横扫Spark之 - 22个常见的转换算子
水善利万物而不争,处众人之所恶,故几于道
文章目录
-
-
- 1. map()
- 2. flatMap()
- 3. filter()
- 4. mapPartitions()
- 5. mapPartitionsWithIndex()
- 6. groupBy()
- 7. distinct()
- 8. coalesce()
- 9. repartition()
- 10. sortBy()
- 11. intersection()
- 12.union()
- 13. subtract()
- 14. zip()
- 15. partitionBy()
- 16. groupByKey()
- 17. reduceByKey()
- 18. aggregateByKey()()
- 19. sortByKey()
- 20. mapValues()
- 21. join()
- 22. cogroup()
-
1. map()
用于对数据进行映射转换,返回一个新的RDD
操作的是RDD中的每个元素
例:创建一个List集合的RDD,将其中的每个数字映射为二元元组,(“偶数”, 4)、(“奇数”, 1)这样的形式
@Test
def map(): Unit ={
// 创建一个RDD,2个分区
val rdd1 = sc.parallelize(List(1, 4, 6, 7),2)
// 使用map()转换结构
val rdd2 = rdd1.map(x => {
if (x % 2 == 0)
("偶数", x)
else ("奇数", x)
})
// 遍历RDD并打印
rdd2.foreach(println)
}
运行结果:
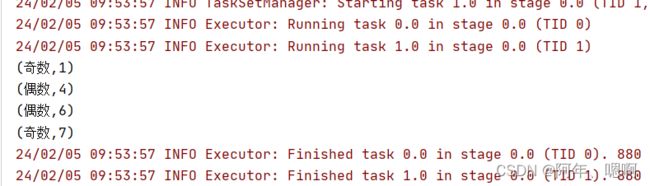
2. flatMap()
转化+压平操作,先对RDD中的每个元素进行转换,然后将转换的结果(数组、列表等)进行压平,返回一个新的RDD
操作的单位是RDD中的每个元素
例:将RDD中的元素进行切割,然后进行扁平化处理:
@Test
def flatMap(): Unit ={
val rdd1 = sc.parallelize(List("spark,scala", "python,java", "hadoop,java"),3)
val rdd2 = rdd1.flatMap(x=>{
// 切割后的每个元素都是一个数组,然后将多个数组进行扁平化处理
x.split(",")
})
// 将扁平化后的结果数组,收集到Driver端,转成List然后打印(不转换为List也能打印,只不过打印的是地址值,没有重写toString方法)
println(rdd2.collect().toList)
}
结果:

3. filter()
过滤数据,参数是一个返回值是Boolean类型的函数,将返回为true的元素保留
操作的单位是每一个元素
例:过滤出RDD中奇数元素
@Test
def filter(): Unit ={
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 7, 8))
val rdd2: RDD[Int] = rdd1.filter(x => {
// 过滤奇数
x % 2!=0
})
println(rdd2.collect().toList)
}
结果:

4. mapPartitions()
以分区为单位,执行map,它拿到的是一个分区内所有数据的迭代器对象(iterator类型的迭代器),你要遍历这个迭代器对象才能拿到这个分区里面的每个数据
这个的应用场景一般是读取数据库操作的时候用,可以减少数据库连接的创建、销毁次数,提高效率
普通的map是一个元素一个元素的操作,如果操作每个元素的时候都创建、销毁一次数据库连接,效率太差了,可以在每个分区创建一个连接,分区内的数据操作都用这一个连接,然后处理数据,并以批的形式执行操作这样效率比较高。
为啥不能将数据库的连接抽取出来在map函数外面创建,map里面使用连接?因为函数体外的代码是在Driver执行的(Driver负责执行main方法),函数体内处理数据的逻辑是在Executor中task去执行的task和Driver不在一台机器上,如果task想用Driver上的对象,就要Driver把这个对象通过网络传给task,网络传递肯定要序列化,执行sql的PrepareStatement对象是根本没有继承序列化接口,无法序列化,所以就会报错
例:RDD里的是学生id,要求从数据库中查出学生姓名和家庭住址并打印 - (3,test3,陕西)
map写法:
@Test
def map(): Unit = {
// 学生id
val rdd1 = sc.parallelize(List(1, 3, 5, 77, 6, 34))
// 对每个元素进行操作
val rdd2 = rdd1.map(id=>{
var connection: Connection = null
var statement:PreparedStatement = null
var name:String = null
var address:String = null
try{
// 在map()函数体里面创建连接对象,因为map()是针对每个元素进行操作的,
// 所以处理每个元素的时候都会进行连接的创建、销毁,效率低的要命
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test","root","123456")
statement = connection.prepareStatement("select id,name,address from student where id=?")
statement.setInt(1,id)
val resultSet = statement.executeQuery()
while (resultSet.next()) {
name = resultSet.getString("name")
address = resultSet.getString("address")
}
}catch {
case e:Exception => e.printStackTrace()
}finally {
if (connection != null) {
connection.close()
}
if (statement != null) {
statement.close()
}
}
(id,name,address)
})
println(rdd2.collect().toList)
}
mapPartitions写法:
@Test
def mapPartitions(): Unit = {
val rdd1 = sc.parallelize(List(1, 3, 5, 77, 6, 34))
// 每个分区进行操作
val rdd2 = rdd1.mapPartitions(idIterator => {
// 每个分区创建一个对象
var connection: Connection = null
var statement: PreparedStatement = null
// 将查到的数据缓存起来
val listBuffer: ListBuffer[(Int, String, String)] = ListBuffer[(Int, String, String)]()
try {
// 这个连接对象在每个分区只会创建一次
connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/test", "root", "123456")
statement = connection.prepareStatement("select id,name,address from student where id=?")
println(connection)
var name: String = null
var address: String = null
// idIterator.map(id=>{ 不能用map,因为用statement的时候连接已经被关闭了
// map()是转换算子,是延迟执行的,执行到这的时候还没有执行,而main方法已经把连接关闭了
idIterator.foreach(id => {
statement.setInt(1, id)
val resultSet = statement.executeQuery()
while (resultSet.next()) {
name = resultSet.getString("name")
address = resultSet.getString("address")
}
listBuffer += ((id, name, address))
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
if (connection != null) {
connection.close()
}
if (statement != null) {
statement.close()
}
}
listBuffer.toIterator
})
println(rdd2.collect().toList)
}
结果:

5. mapPartitionsWithIndex()
和mapPartitions()类似,只不过它可以取到分区号
例:rdd1设置为2个分区,打印分区号和每个分区内的数据
@Test
def mapPartitionsWithIndex(): Unit = {
val rdd1 = sc.parallelize(List(1, 3, 99, 56, 76, 7), 2)
val rdd2 = rdd1.mapPartitionsWithIndex((index, iterator) => {
println(s"分区号: ${index} === 区内数据:${iterator.toList}")
iterator
})
// 这个为啥输出空,是因为iterator迭代器只能调用一次,用过后里面就没有数据了 前面println的时候已经toList()用过了,所以后面返回的iterator本来就是个空的....
println(rdd2.collect().toList)
}
结果:
 这个为啥输出空,是因为iterator迭代器只能调用一次,用过后里面就没有数据了 前面println的时候已经toList()用过了,所以后面返回的iterator本来就是个空的…
这个为啥输出空,是因为iterator迭代器只能调用一次,用过后里面就没有数据了 前面println的时候已经toList()用过了,所以后面返回的iterator本来就是个空的…
6. groupBy()
通过传入函数的参数进行分组,分组后的value还是完整的整个元素
例:按照三元元组中第三个元素进行分组
@Test
def groupBy(): Unit = {
val rdd1 = sc.parallelize(List(("zhangsan", "man", "beijing"), ("lisi", "woman", "xian"), ("zhaoliu", "man", "xian")))
val rdd2 = rdd1.groupBy(_._3)
println(rdd2.collect().toList)
}
结果:

7. distinct()
对RDD中的元素进行去重,返回一个去重后的RDD,新的RDD默认的分区数与原RDD分区数相同,也可以指定新RDD的分区数
去重也可以用groupBy实现,直接按照元素分组,然后把元组中的第一个元素取出来就是去重后的结果
@Test
def distinct(): Unit = {
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 3, 2, 1, 1))
val rdd2 = rdd1.distinct()
/*
val rdd3 = rdd1.groupBy(w => w)
val rdd4 = rdd3.map(_._1)
*/
println(rdd2.collect().toList)
}
结果:

8. coalesce()
合并分区,不会走shuffle,分区数比原来的小才能生效,如果想要将分区变多,要开启第二个参数,它会走shuffle将分区变多
@Test
def coalesce(): Unit = {
// 将算子分区数设置为6个分区
val rdd1 = sc.parallelize(List(3, 454, 566, 7, 5657, 6734545, 4, 5), 6)
// 将分区合并为4个
// val rdd2 = rdd1.coalesce(4)
val rdd2 = rdd1.coalesce(8,true)
println(rdd2.collect().toList)
Thread.sleep(900000000)
}
结果:通过web页面查看,可以看到分区变为了8个

9. repartition()
重分区,它可以增大或者减少分区数,它底层调用的就是coalesce() 只不过把是否shuffle恒设置为了true
@Test
def repartition(): Unit = {
val rdd1 = sc.parallelize(List(2, 3, 4, 5, 6, 3, 3, 4, 5, 4), 4)
val rdd2 = rdd1.repartition(6)
println(s"rdd1分区数:${rdd1.getNumPartitions}\nrdd2分区数:${rdd2.getNumPartitions}")
}
结果:

10. sortBy()
排序,默认升序排序,他会走shuffle,它使用的分区器是RangePartitioner
@Test
def sortBy(): Unit = {
val rdd1 = sc.parallelize(List(1, 4, 5, 6, 7, 4, 2, 2, 5, 7, 8), 6)
// 第二个参数默认是true,也就是升序排序,降序的话就false
val rdd2 = rdd1.sortBy(x => x, false)
println(rdd2.collect().toList)
}
结果:

11. intersection()
交集,取两个RDD的相同元素,会有两次shuffle,因为要想取出交集,就要把相同的元素聚在一起才能知道有没有相同的元素,那就rdd1落盘,rdd2落盘,然后rdd3再把两个数据拉过来,所以有两次shuffle
@Test
def intersection(): Unit = {
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5), 6)
val rdd2 = sc.parallelize(List(4, 5, 6, 7, 8), 4)
val rdd3 = rdd1.intersection(rdd2)
println(rdd3.collect().toList)
Thread.sleep(10000000)
}
结果:

12.union()
并集,并集没有shuffle,他只是单纯的将两个RDD的数据放到一起,不关心有没有相同的数据。新RDD的分区数是原来两个RDD分区数之和
@Test
def union(): Unit = {
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5), 5)
val rdd2 = sc.parallelize(List(4, 5, 6, 7, 8), 4)
val rdd3 = rdd1.union(rdd2)
println(rdd3.collect().toList)
println(rdd3.getNumPartitions) // 并集的分区数是两个RDD集合的分区数之和
Thread.sleep(10000000)
}
结果:

13. subtract()
差集合,它会产生shuffle,取方法调用者的分区数,因为衍生RDD的分区数取决于依赖的第一个RDD的分区数
@Test
def subtract(): Unit = {
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5), 3)
val rdd2 = sc.parallelize(List(4, 5, 6, 7, 8), 4)
val rdd3 = rdd1.subtract(rdd2)
println(rdd3.collect().toList)
println(rdd3.getNumPartitions) //取方法调用者的分区数,衍生RDD的分区数取决于依赖的第一个RDD的分区数
Thread.sleep(10000000)
}
结果:

14. zip()
拉链,spark中的拉链要求两个RDD的分区数和数据条数都必须一样才能拉起来
@Test
def zip(): Unit = {
val rdd1 = sc.parallelize(List("hello", "spark", "xian", "beijign"), 5)
val rdd2 = sc.parallelize(List(1, 2, 3, 4), 5)
val rdd3 = rdd1.zip(rdd2)
println(rdd3.collect().toList)
}
结果:

15. partitionBy()
它的参数是一个分区器,按照给定的分区器重新分区。注意他这个要求操作的RDD必须是k-v键值对才能使用
@Test
def partitionBy(): Unit = {
val rdd1 = sc.parallelize(List(1, 3, 4, 5, 6, 7, 9), 4)
// 4个分区,集合长度为7 0: (0*7)/4 - (1*7)/4 => 0-1 => 1
// 1: (1*7)/4 - (2*7)/4 => 1-3 => 3 4
// 2: 3 - (3*7)/4 => 3-5 => 5 6
// 3: 5 - (4*7)/4 => 5-6 => 7 9
//
val rdd2 = rdd1.map(x => {
(x, null)
})
val rdd3 = rdd2.partitionBy(new HashPartitioner(5))
// 1%5 = 1 1在1号分区
// 3%5 = 3
//
// 0: 5
// 1: 1 6
// 2: 7
// 3: 3
// 4: 4 9
//
rdd3.mapPartitionsWithIndex((index, it) => {
println(s"${index} == ${it.toList}")
it
}).collect()
}
结果:

16. groupByKey()
根据key分组,返回的新的RDD是KV键值对,value是所有key相同的value值。会走shuffle
@Test
def groupByKey(): Unit = {
val rdd1 = sc.parallelize(List(("spark", 200), ("spark", 10), ("hadoop", 700), ("scala", 50), ("flink", 90000)), 3)
val rdd2 = rdd1.groupByKey(2)
// println(rdd2.getNumPartitions)
rdd2.mapPartitionsWithIndex((index, it) => {
println(s"groupByKey: ${index} == ${it.toList}")
it
}).collect()
// groupBy实现groupByKey的功能
val rdd3 = rdd1.groupBy(x => x._1)
val rdd4 = rdd3.map(y => (y._1, y._2.map(z => z._2)))
rdd4.mapPartitionsWithIndex((index,it)=>{
println(s"groupBy: ${index} == ${it.toList}")
it
}).collect()
}
结果:

17. reduceByKey()
参数是一个函数参数,函数有两个参数,分别表示当前value的聚合结果和待聚合的value值
@Test
def reduceByKey(): Unit ={
// wc.txt
// hello bigdata
// spark flink
// hbase hadoop spark flink
val rdd1 = sc.textFile("datas/wc.txt")
val rdd2 = rdd1.flatMap(line => line.split(" "))
val rdd3 = rdd2.map((_, 1))
// reduceByKey()的函数的两个参数的含义是当前value的聚合结果和待聚合的value
val rdd4 = rdd3.reduceByKey((agg, cur) => agg + cur)
println(rdd4.collect().toList)
}
结果:

18. aggregateByKey()()
聚合规约,他和ReduceByKey的区别是这个他的combiner逻辑和reduce的逻辑可以不一样,ReduceByKey的combiner逻辑和reduce逻辑一样
分区内combiner的逻辑和分区间reduce的逻辑不一样
aggregateByKey(a)(b,c) 柯里化形式
第一个参数列表a是默认值
第二个参数列表有两个参数:
b参数是combiner逻辑,他有两个参数,第一个参数是上次聚合的结果,第一次聚合时候的初始值=默认值
第二个参数是当前分组中等待聚合的value的值!!!
c参数是最终reduce的逻辑,他也有两个参数,第一个参数是该组上一次的聚合结果,第一次聚合的值=第一个value的值
第二个参数是当前分组中待聚合的value值
@Test
def aggregateByKey(): Unit ={
val rdd1 = sc.textFile("datas/stu_score.txt")
val rdd2 = rdd1.map(line => {
val arr = line.split(" ")
val name = arr(1)
val score = arr(2).toInt
(name, score)
})
// 默认值是(0,0)表示课程成绩为0 ,次数为0次
val rdd3 = rdd2.aggregateByKey((0, 0))(
// combiner的逻辑,agg是上次combiner的结果,刚开始的时候等于刚才设置的默认值;curValue是当前分组中等待聚合的value的值也就是score成绩
(agg, curValue) => {
// 将成绩和当前待聚合的成绩累加,次数标记+1
(agg._1 + curValue, agg._2 + 1)
},
// 这里就是reduce的逻辑,也就是combiner聚合后的结果最终的reduce
// agg是以前预聚合的结果,cur是当前的结果 ,需要进行成绩的累加和次数的累加
(agg, cur) => {
(agg._1 + cur._1, agg._2 + cur._2)
})
val rdd4 = rdd3.map(x => {
(x._1, x._2._1 / x._2._2)
})
println(rdd4.collect().toList)
}
结果:

19. sortByKey()
通过key排序,默认升序,这个可以用sortBy代替
@Test
def sortByKey(): Unit ={
val rdd1 = sc.parallelize(List(6, 12, 4, 6, 8, 2, 4, 89, 1))
val rdd2 = rdd1.map((_, null))
val rdd3 = rdd2.sortByKey(false)
val rdd4 = rdd2.sortBy(_._1, false)
println(rdd3.collect().toList)
println(rdd4.collect().toList)
}
结果:

20. mapValues()
对value进行操作,这个也比较局限,可以用map代替
@Test
def mapValues(): Unit ={
val rdd1 = sc.parallelize(List("xian" -> 10, "beijing" -> 40, "shanghai" -> 60, "qcln" -> 100))
val rdd2 = rdd1.mapValues(_ / 10)
val rdd2_1 = rdd1.map(x => {
(x._1, x._2 / 10)
})
println(rdd2.collect().toList)
println(rdd2_1.collect().toList)
}
结果:

21. join()
join连接,也分为内连接,左外,右外,全外
@Test
def join(): Unit ={
val rdd1 = sc.parallelize(List(("aa",11),("bb",12),("aa",13),("cc",14)))
val rdd2 = sc.parallelize(List(("aa",1.1),("cc",2.2),("dd",3.3),("cc",4.4)))
// todo inner join = 左表和右表能够连接的数据
val rdd3 = rdd1.join(rdd2)
println(rdd3.collect().toList)
// todo left join = 左表和右表能够连接的数据 + 左表不能连接的数据
val rdd4 = rdd1.leftOuterJoin(rdd2)
println(rdd4.collect().toList)
// todo right join = 左表和右表能够连接的数据 + 右表不能连接的数据
val rdd5 = rdd1.rightOuterJoin(rdd2)
println(rdd5.collect().toList)
// todo full join = 左表和右表能够连接的数据 + 左表和右表不能连接的数据
val rdd6 = rdd1.fullOuterJoin(rdd2)
println(rdd6.collect().toList)
}
22. cogroup()
这个相当于先对rdd1进行groupByKey然后与rdd2进行full outer join
@Test
def cogroup(): Unit ={
val rdd1 = sc.parallelize(List(("aa",11),("bb",12),("aa",13),("cc",14)))
val rdd2 = sc.parallelize(List(("aa",1.1),("cc",2.2),("dd",3.3),("cc",4.4)))
val rdd3 = rdd1.cogroup(rdd2)
println(rdd3.collect().toList)
}