this_dag_will_be_discovered')
def my_function():
dag_2 = DAG('but_this_dag_will_not')
my_function()
dag_1 可以被识别,dag_2不行
3.1.3 默认参数(Default Arguments)
如果DAG()里传入default_args,那么它将作用域其下所有的operators。如果你对所有operators有一些共通的设置,那么可以用default_args来传入而不用在每个operator里。
3.1.4 执行器(Operators)
用于描述DAG下的task做什么样的操作(如执行hive脚本,导入数据,监控路径)。
大多情况下一个operator执行单个task,是DAG的最小单位,具有原子性,不能喝其他的operator分享信息和资源。它们按照依赖关系依次执行。如果需要分享信息和资源,首先考虑合并operators。如果不行,可以使用XCom,它可以在operator之间分享信息和资源。
Airflow支持自定义operator,需要继承BaseOperator。
3.1.5 任务(task)
一旦operator被实例化,将被视作一个task
3.2 附加功能
Airflow除了上述的核心概念,还提供很多额外的功能,如:资源的连接限制,交叉通信,条件执行等。
3.2.1 Hooks
Hooks是一个用于连接外部平台和数据库(hive,mysql,HDFS等)的接口。所有的连接信息存储在Connection表里。大多数operator与hook是一一对应的关系。
3.2.2 Pools
有时系统可能会被多进程造成的资源短缺等原因搞垮。airflow pools用于设置task执行的并行度
3.2.3 Connections
所有外部平台和数据库的连接信息都存在Connection表里,可以在airflow web的menu-Admin-Connections里查看管理。airlfow init的时候生成了若干默认的连接信息,可以在其基础上增删改查,conn_id是主键。很多hooks都有默认的conn_id值,不需要再明确声明
3.2.4 Xcom
3.2.5 Variables
3.2.6 Branching
3.2.7 SubDAGs
我们可以将相同或相似的task聚成一个dag,作为主dag的子dag。subdagoperator必须包含一个工厂方法来返回dag对象,代表subdag将被主dag当做dag。在webUI里,subdag operator比其它operator多个"Zoom into sub DAG"按钮。目前我对subdag理解,是方便task的组织,理清task的依赖关系,类似于oozie的层级。
- subdag的dag_id必须以父dag_id为前缀,且用逗点 . 隔开的。如dmp.dmp_agent_behavior
- 可以通过subdagoperator将父dag的参数变量传入subdag,如start_date
- subdag必须有schedule_interval,如果没有或者设置为
@once,subdag将不做任何事情且状态置为success- 清除subdag的状态也将清除其包含的task的状态。(根据我的使用,清除subdag时,如果不选Downstream,则只清除subdag自己;如果选择Downstream,则清除其包含的task的状态)
- subdag的状态标记为success时不影响其包含的task的状态
- subdag里不要使用
depends_on_past=True- subdag默认使用SequentialExecutor,task将顺序执行。如果用户传入LocalExecutor则可能出现问题。(根据我的使用,airflow.cfg里配置了LocalExecutor的话,subdag使用LocalExecutor没有问题。官网说可能有问题应该是指配置文件用CeleryExecutor的情况下subdag用LocalExecutor)
官网:https://airflow.apache.org/concepts.html#subdags
3.2.8 SLAs
3.2.9 Trigger Rules
默认情况下根据task的依赖关系,上游task成功执行才会触发下游task。airflow还支持更复杂的触发机制。
所有的operators都有trigger_rule变量,定义了task将在什么样的条件下被触发执行。默认值是all_success。
- all_success: 所有父task成功 (默认值)
- all_failed: 所有父task失败
- all_done: 所有父task执行完成(不管成功与否)
- one_failed: 只要有一个父task失败
- one_success: 只要有一个父task成功
- none_failed: 所有父task不失败(包括all_success和skipped两种)
- dummy: 依赖只是为了在webUI上显示,随意触发
3.2.10 .airflowignore
用户可以在DAG_FOLDER(如/home/airflow/airflow/dags)下创建一个.airflowignore文件,该文件可以定义一些正则表达式。如果DAG_FOLDER下的python文件被这些正则表达式匹配到,airflow将不会读取这些python文件。例如:
project_a
tenant_[\d]
这样的话,DAG_FOLDER下诸如“project_a_dag_1.py”, “TESTING_project_a.py”, “tenant_1.py”, “project_a/dag_1.py”, and “tenant_1/dag_1.py” 这样的文件将被忽略。.airflowignore的作用域包含当前DAG_FOLDER及其子目录。
4 命令行
airflow有丰富的命令行来操作dag,启动服务,测试等。
官网链接
5 下载、安装、启动
5.1 Python2.7
如果你的系统环境比较干净,可能需要预装以下rpm包
zlib-devel,readline-devel,sqlite-devel,bzip2-devel.i686,openssl-devel.i686,gdbm-devel.i686,libdbi-devel.i686,ncurses-libs,zlib-devel.i686,mysql-devel,cyrus-sasl-devel
官网下载对应本:https://www.python.org/downloads/
tar -xzvf Python-2.7.7.tgz
cd Python-2.7.7
./configure --prefix=/usr/local/python2.7 --enable-shared -enable-unicode=ucs4 (–prefix表示安装路径)
make
make install
如果出现以下错误:
python: error while loading shared libraries: libpython2.7.so.1.0: cannot open shared object file: No such file or directory
执行 cd /etc/ld.so.conf.d/
echo “/usr/local/python2.7/lib” > python2.7.conf
ldconfig
这是因为python运行需要动态加载相关的库,上述命令的意思是告诉python运行需要的库所在位置.ldconfig用于在默认配置文件目录/etc/ld.so.conf.d下读取用户编辑的配置文件
5.2 pip
wge thttps://pypi.python.org/packages/source/p/pip/pip-1.3.1.tar.gz --no-check-certificate
tar xvf pip-1.3.1.tar.gz
python2.7 pip-1.3.1/setup.py install
pip install --upgrade pip
5.3 setuptools
pip2.7 install setuptools(如果是19版,务必升级到40,否则按照会出错pip install --upgrade setuptools)
5.4 airflow
useradd -m airflow (-m自动创建家目录,创建专门的用户来运行airflow)
passwd airflow(修改密码)
SLUGIFY_USES_TEXT_UNIDECODE=yes pip2.7 install apache-airflow[all]==1.10.1(root用户)
由于airflow将用于生产环境,推荐使用[all]下载所有相关的subpackage
- EnvironmentError: mysql_config not found.
可能缺mysql-devel包, yum install mysql-devel- sasl/saslwrapper.h:22:23: error: sasl/sasl.h: No such file or directory.
则执行yum install gcc-c++ python-devel.x86_64 cyrus-sasl-devel.x86_64- /usr/local/python2.7/lib/python2.7/site-packages/pysqlite2/_sqlite.so:undefined symbol: sqlite3_stmt_readonly.
执行以下命令查看问题
nm /usr/local/python2.7/lib/python2.7/site-packages/pysqlite2/_sqlite.so | grep sqlite3_stmt_readonly(查看该文件里是否有次方法)
ldd /usr/local/python2.7/lib/python2.7/site-packages/pysqlite2/_sqlite.so(查看该文件所依赖的库, ldd[list dynamic dependencies])
nm /usr/lib64/libsqlite3.so.0 | grep sqlite3_stmt_readonly 结果[nm: /usr/lib64/libsqlite3.so.0: no symbols]
以上的意思是_sqlite.so所依赖的库(/usr/lib64/libsqlite3.so.0)里没有sqlite3_stmt_readonly方法,下载最新的libsqlite3安装更新
安装完成后,执行airflow命令,HOME目录在执行安装命令的用户的根目录下(如用户是airflow,则/home/airflow/airflow)
5.5 创建元数据库
airflow需要一个数据库进行初始化。如果仅仅是体验学习airflow,则不需要进行配置,使用默认的SQlite即可。
create user airflow;
update user set Password=PASSWORD('airflow') where user = 'airflow';
create database airflow;
GRANT all privileges on airflow.* TO 'airflow'@'%' IDENTIFIED BY 'airflow' with grant option;(通过airflow验证,将airflow数据库下所有表的所有权限分配给在任何机器上登录的airflow用户)
5.6 配置文件
[core]
executor = LocalExecutor (执行引擎)
sql_alchemy_conn = mysql+mysqldb://airflow:[email protected]/airflow (DB url)
default_timezone = Asia/Shanghai(修改默认时区(UTC->Asia/Shanghai))
以上为必须配置项,如果需要发送邮件等功能,则修改其他配置项
例如增加发送钉钉的功能:
webhook = https://oapi.dingtalk.com/robot/send?access_token=xxxxxxxxxxxx (要发送到钉钉群的唯一标识)
at_mobiles = xxxxxxxxxxx,xxxxxxxxxxx (群里要@的人的手机号)
5.7 初始化
airflow initdb
执行此命令,将在配置文件里指定的数据库创建一系列的表,用于存储airflow的元数据,如log,dag,task_instance
可能出现以下问题:
- incorrect date value ‘2018-12-30 09:09:09+00:00’ from column XXX.
如果出现此错误,则实行select @@sql_mode查看是否有STRICT_TRANS_TABLES.若有则去掉.该模式值的意思是:在该模式下,如果一个值不能插入到一个事务表中,则中断当前的操作,对非事务表不做任何限制- show variables like ‘explicit_defaults_for_timestamp’,如果该参数是关闭状态,则打开
5.8 启动
nohup airflow webserver -p 8880 >> /home/airflow/airflow/webserver.log 2>&1 & (启动webserver服务)
nohup airflow scheduler >> /home/airflow/airflow/scheduler.log 2>&1 & (启动scheduler服务)
nohup airflow worker >> /home/airflow/airflow/worker.log 2>&1 & (启动worker,此项只有CeleryExecutor时适用)
ps -ef | grep -Ei 'airflow' | grep -v 'grep' | grep -v 'fix_airflow' | grep -v 'root' | grep -v 'bash' | awk '{print $2}' | xargs -i kill {} (杀死airflow的所有服务)
请求"/health"可以查看airflow实例的运行状态,如:http://hostname:port/health .如果良好会返回"The server is healthy!"
6 教程
下面是一个简单的示例
# tutorial.py
from airflow import DAG #用于初始化DAG对象
from airflow.operators.bash_operator import BashOperator #众多operators的一种,用于执行bash命令
from datetime import datetime, timedelta #日期时间相关的包
#当创建DAG对象或者task时,可以明确地传递一系列的参数来描述它。可以定义一个字典来实现。default_args作用于该DAG下的所有task
default_args = {
'owner': 'airflow',
'depends_on_past': False, #task的触发执行是否依赖过去的状态
'start_date': datetime(2015, 6, 1), #此DAG开始执行的日期
'email': ['[email protected]'], #任务失败时用于接受邮件
'email_on_failure': False, #任务失败是是否接收邮件
'email_on_retry': False, #任务重试时是否接收邮件
'retries': 1, #重试次数
'retry_delay': timedelta(minutes=5), #重试间隔
# 'queue': 'bash_queue',
# 'pool': 'backfill',
# 'priority_weight': 10,
# 'end_date': datetime(2016, 1, 1),
}
#初始化DAG对象
dag = DAG(
'tutorial', #dag_id唯一标示
default_args=default_args,
schedule_interval=timedelta(days=1) #DAG schedule间隔,支持cron格式(0 7 * * *)
)
#task任务
t1 = BashOperator(
task_id='print_date', #task_id唯一标示
bash_command='date', #具体的bash命令
dag=dag)
t2 = BashOperator(
task_id='sleep',
bash_command='sleep 5',
retries=3, #task里传递的参数值优先于dag(此task的重试次数是3而不是1)
dag=dag)
#airflow支持jinja模板语言
templated_command = """
{% for i in range(5) %}
echo "{{ ds }}"
echo "{{ macros.ds_add(ds, 7)}}"
echo "{{ params.my_param }}"
{% endfor %}
"""
t3 = BashOperator(
task_id='templated',
bash_command=templated_command,
params={'my_param': 'Parameter I passed in'},
dag=dag)
#设置依赖关系
t2.set_upstream(t1) #等价于 t1.set_downstream(t2),t2 << t1,t1 >> t2
t3.set_upstream(t1)
#task列表也可以设置依赖关系
t1.set_downstream([t2, t3])
t1 >> [t2, t3]
[t2, t3] << t1
这基本是一个DAG对象的骨架,DAG()除了上述列出之外还有很多的参数可以设置,来提高task的运行效率。operators同理,除了最基本的BashOperator还有诸如Hiveoperator,mysql_to_hiveOperator等等,每种operator都有相应的功能,可以根据业务场景任意挑选
6.1 测试dag
python ~/airflow/dags/tutorial.py (如果脚本不报错表示没有语法错误且你的airflow运行环境正常)
airflow list_dags (输出显示可用的dags)
airflow list_tasks tutorial (输出显示tutorial dag下所有的task)
airflow list_tasks tutorial --tree (以树形结构输出显示tutorial dag下所有的task)
airflow test tutorial print_date 2015-06-01 (测试该task是否可以正确运行)
- test命令只是在本地运行task实例,将log输出到标准输出(也就是屏 幕),不会干扰到依赖关系,也不会更新task的状态(running, success, failed…) 到数据库
airflow backfill tutorial -s 2015-06-01 -e 2015-06-07
- backfill刚好与test相反,它会检测你设置的依赖关系,log会写入指定的文件,task状态会更新到数据库
- 如果你设置了depends_on_past=True,那么task实例将依赖于先前的task的执行结果
- -s必选,-e可选
7 调度与触发规则(Scheduling & Triggers)
airflow的scheduler监控所有的dag和task,根据其依赖关系触发执行。在后台, scheduler启动了一个linux子进程来监控DAG_FOLDER目录,收集dag的python文件(.py)和检测可用的task是否可以被触发执行。airflow scheduler被设计为持续性的后台服务来运行,可以用airflow scheduler命令来启动,其将读取airflow.cfg配置文件。
airflow的调度模式是在当前的调度周期触发上一个调度周期,举例说明:
- 对于天调度。一个dag的schedule_interval设置为
0 7 * * *,现在是2019-01-02 08:00:00,那么scheduler执行的最后一个task实例是2019-01-01T07:00:00,而不是2019-01-02T07:00:00- 对于周调度。举例说明:start_date为2019-02-01,schedule_interval为
0 7 * * 1,now是2019-01-11 07:00:00,那么scheduler执行的最后一个task实例是2019-01-04T07:00:00,因为从start_date到2019-01-11期间,只有2019-02-04到2019-02-10是一个完整的周期。如果start_date和now不变,schedule_interval改为0 7 * * 2,则没有实例可执行
7.1 DAG Runs
一个dag run对象代表dag的一个运行实例。
每个dag都可以设置一个schedule_interval,表示其调度的间隔时间。schedule_interval支持cron格式(0 7 * * 0)和datetime.timedelta,或者’preset’
| preset | meaning | cron |
|---|---|---|
| None | 不自动执行调度,用于外部触发的专用 | |
| @once | 执行一次且只有一次 | |
| @hourly | 每小时0分0秒执行一次 | 0 * * * * |
| @daily | 每天00:00:00执行一次 | 0 0 * * * |
| @weekly | 每周日的00:00:00执行一次 | 0 0 * * 0 |
| @monthly | 每月1号的00:00:00执行一次 | 0 0 1 * * |
| @yearly | 每年1月1号的00:00:00执行一次 | 0 0 1 1 * |
注意None的使用,是
schedule_interval=None而不是schedule_interval='None'
7.2 Backfill and Catchup
7.3 外部触发(External Triggers)
airflow dag除了scheduler在后天自动执行外,还可以在命令行airflow trigger_dag和webUI手动触发执行。命令行执行时需要传入run_id。
7.4 并行度(parallelism)
airflow关于并行度在airflow.cfg里有4个配置项:
parallelism: 指整个Airflow在任何一刻能同时运行的Task Instance的数量,这个数量跟DAG无关
max_active_runs_per_dag: 指同一个Dag能被同时激活的Dag Run的数量
dag_concurrency: 指同一个Dag Run中能同时运行的Task Instance的个数
non_pooled_task_slot_count: 指默认的Pool能同时运行的Task Instance的数量,如果你的Task没有指定Pool选项,那么这个Task就是属于这个默认的Pool的
8 插件
airflow提供了简单的插件功能来集成外部的功能特点,只需要把插件文件放入$AIRFLOW_HOME/plugins目录即可。
9 安全性(Security)
airflow提供了多种针对webUI的安全策略如flask-admin,RBAC,Multi-tenancy,Kerberos,GitHub/Google Authentication等。目前我只是用过前两种,稍作说明。
9.1 flask-admin
这是airflow默认的、也是最简单的安全验证模式,只需要在登录webUI前创建user/password即可(创建的所有用户都拥有最高权限,可CRUD)。在airflow初始化前修改配置文件airflow.cfg
[webserver]
authenticate = True
auth_backend = airflow.contrib.auth.backends.password_auth
创建user/password只能通过在python客户端执行以下代码实现
from airflow import models, settings
from airflow.contrib.auth.backends.password_auth import PasswordUser
user = PasswordUser(models.User())
user.username = 'airflow'
user.password = 'airflow'
session = settings.Session()
session.add(user)
session.commit()
session.close()
exit()
9.2 RBAC
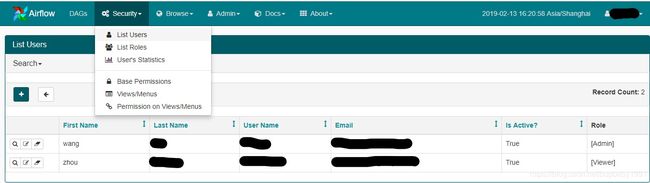
RBAC是一种比flask-admin更加复杂,角色权限更丰富的安全策略。它有五种角色Admin、Op、Public、User、Viewer,每种角色有不同的权限组合,Admin的权限最高,包含所有的权限组合,其他角色只包含部分权限组合,Viewer权限最低,只能查看,不可以进行任何的增删改操作。
在airflow初始化前修改配置文件airflow.cfg
[webserver]
rbac = True
RBAC通过命令行创建用户
airflow create_user -r Admin -u xxxxx -e xxxxxx -f xx -l xx -p xxxxx
登录后可以在如下页面里对用户进行管理
10 时区
airflow从1.9版本开始支持时区,将UTC的日期时间存储到数据库。如果你的项目组要使用airflow,且组员在不同的时区,那么使用UTC时间将非常方便可靠,因为UTC是世界上最标准的时间,不会因为时区而发生改变。即使所有人在同一时区,采用UTC时间也会有很好的体验,最主要的原因是夏令时。很多国家都有夏令时的系统,其时间会在春季调快n小时,在秋季调慢n小时。如果你身处有夏令时的国家,那么有可能每年会出现两次错误(春季和秋季)。这种情况对于普通的业务来说问题不大,但如果业务涉及经济,航空等重要领域时将成为灾难。
我目前使用的是1.10.1版本,其所有时间的计算,存储,WebUI的展示都采用UTC时间,不能转换为本地时间
时区信息配置在airflow.cfg文件里,默认值为UTC,你可以修改为system(自动获取系统所在时区)或者标准时区值,如Asia/Shanghai。
注意: 如果默认时区设置为本地时区,其作用只是在创建dag文件等传入airflow的时间为本地时间,不能控制airflow的时间的计算、存储,更不能改变WebUI展示的时间。例如:设置时区为
Asia/Shanghai,创建dag时schedule_interval='0 7 * * *',那么airflow认为第一个dag run是2019-01-16 07:00:00+08:00而不是2019-01-16 07:00:00+00:00
10.1 Naive and aware datetime objects
Python的datetime.datetime对象有个tzinfo参数来存储时间的时区信息。当此参数有值时,该datetime对象称为aware,反之称为naive。
由于airflow使用time-zone-aware的datetime对象,所以创建dag是要使用time-zone-aware
10.2 Interpretation of naive datetime objects
尽管airflow的计算使用aware datetime,但它在你创建dag设置start_dates和end_dates时仍然会接受naive datetime,此时将使用airflow.cfg里的默认时区,这主要是为了向后兼容。
不幸的是,在夏令时段,有些datetime不存在或者模棱两可。这种情况下pendulum模块可能会报错。这就是为什么要鼓励使用aware datetime。
咱们国家早已废弃夏令时,所以不存在这个问题
11 operators
我们在使用airflow现有的operators时可能会有这样的问题:给某个operator的某个变量传递了模板变量{{ ds }},但执行时没有被识别,还是字符串本身。这是因为airflow的每个operator都定义了template_fields变量,其意思是需要渲染的字段,在执行时会自动渲染这些字段里的模板参数。举例:airflow.operators.mysql_to_hive.MySqlToHiveTransfer里template_fields = (‘sql’, ‘partition’, ‘hive_table’),也就是说执行operator时只有这4个字段里包含的模板参数会被渲染
12 Celery分布式集群搭建
CeleryExecutor支持横向扩展数台worker节点来构建分布式集群。因此我们必须修改airflow.cfg[core]的executor = CeleryExecutor,以及[celery]里各配置项。以下是每个work节点的要求:
- 每台worker节点都必须安装airflow,且
AIRFLOW_HOME下的文件应该一致(可以在一台work节点上配置好后scp到其他节点) - Operators依赖的上下文应该存在于每台work节点上,例如:如果使用
HiveOperator,那么该work节点上必须装有hive cli - 每台work节点的
DAGS_FOLDER应该是同步的。我们可以通过上传git然后同步到集群每个work节点来实现
我们可以通过airflow flower命令行启动一个webUI服务来监控各work几点的运行情况。
假设要搭建的集群服务如下分布:
| host | IP | service | comment |
|---|---|---|---|
| airflow01 | xx.xx.xx.xx1 | webserver/worker/ASFC/Rabbitmq/flower | master |
| airflow02 | xx.xx.xx.xx2 | webserver/worker/ASFC/Rabbitmq | slave |
| airflow03 | xx.xx.xx.xx3 | worker/Haproxy | slave |
ASFC:Airflow Schedule Failover Controller第三方schedule高可用组件
Rabbitmq:消息队列
Haproxy:负载均衡
以下安装步骤均在root用户下运行,启动则各不相同
12.1 airflow安装
上面第5节已经详细讲述了此过程,有一点需要注意,如果是在生产环境,建议使用[all]选项下载所有airflow相关组件。请在每台节点正确安装。
12.2 rabbitMQ
wget https://packages.erlang-solutions.com/erlang/esl-erlang/FLAVOUR_1_general/esl-erlang_18.3-1~centos~6_amd64.rpm
yum install esl-erlang_18.3-1~centos~6_amd64.rpm
wget https://github.com/jasonmcintosh/esl-erlang-compat/releases/download/1.1.1/esl-erlang-compat-18.1-1.noarch.rpm
yum install esl-erlang-compat-18.1-1.noarch.rpm
wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.1/rabbitmq-server-3.6.1-1.noarch.rpm
yum install rabbitmq-server-3.6.1-1.noarch.rpm
Transaction Check Error:
file /usr/bin/epmd from install of xxx1 conflicts with file from package xxx2
则yum remove xxx2再继续yum install xxx1
将master节点airflow01的/var/lib/rabbitmq/.erlang.cookie复制到slave节点同目录下,即服务器必须具有相同的cookie,如果不相同的话,无法搭建集群.
以下是rabbitMQ的3个主要的命令行工具:
- rabbitmq-server:服务器的启动与关闭
- rabbitmq-plugins:插件管理
- rabbitmqctl:服务器管理(如添加用户,权限,集群等)
rabbitMQ服务端口如下:
- client端通信端口
5672 - web ui访问端口
15672 - server间通信端口
25672 - erlang发现端口
4369
在master上执行以下5个command
在安装完rabbitMQ后Management Plugin(提供一个基于HTTP的api,管理和监控rabbitmq服务器)插件已随之安装,我们需要将其打开才可以访问webUI
rabbitmq-plugins enable rabbitmq_management
在两个节点上启动rabbitMQ server
rabbitmq-server -detached
在master上添加用户,为其设置权限
rabbitmqctl add_user airflow airflow(设置用户名和密码)
rabbitmqctl set_user_tags airflow administrator(设置角色)
rabbitmqctl add_vhost airflow(设置虚拟主机,celery_broke_url会用到)
rabbitmqctl set_permissions -p airflow airflow ".*" ".*" ".*"(使airflow用户(后)具有airflow(前)这个vhost所有资源的配置,读,写权限)
rabbitmqctl set_policy -p airflow ha "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'(为集群设置镜像)
在slave上执行下列command以将slave加入master形成集群
rabbitmqctl stop_app(先停止app)
rabbitmqctl join_cluster rabbit@airflow01(将当前slave加入到master)
rabbitmqctl start_app(重启app)
rabbitmqctl cluster_status(查看集群状态)
登录http://master:15672 查看和监控集群
至此rabbitMQ安装完毕
注意!!! 请根据rabbitMQ的安装信息更新airflow.cfg配置文件
[celery]
broker_url = amqp://airflow:airflow@master:5672/airflow (连接MQ集群请使用master host)
result_backend = db+mysql://airflow:airflow@airflow01/airflow(MQ的元数据库)
default_queue = airflow(默认队列)
12.3 HAProxy
haproxy是一个高性能的负载均衡服务,应用在airflow集群是为了负载airflow的webserver,rabbitMQ的webserver和后端server
在airflow03 slave节点上安装haproxy:yum install haproxy
然后修改/etc/haproxy/haproxy.cfg,在文件末尾加入下列内容
listen airflow (监控项的名字,随便写)
bind 0.0.0.0:8880 (要监听的服务的端口,airlfow.cfg的[webserver]的web_server_port)
balance roundrobin (负载策略,如果在default中设置过,可以忽略)
server airflow_webserver_1 airflow01:8880 check (server 给监听server起个名字 serverIP check)
server airflow_webserver_2 airflow02:8880 check
listen rabbitmq-webUI
bind 0.0.0.0:15672
balance roundrobin
server rabbitmq_webui_1 airflow01:15672 check
server rabbitmq_webui_2 airflow02:15672 check
listen rabbitmq-ui
bind 0.0.0.0:5677
balance roundrobin
server rabbitmq_server_1 airflow01:5672 check
server rabbitmq_server_2 airflow02:5672 check
# This sets up the admin page for HA Proxy at port 1936.
listen stats :1936 (haproxy webserver的端口)
mode http (监听模式)
stats enable ()
stats uri / (web页面的访问路径)
stats hide-version (隐藏haproxy的版本信息)
stats refresh 30s (web页面多久刷新一次)
其他配置项的含义可以参照详情了解
启动haproxy服务:haproxy -f /etc/haproxy/haproxy.cfg
至此haproxy安装完毕
12.4 ASFC
因为需要执行ssh命令来启动scheduler服务,所以安装ASFC的前提是在airflow01和airflow02上设置ssh免秘钥登录,此处略过。
下载地址:https://github.com/teamclairvoyant/airflow-scheduler-failover-controller
由于ASFC作为python的第三方包使用,所以下载至$PYTHON_HOME/site-packages,
cd {AIRFLOW_FAILOVER_CONTROLLER_HOME}
pip install -e . (注意逗点)
scheduler_failover_controller init (初始化,会向airflow.cfg末尾追加[scheduler_failover])
scheduler_failover_controller start (启动服务)
注意在start前需要修改两个重要的配置
scheduler_nodes_in_cluster = airflow01,airflow02 (集群的主从node,用逗号隔开)
airflow_scheduler_start_command (启动airflow scheduler服务的命令,注意airflow命令请使用绝对路径,否则无法启动)
其他配置项比较简单,根据自己的需求配置即可
ASFC还提供了简单的命令行工具,执行scheduler_failover_controller -h可以查看
12.5 airflow集群启动顺序
假设rabbitMQ和haproxy已经按照上述启动,首先在所有节点启动work,然后在master上启动flower,webserver、ASFC(就是启动scheduler),至此集群可以正常运行了。