COALESCE
COALESCE函数会依次检查输入的参数,返回第一个不是NULL的参数,只有当传入COALESCE函数的所有的参数都是NULL的时候,函数才会返回NULL。例如, COALESCE(piName,''),如果变量piName为NULL,那么函数会返回'',否则就会返回piName本身的值。
由于这个函数是返回第一个非空的值,所以参数里面必须最少有一个非空的值,如果使用下面的查询,
SELECT COALESCE(NULL,NULL)
将会报错:
消息 4127,级别 16,状态 1,第 1 行
COALESCE 至少有一个参数必须为非 NULL 常量的表达式。
但是,如果传入的参数是某列,该列为空的话不会报错,如:COALESCE(piName,null),如果变量piName为NULL,那么函数会返回null,否则就会返回piName本身的值。
下面的例子给所有的产品按list_price打9折,如果没有list_price,就按最低价MIN_PRICE算。 如果也没有MIN_PRICE,那么sale就是5.
在mysql中,其实有不少方法和函数是很有用的,这次介绍一个叫coalesce的,拼写十分麻烦,但其实作用是将返回传入的参数中第一个非null的值,比如
SELECT COALESCE(NULL, NULL, 1);
-- Return 1
SELECT COALESCE(NULL, NULL, NULL, NULL, NULL, NULL, NULL, NULL, 1);
-- Return 1
如果传入的参数所有都是null,则返回null,比如
SELECT COALESCE(NULL, NULL, NULL, NULL);
-- Return NULL
这个参数使用的场合为:假如某个字段默认是null,你想其返回的不是null,而是比如0或其他值,可以使用这个函数
SELECT COALESCE(field_name,0) as value from table;
SELECT product_id, list_price, min_price,
COALESCE(0.9*list_price, min_price, 5) "Sale"
FROM product_information
WHERE supplier_id = 102050
ORDER BY product_id;
PRODUCT_ID LIST_PRICE MIN_PRICE Sale
---------- ---------- ---------- ----------
1769 48 43.2
1770 73 73
2378 305 247 274.5
2382 850 731 765
3355 5

如果,我想得到这样的结果: ENAME
jiao,DAN,DAN,DAN,
可以这样写SQL语句:
 *************
*************
coalesce
def coalesce(numPartitions:Int,shuffle:Boolean=false):RDD[T]
该函数用于将RDD进行重分区,使用HashPartitioner。
第一个参数为重分区的数目,第二个为是否进行shuffle,默认为false。
repartition
def repartition(numPartitions: Int): RDD[T]
该函数其实就是coalesce函数第二个参数为true的实现。
使用注意
他们两个都是RDD的分区进行重新划分,repartition只是coalesce接口中shuffle为true的简易实现,(假设RDD有N个分区,需要重新划分成M个分区)
1)N < M。一般情况下N个分区有数据分布不均匀的状况,利用HashPartitioner函数将数据重新分区为M个,这时需要将shuffle设置为true。
2)如果N > M并且N和M相差不多,(假如N是1000,M是100)那么就可以将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区,这时可以将shuff设置为false,在shuffl为false的情况下,如果M>N时,coalesce为无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系。
3)如果N > M并且两者相差悬殊,这时如果将shuffle设置为false,父子RDD是窄依赖关系,他们同处在一个stage中,就可能造成Spark程序的并行度不够,从而影响性能,如果在M为1的时候,为了使coalesce之前的操作有更好的并行度,可以讲shuffle设置为true。
例子
scala> var data = sc.textFile("/tmp/lxw1234/1.txt")
data: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[53] at textFile at :21
scala> data.collect
res37: Array[String] = Array(hello world, hello spark, hello hive, hi spark)
scala> data.partitions.size
res38: Int = 2 //RDD data默认有两个分区
scala> var rdd1 = data.coalesce(1)
rdd1: org.apache.spark.rdd.RDD[String] = CoalescedRDD[2] at coalesce at :23
scala> rdd1.partitions.size
res1: Int = 1 //rdd1的分区数为1
scala> var rdd1 = data.coalesce(4)
rdd1: org.apache.spark.rdd.RDD[String] = CoalescedRDD[3] at coalesce at :23
scala> rdd1.partitions.size
res2: Int = 2 //如果重分区的数目大于原来的分区数,那么必须指定shuffle参数为true,//否则,分区数不便
scala> var rdd1 = data.coalesce(4,true)
rdd1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[7] at coalesce at :23
scala> rdd1.partitions.size
res3: Int = 4- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
scala> var rdd2 = data.repartition(1)
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at repartition at :23
scala> rdd2.partitions.size
res4: Int = 1
scala> var rdd2 = data.repartition(4)
rdd2: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[15] at repartition at :23
scala> rdd2.partitions.size
res5: Int = 4多人知道ISNULL函数,但是很少人知道Coalesce函数,人们会无意中使用到Coalesce函数,并且发现它比ISNULL更加强大,其实到目前为止,这个函数的确非常有用,本文主要讲解其中的一些基本使用:
首先看看联机丛书的简要定义:
返回其参数中第一个非空表达式
语法:
COALESCE ( expression [ ,...n ] )
如果所有参数均为 NULL,则 COALESCE 返回 NULL。至少应有一个 Null 值为 NULL 类型。尽管 ISNULL 等同于 COALESCE,但它们的行为是不同的。包含具有非空参数的 ISNULL 的表达式将视为 NOT NULL,而包含具有非空参数的 COALESCE 的表达式将视为 NULL。在 SQL Server 中,若要对包含具有非空参数的 COALESCE 的表达式创建索引,可以使用 PERSISTED 列属性将计算列持久化,如以下语句所示:
- CREATE TABLE #CheckSumTest
- (
- ID int identity ,
- Num int DEFAULT ( RAND() * 100 ) ,
- RowCheckSum AS COALESCE( CHECKSUM( id , num ) , 0 ) PERSISTED PRIMARY KEY
- );
下面来看几个比较有用的例子:
首先,从MSDN上看看这个函数的使用方法,coalesce函数(下面简称函数),返回一个参数中非空的值。如:
- SELECT COALESCE(NULL, NULL, GETDATE())
由于两个参数都为null,所以返回getdate()函数的值,也就是当前时间。即返回第一个非空的值。由于这个函数是返回第一个非空的值,所以参数里面必须最少有一个非空的值,如果使用下面的查询,将会报错:
- SELECT COALESCE(NULL, NULL, NULL)

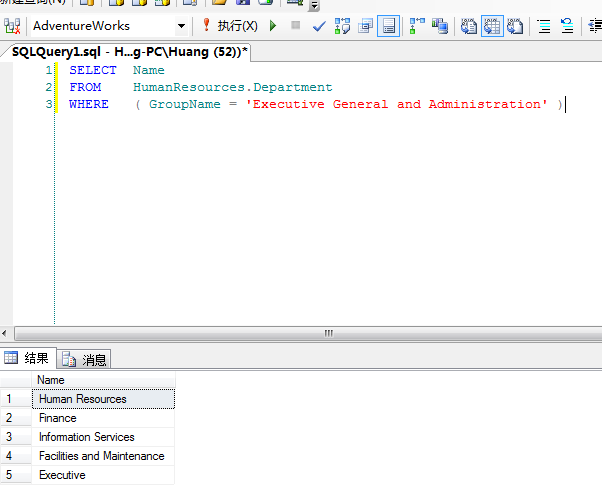
然后来看看把函数应用到Pivot中,下面语句在AdventureWorks 数据库上运行:
- SELECT Name
- FROM HumanResources.Department
- WHERE ( GroupName= 'Executive Generaland Administration' )
会得到下面的结果:
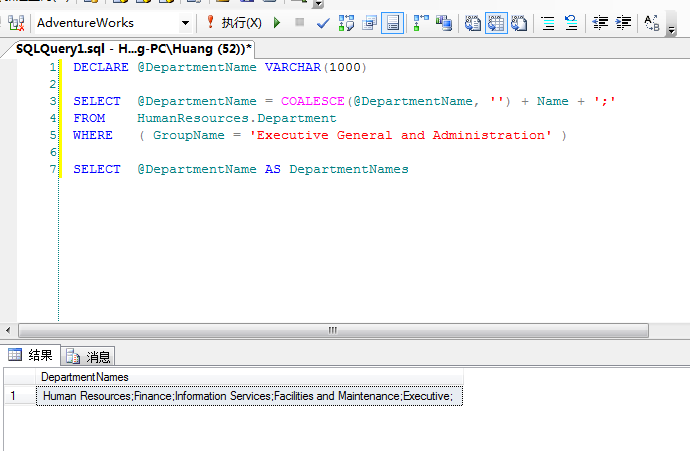
如果想扭转结果,可以使用下面的语句:
- DECLARE @DepartmentName VARCHAR(1000)
- SELECT @DepartmentName = COALESCE(@DepartmentName, '') + Name + ';'
- FROM HumanResources.Department
- WHERE ( GroupName= 'Executive Generaland Administration' )
- SELECT @DepartmentName AS DepartmentNames
使用函数来执行多条SQL命令:
当你知道这个函数可以进行扭转之后,你也应该知道它可以运行多条SQL命令。并且使用分号来区分独立的操作。下面语句是在Person架构下,有名字为Name的列的值:
- DECLARE @SQL VARCHAR(MAX)
- CREATE TABLE #TMP
- (Clmn VARCHAR(500),
- Val VARCHAR(50))
- SELECT @SQL=COALESCE(@SQL,'')+CAST('INSERT INTO #TMP Select ''' + TABLE_SCHEMA + '.' + TABLE_NAME + '.'
- + COLUMN_NAME + ''' AS Clmn, Name FROM ' + TABLE_SCHEMA + '.[' + TABLE_NAME +
- '];' AS VARCHAR(MAX))
- FROM INFORMATION_SCHEMA.COLUMNS
- JOIN sysobjects B ON INFORMATION_SCHEMA.COLUMNS.TABLE_NAME = B.NAME
- WHERE COLUMN_NAME = 'Name'
- AND xtype = 'U'
- AND TABLE_SCHEMA = 'Person'
- PRINT @SQL
- EXEC(@SQL)
- SELECT * FROM #TMP
- DROP TABLE #TMP
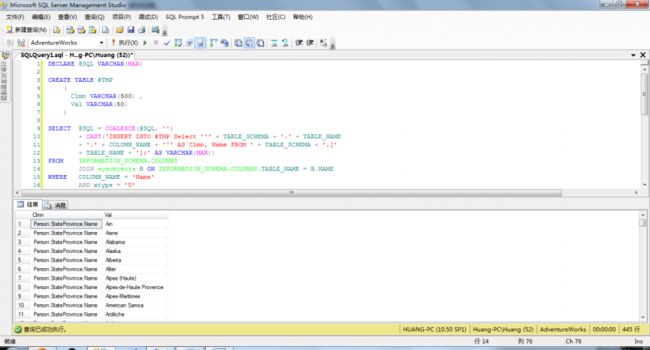
还有一个很重要的功能:。当你尝试还原一个库,并发现不能独占访问时,这个功能非常有效。我们来打开多个窗口,来模拟一下多个连接。然后执行下面的脚本:
- DECLARE @SQL VARCHAR(8000)
- SELECT @SQL = COALESCE(@SQL, '') + 'Kill ' + CAST(spid AS VARCHAR(10)) + '; '
- FROM sys.sysprocesses
- WHERE DBID = DB_ID('AdventureWorks')
- PRINT @SQL --EXEC(@SQL) Replace the print statement with exec to execute
结果如下:
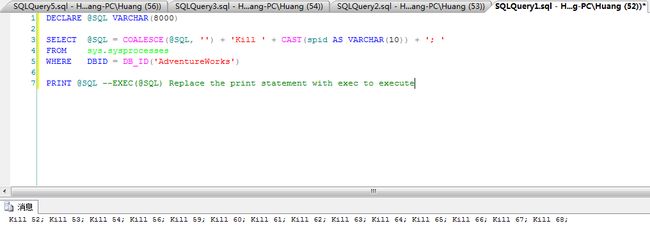
然后你可以把结果复制出来,然后一次性杀掉所有session。