Keras学习笔记(一)Embedding层
1.Embedding层的作用
以NLP词嵌入举例,Embedding层就是为了训练一个词嵌入矩阵出来,然后可以获得任意的一个词的词向量。
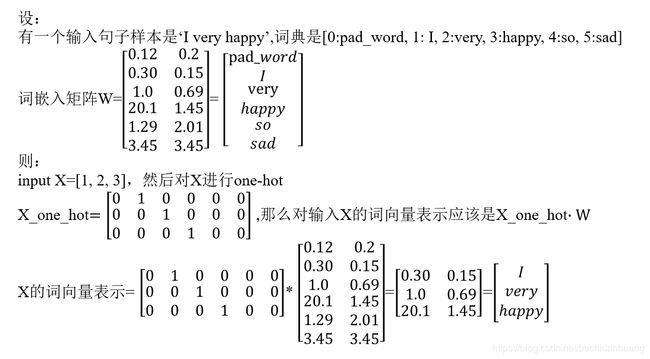
也就是说对于像一个句子样本X=[1,2,3] (1,2,3表示单词在词典中的索引)这样的输入可以先对它one-hot然后乘上词嵌入矩阵就可得到这个句子的词嵌入向量表示。要想得到好的词向量,我们需要训练的就是这个矩阵W(shape=(input_dim,output_dim))。Embedding层的作用就是训练这个矩阵W并进行词的嵌入为每一个词分配与它对应的词向量。这个词嵌入矩阵W可以先随机初始化,然后根据下游任务训练获得,也可以使用预训练的词嵌入矩阵来初始化它(keras中用weights来为layer初始化任意权重),然后再训练,也可以直接用预训练的词嵌入矩阵来初始化它并冻结它,不让它变化,不让它可训练。(keras中用trainable=False)
2.参数解释
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer=‘uniform’, embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)

主要参数说明:
· input_dim:int,整个词典的大小。例如nlp中唯一单词的个数,当然如果还有一个用于padding的单词那就应加1。
· output_dim:int,嵌入维度。例如nlp中设计的词向量的维度。
· embeddings_initializer:嵌入矩阵的初始化器。
· mask_zero:如果设置为True那么padding的0将不参与计算,默认是False。这个参数可用于解决非等长序列padding噪声到原始数据的问题。
· input_length:序列长度。每个样本都有相同的长度。
实际上还有其他的关键字参数:我们看下Embedding初始化方法的定义(from embeddings.py)
@interfaces.legacy_embedding_support
def __init__(self, input_dim, output_dim,
embeddings_initializer='uniform',
embeddings_regularizer=None,
activity_regularizer=None,
embeddings_constraint=None,
mask_zero=False,
input_length=None,
**kwargs):
if 'input_shape' not in kwargs:
if input_length:
kwargs['input_shape'] = (input_length,)
else:
kwargs['input_shape'] = (None,)
super(Embedding, self).__init__(**kwargs)
self.input_dim = input_dim
self.output_dim = output_dim
self.embeddings_initializer = initializers.get(embeddings_initializer)
self.embeddings_regularizer = regularizers.get(embeddings_regularizer)
self.activity_regularizer = regularizers.get(activity_regularizer)
self.embeddings_constraint = constraints.get(embeddings_constraint)
self.mask_zero = mask_zero
self.supports_masking = mask_zero
self.input_length = input_length
它其实除了文档中描述的那些参数之外还有个**kwargs参数,这个参数其实是每个自定义layer都应当有的,并且它被这样调用: super(Embedding, self)._ init _(**kwargs),即在Embedding的初始化中不仅初始化了它自定义的部分还初始化了Embedding父类Layer类的初始化函数。Layer类初始化方法代码是这样的:(from base_layer.py)
def __init__(self, **kwargs):
self.input_spec = None
self.supports_masking = False
self.stateful = False
# These properties will be set upon call of self.build()
self._trainable_weights = []
self._non_trainable_weights = []
self._losses = []
self._updates = []
self._per_input_losses = {}
self._per_input_updates = {}
self._built = False
# These lists will be filled via successive calls
# to self._add_inbound_node().
self._inbound_nodes = []
self._outbound_nodes = []
# These properties should be set by the user via keyword arguments.
# note that 'dtype', 'input_shape' and 'batch_input_shape'
# are only applicable to input layers: do not pass these keywords
# to non-input layers.
allowed_kwargs = {'input_shape',
'batch_input_shape',
'batch_size',
'dtype',
'name',
'trainable',
'weights',
'input_dtype', # legacy
}
for kwarg in kwargs:
if kwarg not in allowed_kwargs:
raise TypeError('Keyword argument not understood:', kwarg)
name = kwargs.get('name')
if not name:
prefix = self.__class__.__name__
name = _to_snake_case(prefix) + '_' + str(K.get_uid(prefix))
self.name = name
self.trainable = kwargs.get('trainable', True)
if 'input_shape' in kwargs or 'batch_input_shape' in kwargs:
# In this case we will later create an input layer
# to insert before the current layer
if 'batch_input_shape' in kwargs:
batch_input_shape = tuple(kwargs['batch_input_shape'])
elif 'input_shape' in kwargs:
if 'batch_size' in kwargs:
batch_size = kwargs['batch_size']
else:
batch_size = None
batch_input_shape = (
batch_size,) + tuple(kwargs['input_shape'])
self.batch_input_shape = batch_input_shape
# Set dtype.
dtype = kwargs.get('dtype')
if dtype is None:
dtype = kwargs.get('input_dtype')
if dtype is None:
dtype = K.floatx()
self.dtype = dtype
if 'weights' in kwargs:
self._initial_weights = kwargs['weights']
else:
self._initial_weights = None
也就是说Layer类的初始化方法其实就是将被允许的**kwargs进行了初始化。被允许的关键字参数有:
allowed_kwargs = {‘input_shape’, # 输入shape,如果某层是model的第一层该变量应该被指定
‘batch_input_shape’,
‘batch_size’,
‘dtype’,
‘name’,# 层的名字,自定义层时不需自定义初始化name,只需调Layer这个父类的初始化方法即可,它会为Layer实例绑定name属性
‘trainable’, # 是否可训练。这个值将覆盖Layer类中add_weight方法的trainable参数的值
‘weights’,# 为该层权重指定任意自定义的初始值。如果embeddings_initializer被给定了,那么weights将覆盖它。weights的自定义性更广。
‘input_dtype’, # legacy
}
3.调用举例
import numpy as np
from keras.models import Sequential
from keras.layers import Embedding
input_array=np.array([[1,2,3],[2,1,0],[1,0,0],[3,2,1]]) # 4个样本
g_word_embedding_matrix = np.eye(6,2)
model = Sequential()
model.add(Embedding(6,
2,
embeddings_initializer='uniform',
weights=[g_word_embedding_matrix], # weights是**kwargs中的参数,weights将覆盖embeddings_initializer,weights的自定义性更广
input_length=3,
trainable=False, # trainable是**kwargs中的参数,trainable将控制该层参数是否可训练,它优先级高于Layer中add_weight的trainable
name='embedding')) # name是**kwargs中的参数
model.compile('rmsprop', 'mse')
model.summary()
output_array = model.predict(input_array)
print(output_array.shape)
layer = model.get_layer('embedding')
print(layer.get_config())
print(layer.get_weights())
结果:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 3, 2) 12 # 12是指所有参数不管是否可训练
=================================================================
Total params: 12
Trainable params: 0
Non-trainable params: 12 # 代码中指定trainalbe=False,可验证12是不可训练的
_________________________________________________________________
(4, 3, 2)
{'name': 'embedding', 'trainable': False, 'batch_input_shape': (None, 3), 'dtype': 'float32', 'input_dim': 6, 'output_dim': 2, 'embeddings_initializer': {'class_name': 'RandomUniform', 'config': {'minval': -0.05, 'maxval': 0.05, 'seed': None}}, 'embeddings_regularizer': None, 'activity_regularizer': None, 'embeddings_constraint': None, 'mask_zero': False, 'input_length': 3}
[array([[1., 0.],
[0., 1.],
[0., 0.],
[0., 0.],
[0., 0.],
[0., 0.]], dtype=float32)] # 可见weights覆盖了embeddings_initializer
参考:Keras Embedding层文档