使用YCSB对HBase进行压测
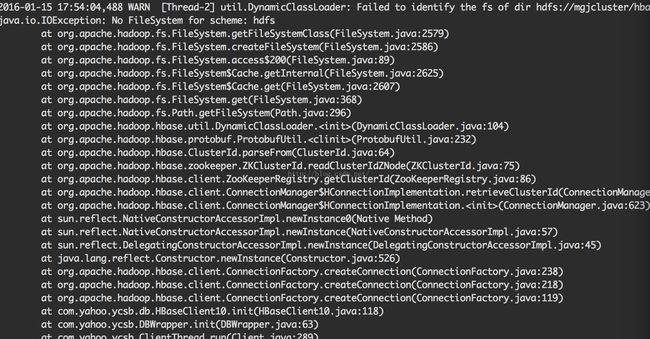
出现上述错误的原因在于放置于yscb-0.1.4/hbase-binding/conf目录下的hbase-site.xml文件,在该文件中,包含了如下的一条与底层hdfs集群相关的一条配置:
hbase.rootdir
hdfs://mgjcluster/hbase2
此外ycsb的workloads目录下保存了6种不同的workload类型,代表了不同的压测负载类型,详细的介绍列在下面:
workloada:混合了50%的读和50%的写;
workloadb:Read mostly workload,混合了95%的读和5%的写,该workload侧重于测试集群的读能力;
workloadc:Read only,100%只读
workloadd:Read latest workload,插入数据,接着就读取这些新插入的数据
workloade:Short ranges,短范围scan,不同于随机读,每个测试线程都会去scan一段数据
workloadf:Read-modiy-wirte,读改写,客户端读出一个记录,修改它并将被修改的记录返回
此外,YCSB还提供了一些参数,供用户指定,主要用到的如下参数
-target n 测试的目标吞吐;
-threads n 指定用于测试的客户端线程数;
-s 打印状态信息到终端;
一个完整的ycsb压测hbase的命令实例如下:
bin/ycsb load hbase10 -P workloads/workloadb -threads 30 -p table=usertable -p columnfamily=family -p recordcount=100000如上压测的hbase表名是usertable,列族名是family,用于压测的客户端线程数是30个,负载类型workloadb,压测数据100000例。压测输出的结果实例如下:
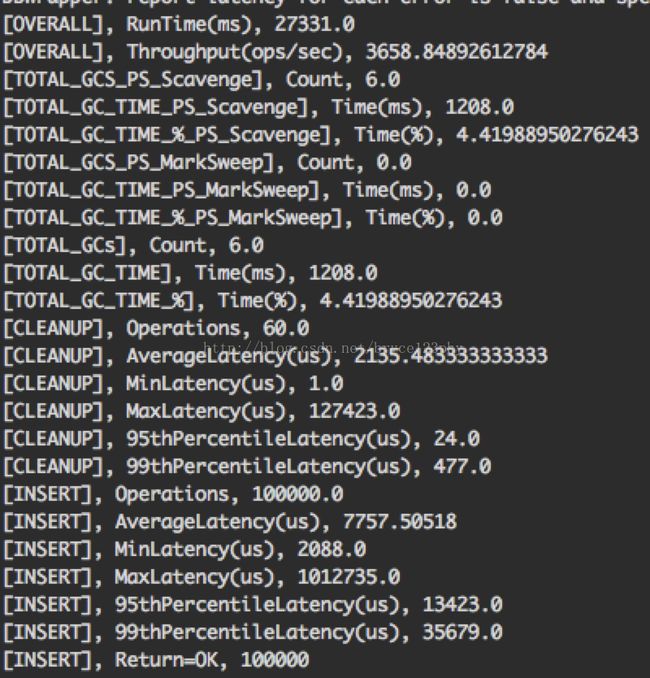
上述的输出结果中主要包括了处理请求的总时间(Runtime),请求的吞吐量(Throughput),表示每秒钟可处理的请求个数,平均延时(AverageLatency),单位是us,95%的操作延时和99%的操作延时,单位都是us。此外还包括了GC相关的一些metrics。
关于前面的CLEANUP和INSERT,这里做个说明,insert代表的是用于压测的客户端发往集群的请求,所以insert标示的metrics代表了对集群性能的真实度量,而cleanup表示的是客户端的一些现场清理工作,比如每个客户端线程在读写完hbase之后,都需要断开到zk的连接等等,所以CLEANUP标示的metrics不需要过多关注。
参考资料:
https://github.com/brianfrankcooper/YCSB/issues/548
https://github.com/brianfrankcooper/YCSB/wiki/Core-Workloads