【matlab】txt2xml +【python】delete part of xml
文章目录
- 1 Pascal Voc
- 2 分析数据的组织形式
- 3 数据集整理
- 3.1 JPEGImages and TxtLabels
- 3.2 Annotations
- 3.3 ImageSets
- 4 删除部分XML
声明:代码来源于KR,材料整理来源于KR+SWX,感谢!
由于目前多数网络要求输入的数据为Pascal Voc(xml格式)或者COCO(json格式),因此前期的数据集处理很重要。下面是我整理的将自己的数据转化为 Xml 格式的步骤和代码(Matlab)。
1 Pascal Voc
PASCAL VOC为图像识别和分类提供了一整套标准化的优秀的数据集,从2005年到2012年每年都会举行一场图像识别challenge。下载地址
以VOC2008为例,先看一下VOCdevkit的文件夹结构:

我们按照这样的树形结构建好文件夹,把VOC2007换成自己数据集的名字(通常直接将VOC2007里面的数据换成自己的),local下面也建一个自己数据集的名字的文件夹。SegmentationObject和SegmentationClass就不需要了。
我们检测任务所用的数据集只需要JPEGImages、Annotations、ImageSets文件夹。
2 分析数据的组织形式
由于数据集保密,就不放图了
图片和标注的文档(txt)一一对应,标注文档第一行为该图片的总细胞数(标注出的),其余为标注信息(class xmin ymin width height)。
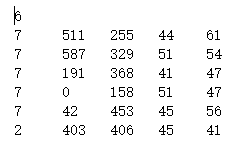
3 数据集整理
3.1 JPEGImages and TxtLabels
从所有的细胞集中选出带有标记文本的图片并将图片和txt文本按顺序重新命名,将重新命名后的图片放到JPEGImages文件夹中,重命名后的txt文本放到TxtLabels文件夹中待进一步处理,处理后的数据如下图。具体matlab代码见附件renameCells.m(原文件名中不能有空格!要对自己的数据名进行处理!)
将数据集的图片和标签放在 data目录下
renameCells.m
clc;
clear;
source_path='E:\data';
dst_path='E:\targetdata';
mkdir('E:\targetdata\TxtLabels');
mkdir('E:\targetdata\JPEGImages');
name_long=5; %图片名字的长度,如000123.jpg为6,最多9位,可修改
num_begin=1; %图像命名开始的数字如000123.jpg开始的话就是123
subdir = dir(source_path); %比目标文件数多两个
n=1;
for i = 1:length(subdir)
if ~strcmp(subdir(i).name ,'.') && ~strcmp(subdir(i).name,'..')
subsubdir = dir(fullfile(source_path,subdir(i).name,'*.txt'));
for j=1:length(subsubdir)
if ~strcmp(subsubdir(j).name ,'.') && ~strcmp(subsubdir(j).name,'..')
% img=imread([source_path,subdir(i).name,'/',subsubdir(j).name]);
%imshow(img);
strname=num2str(num_begin,'%05d');
oldname=subsubdir(j).name(1:end-4);
oldnameTxt = strcat(source_path,'/',subdir(i).name,'/',oldname,'.txt');
oldnameImagej = strcat(source_path,'/',subdir(i).name,'/',oldname,'.jpg');
oldnameImageJ= strcat(source_path,'/',subdir(i).name,'/',oldname,'.JPG');
newnameTxt=strcat(dst_path,'/TxtLabels/','h',strname,'.txt');
newnameImage=strcat(dst_path,'/JPEGImages/','h',strname,'.jpg');
%system(['rename ' [source_path,subdir(i).name,'/',oldname,'.txt'] ' ' [ newname,'.txt']]);
%eval(['!rename',oldname newname]);
%objFileImage = fullfile(source_path,subdir(i).name,oldname(2:end));
if exist(oldnameImagej ,'file')==2
movefile( oldnameTxt ,newnameTxt);
movefile( oldnameImagej ,newnameImage);
elseif exist(oldnameImageJ ,'file')==2
movefile( oldnameTxt ,newnameTxt);
movefile( oldnameImageJ ,newnameImage);
end
num_begin=num_begin+1;
fprintf('当前处理文件夹%s',subdir(i).name);
fprintf('已经处理%d张图片\n',n);
n=n+1;
%pause(0.1);%可以将暂停去掉
end
end
end
end
运行结束后
data目录下数据集文件夹中会余下出错的数据集
或者,用软件哈哈哈
【数据处理】文件批量改名
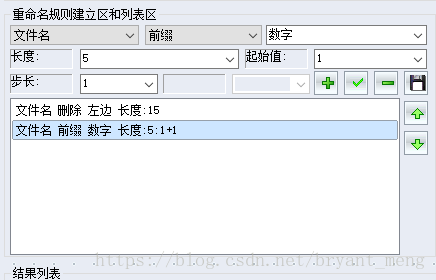
将图片和标注文本一一对应重命名,且过滤掉文件夹中不符合条件的文档和图片。例如有标注却没有图片或者有图片却没有标注
3.2 Annotations
从TxtLabels文件夹中读取与图片同名的txt标注信息,并将数字类别转换为文字类别(可选),然后写为xml文档。代码见changeClsLable.m、 writeanno.m、 writexml.m
效果
3
4 3188 2679 519 329
2 2888 2375 103 142
2 2661 2209 257 257
转化成

Note:xml 的 bounding box表示为 xmin,ymin,xmax,ymax
changeClsLable.m
function clsText = changeClsLabel(clsNum)
switch clsNum
case 0
clsText='CELL_NORMAL';
case 1
clsText = 'CELL_ASCUS';
case 2
clsText = 'CELL_ASCH';
case 3
clsText = 'CELL_LSIL';
case 4
clsText = 'CELL_HSIL';
case 5
clsText = 'CELL_SCC';
case 6
clsText = 'CELL_AGC';
case 7
clsText = 'CELL_AGCNOS';
case 8
clsText = 'CELL_AGCFN';
case 9
clsText = ' CELL_AIS';
case 10
clsText = 'CELL_VAGINALIS';
case 11
clsText = 'CELL_MONILIA';
case 12
clsText = 'CELL_DYSBACTERIOSIS';
case 13
clsText='CELL_HERPES';
case 14
clsText='CELL_ACTINOMYCES';
case 15
clsText='CELL_OTHERMALIGNANCIES';
otherwise
clcText='background';
end
writexml.m
function [ xml ] = writexml( fid,rec,depth )
%UNTITLED6 此处显示有关此函数的摘要
% 此处显示详细说明
fn=fieldnames(rec);
for i=1:length(fn)
f=rec.(fn{i});
if ~isempty(f)
if isstruct(f)
for j=1:length(f)
fprintf(fid,'%s',repmat(char(9),1,depth));
a=repmat(char(9),1,depth);
fprintf(fid,'<%s>\n',fn{i});
writexml(fid,rec.(fn{i})(j),depth+1);
fprintf(fid,'%s',repmat(char(9),1,depth));
fprintf(fid,'\n',fn{i});
end
else
if ~iscell(f)
f={f};
end
for j=1:length(f)
fprintf(fid,'%s',repmat(char(9),1,depth));
fprintf(fid,'<%s>',fn{i});
if ischar(f{j})
fprintf(fid,'%s',f{j});
elseif isnumeric(f{j})&&numel(f{j})==1
fprintf(fid,'%s',num2str(f{j}));
else
error('unsupported type');
end
fprintf(fid,'\n',fn{i});
end
end
end
end
writeanno.m
clear
clc
path_image='E:\targetdata\JPEGImages\';
path_label='E:\targetdata\TxtLabels\';%txt文件存放路径
mkdir('E:\targetdata\Annotations');
files_all=dir(path_image);
for i = 3:length(files_all)
fidin = fopen(strcat(path_label, files_all(i).name(1:end-4),'.txt'));
clear rec class classT x y width height;
path = ['E:\targetdata\Annotations\' files_all(i).name(1:end-4) '.xml'];
fidout=fopen(path,'w');
rec.annotation.folder = 'Cells';%数据集名
rec.annotation.filename = files_all(i).name(1:end-4);%图片名
rec.annotation.source.database = 'The Cells Database';%随便写
rec.annotation.source.annotation = 'The Cells Database';%随便写
rec.annotation.source.image = 'CellImage';%随便写
rec.annotation.source.flickrid = '0';%随便写
rec.annotation.owner.flickrid = 'I do not know';%随便写
rec.annotation.owner.name = 'I do not know';%随便写
img = imread(['E:\targetdata\JPEGImages\' files_all(i).name]);
rec.annotation.size.width = int2str(size(img,2));
rec.annotation.size.height = int2str(size(img,1));
rec.annotation.size.depth = int2str(size(img,3));
rec.annotation.segmented = '0';%不用于分割
cell_num=fgetl(fidin);
cell_num=strread(cell_num,'%d','delimiter',' ');
% disp(['The num of cell is ' num2str(cell_num(1)) ' in ' files_all(i) .name] );
disp(['The num of cell is ' num2str(cell_num) ' in ' files_all(i) .name] );
%object
j=1;
while feof(fidin)==0
tline=fgetl(fidin);
[class(j) ,x(j), y(j), width(j),height(j),non]=strread(tline,'%d %d %d %d %d%d','delimiter',' ');
classT{j}= changeClsLabel( class(j));
rec.annotation.object(j).name = classT{j};%类别名
%rec.annotation.object(j).name = class(j);%类别名
rec.annotation.object(j).pose = 'Unspecified';%不指定姿态
rec.annotation.object(j).truncated = '0';%没有被删节
rec.annotation.object(j).difficult = '0';%不是难以识别的目标
rec.annotation.object(j).bndbox.xmin = x(j);%坐标x1
rec.annotation.object(j).bndbox.ymin = y(j);%坐标y1
rec.annotation.object(j).bndbox.xmax = x(j)+width(j);%坐标x2
rec.annotation.object(j).bndbox.ymax = y(j)+height(j);%坐标y2
j=j+1;
end
writexml(fidout,rec,0);
fclose(fidin);
fclose(fidout);
end
3.3 ImageSets
ImageSets里只需要用到Main文件夹,而在Main中,主要用到4个文件:
- train.txt 是用来训练的图片文件的文件名列表
- trianval.txt是用来训练和验证的图片文件的文件名列表
- val.txt是用来验证的图片文件的文件名列表
- test.txt 是用来测试的图片文件的文件名列表
对数据进行随机分配成trainval.txt、train.txt、val.txt、test.txt四个文本。代码见writetxt.m
%
%该代码根据已生成的xml,制作VOC2007数据集中的trainval.txt;train.txt;test.txt和val.txt
%trainval占总数据集的50%,test占总数据集的50%;train占trainval的50%,val占trainval的50%;
%上面所占百分比可根据自己的数据集修改,如果数据集比较少,test和val可少一些
%注意修改下面四个值
xmlfilepath='E:\targetdata\Annotations\';
mkdir('E:\targetdata\ImageSets\');
mkdir('E:\targetdata\ImageSets\Main');
txtsavepath='E:\targetdata\ImageSets\Main\';
trainval_percent=0.8;%trainval占整个数据集的百分比,剩下部分就是test所占百分比
train_percent=0.8;%train占trainval的百分比,剩下部分就是val所占百分比
%
xmlfile=dir(xmlfilepath);
numOfxml=length(xmlfile)-2;%减去.和.. 总的数据集大小
trainval=sort(randperm(numOfxml,floor(numOfxml*trainval_percent)));
test=sort(setdiff(1:numOfxml,trainval));
trainvalsize=length(trainval);%trainval的大小
train=sort(trainval(randperm(trainvalsize,floor(trainvalsize*train_percent))));
val=sort(setdiff(trainval,train));
ftrainval=fopen([txtsavepath 'trainval.txt'],'w');
ftrain=fopen([txtsavepath 'train.txt'],'w');
fval=fopen([txtsavepath 'val.txt'],'w');
ftest=fopen([txtsavepath 'test.txt'],'w');
for i=1:numOfxml
if ismember(i,trainval)
fprintf(ftrainval,'%s\n',xmlfile(i+2).name(1:end-4));
if ismember(i,train)
fprintf(ftrain,'%s\n',xmlfile(i+2).name(1:end-4));
else
fprintf(fval,'%s\n',xmlfile(i+2).name(1:end-4));
end
else
fprintf(ftest,'%s\n',xmlfile(i+2).name(1:end-4));
end
end
fclose(ftrainval);
fclose(ftrain);
fclose(fval);
fclose(ftest);
4 删除部分XML
什么是XML?
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
原文件如下,我们想删除掉部分object

展开

计算面积的方法为(xmax-xmin)*(ymax-ymin)
由图可以计算出,三个目标的面积分别为,
47124
88290
59444
我们要保留面积大于60000的目标
话不多说,上代码
import xml.etree.ElementTree as ET
xml_name = '/root/userfolder/Experiment/TCT/t00004.xml'
annotat_tree = ET.parse(xml_name)
root = annotat_tree.getroot()
# 找到所有object
object_dect = root.findall('object')
#遍历object,筛选不符合条件的目标
for x in object_dect:
xmin = x.find("./bndbox/xmin") #左上
ymin = x.find("./bndbox/ymin")
xmax = x.find("./bndbox/xmax") #右下
ymax = x.find("./bndbox/ymax")
xmin = int(xmin.text) - 1
ymin = int(ymin.text) - 1
xmax = int(xmax.text)
ymax = int(ymax.text)
xlen = xmax - xmin
ylen = ymax - ymin
# 如果目标的面积小于60000,删除
#print(xlen*ylen)
if xlen*ylen<=60000:
root.remove(x)
##保存结果
annotat_tree.write('tt1.xml')
Output

OK,成功筛选了不符合条件的目标
上面用到了查找和删除操作,更多操作请看
Python XML操作